Coursera | Andrew Ng (03-week1-1.5)—训练_开发_测试集划分
该系列仅在原课程基础上部分知识点添加个人学习笔记,或相关推导补充等。如有错误,还请批评指教。在学习了 Andrew Ng 课程的基础上,为了更方便的查阅复习,将其整理成文字。因本人一直在学习英语,所以该系列以英文为主,同时也建议读者以英文为主,中文辅助,以便后期进阶时,为学习相关领域的学术论文做铺垫。- ZJ
Coursera 课程 |deeplearning.ai |网易云课堂
转载请注明作者和出处:ZJ 微信公众号-「SelfImprovementLab」
知乎:https://zhuanlan.zhihu.com/c_147249273
CSDN:http://blog.csdn.net/junjun_zhao/article/details/79147571
1.5 Train_dev_test distributions (训练开发测试集划分)
(字幕来源:网易云课堂)

The way you set up your training dev, or development sets and test sets can have a huge impact on how rapidly you or your team can make progress on building machine learning application.The same teams, even teams in very large companies,set up these data sets in ways that really slows down,rather than speeds up, the progress of the team.Let’s take a look at how you can set up these data sets to maximize your team’s efficiency.In this video, I want to focus on how you set up your dev and test sets.So, that dev set is also called the development set,or sometimes called the hold out cross validation set.And, workflow in machine learning is that you try a lot of ideas,train up different models on the training set,and then use the dev set to evaluate the different ideas and pick one.And, keep iterating to improve dev set performance until, finally,you have one cost that you’re happy with that you then evaluate on your test set.Now, let’s say, by way of example,that you’re building a cat classifier,and you are operating in these regions: in the U.S,U.K, other European countries, South America,India, China, other Asian countries, and Australia.
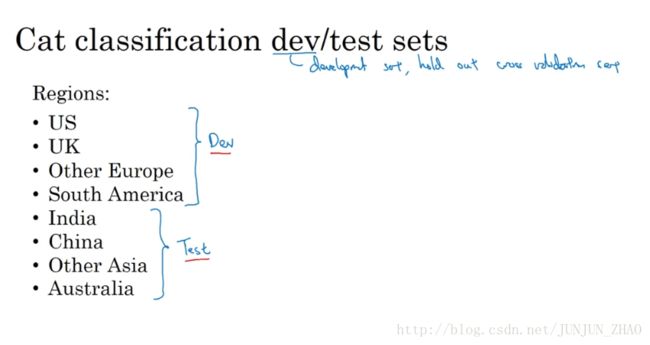
设立训练集 开发集和测试集的方式,大大影响了你或者你的团队,在建立机器学习应用方面取得进展的速度,同样的团队 即使是大公司里的团队,在设立这些数据集的方式,真的会让团队的进展变慢而不是加快,我们看看应该如何设立这些数据集,让你的团队效率最大化。在这个视频中 我想集中讨论如何设立开发集和测试集,dev 集也叫做开发集,有时称为保留交叉验证集,然后 机器学习中的工作流程是,你尝试很多思路用训练集训练不同的模型,然后使用开发集来评估不同的思路 然后选择一个,然后不断迭代去改善开发集的性能 直到最后,你可以得到一个令你满意的成本 然后你再用测试集去评估。现在 举个例子,你要开发一个猫分类器,然后你在这些区域里运营 美国,英国 其他欧洲国家 南美洲,印度 中国 其他亚洲国家和澳大利亚。
So, how do you set up your dev set and your test set?Well, one way you could do so is to pick four of these regions.I’m going to use these four but it could be four randomly chosen regions.And say, that data from these four regions will go into the dev set.And, the other four regions, I’m going to use these four,could be randomly chosen four as well,that those will go into the test set.It turns out, this is a very bad idea because in this example,your dev and test sets come from different distributions.I would, instead, recommend that you find a way to make your dev and test sets come from the same distribution.So, here’s what I mean.One picture to keep in mind is that, I think,setting up your dev set, plus,your single real number evaluation metric,that’s like placing a target and telling your team where you think is the bull’s eye you want to aim at.Because, what happen once you’ve established that dev set and the metric is that,the team can iterate very quickly, try different ideas, run experiments and very quickly use the dev set and the metric to evaluate classifiers and try to pick the best one.

那么你应该如何设立开发集和测试集呢?其中一种做法是 你可以选择其中 4 个区域,我打算使用这四个 但也可以是随机选的区域,然后说 来自这四个区域的数据构成开发集,然后其他四个区域 我打算用这四个,也可以随机选择 4 个,这些数据构成测试集,事实证明 这个想法非常糟糕 因为这个例子中,你的开发集和测试集来自不同的分布,我建议你们不要这样 而是,让你的开发集和测试集来自同一分布,我的意思是这样,你们要记住 我想,就是设立你的开发集 加上一个,单实数评估指标,这就是像是定下目标 然后告诉你的团队,那就是你要瞄准的靶心,因为你一旦建立了这样的开发集和指标,团队就可以快速迭代 尝试不同的想法 跑实验,可以很快地使用开发集和指标,去评估不同分类器 然后尝试选出最好的那个。
So, machine learning teams are often very good at shooting different arrows into targets and iterating to get closer and closer to hitting the bulls eye.So, doing well on your metric on your dev sets.And, the problem with how we’ve set up the dev and test setsin the example on the left is that,your team might spend months iterating to do well on the dev set only to realize that,when you finally go to test them on the test set,that data from these four countries or these four regions at the bottom,might be very different than the regions in your dev set.So, you might have a nasty surprise and realize that,all the months of work you spent optimizing to the dev set is not giving you good performance on the test set.So, having dev and test sets from different distributions is like setting a target,having your team spend months trying to aim closer and closer to bull’s eye,only to realize after months of work that,you’ll say, “Oh wait, to test it,I’m going to move target over here.”And, the team might say, “Well,why did you make us spend months optimizing for a different bull’s eye when suddenly,you can move the bull’s eye to a different location somewhere else?”
所以 机器学习团队一般都很擅长使用不同方法去逼近目标,然后不断迭代 不断逼近靶心,所以 针对开发集上的指标优化,然后在左边的例子中 设立开发集和测试集时,存在一个问题,你的团队可能会花上几个月时间在开发集上迭代优化 结果发现,当你们最终在测试集上测试系统时,来自这四个国家或者说下面这四个地区的数据,和开发集里的数据可能差异很大,所以你可能会收获”意外惊喜” 并发现,花了那么多个月的时间去针对开发集优化,在测试集上的表现却不佳,所以 如果你的开发集和测试集来自不同的分布 就像你设了一个目标,让你的团队花几个月尝试逼近靶心,结果在几个月工作之后发现,你说 “等等 测试的时候”,”我要把目标移到这里”,然后团队可能会说 “好吧,为什么你让我们花那么多个月的时间去逼近那个靶心 然后突然间,你可以把靶心移到不同的位置?”。
So, to avoid this,what I recommend instead is that,you take all this data, randomly shuffled data into the dev and test set.So that, both the dev and test sets have data from all eight regions and that the dev and test sets really come from the same distribution,which is the distribution of all of your data mixed together.

所以 为了避免这种情况,我建议的是,你将所有数据随机洗牌 放入开发集和测试集,所以开发集和测试集都有来自八个地区的数据,并且开发集和测试集都来自同一分布,这分布就是你的所有数据混在一起。
Here’s another example. This is a actually true story but with some details changed.So, I know a machine learning team that actually spent several months optimizing on a dev set which was comprised of loan approvals for medium income zip codes.So, the specific machine learning problem was,”Given an input x about a loan application,can you predict y and which is,whether or not, they’ll repay the loan?”So, this helps you decide whether or not to approve a loan.And so, the dev set came from loan applications.They came from medium income zip codes.Zip codes is what we call postal codes in the United States.But, after working on this for a few months, the team then,suddenly decided to test this ondata from low income zip codes or low income postal codes.And, of course, the distributional data for medium income and low income zip codes is very different.And, the classifier, that they spend so much time optimizing in the former case,just didn’t work well at all on the latter case.And so, this particular team actually wasted about three months of time and had to go back and really re-do a lot of work.And, what happened here was,the team spent three months aiming for one target,and then, after three months,the manager asked, “Oh, how are you doing on hitting this other target?”This is a totally different location.And, it just was a very frustrating experience for the team.

这里有另一个例子 这是个,真实的故事 但有一些细节变了,所以我知道有一个机器学习团队,花了好几个月在开发集上优化,开发集里面有中等收入邮政编码的贷款审批数据,那么具体的机器学习问题是,“输入 x 为贷款申请,你是否可以预测 输出 y 是,他们有没有还贷能力?所以这系统能帮助银行判断是否批准贷款,所以开发集来自贷款申请,这些贷款申请来自中等收入邮政编码,zip code就是美国的邮政编码,但是在这上面训练了几个月之后,团队突然决定要在,低收入邮政编码数据上测试一下,当然了 这个分布数据里面,中等收入和低收入邮政编码数据是很不一样的,而且他们花了大量时间针对前面那组数据优化分类器,导致系统在后面那组数据中效果很差,所以这个特定团队实际上浪费了 3 个月的时间,不得不退回去 重新做很多工作,这里实际发生的事情是,这个团队花了三个月瞄准一个目标,三个月之后,经理突然问 “你们试试瞄准那个目标如何”,这新目标位置完全不同,所以这件事对于这个团队来说非常崩溃。
So, what I recommand for setting up a dev set and test set is choose a dev set and test set to reflect data you expect to get in future,and consider important to do well on.And, in particular, the dev set and the test set here,should come from the same distribution.So, whatever type of data you expect to get in the future,and once you do well on,try to get data that looks like that.And, whatever that data is,put it into both your dev set and your test set.Because that way, you’re putting the target where you actually want to hit and you’re having the team iterate very efficiently to hitting that same target,hopefully, the same targets as well.Since we haven’t talked yet about how to set up a training set,we’ll talk about the training set in a later video.But, the important take away from this video is that,setting up the dev set,as well as the evaluation metric is really defining what target you want to aim at.And hopefully, by setting the dev set and the test set to the same distribution,you’re really aiming at whatever target you hope your machine learning team will hit.The way you choose your training set will affect how well you can actually hit that target.But, we can talk about that separately in a later video.

所以我建议你们在设立开发集和测试集时,要选择这样的开发集和测试集 能够反映你未来会得到的数据,认为很重要的数据 必须得到好结果的数据,特别是 这里的开发集和测试集,可能来自同一个分布,所以不管你未来会得到什么样的数据,一旦你的算法效果不错,要尝试收集类似的数据,而且 不管那些数据是什么,都要随机分配到开发集和测试集上,因为这样 你才能将瞄准想要的目标,让你的团队高效迭代,来逼近同一个目标,希望最好是同一个目标,我们还没提到如何设立训练集,我们会在之后的视频里谈谈如何设立训练集,但这个视频的重点在于,设立开发集,以及评估指标,真的就定义了你要瞄准的目标,我们希望通过在同一分布中设立开发集和测试集,你就可以瞄准你所希望的 机器学习团队瞄准的目标,而设立训练集的方式,则会影响你逼近那个目标有多快,但我们可以在另一个讲座里提到。
So, I know some machine learning teams that could literally have saved themselves months of work could they follow the guidelines in this video.So, I hope these guidelines will help you, too.Next, it turns out, that the size of your dev and test sets,how to choose the size of them,is also changing the era of deep learning.Let’s talk about that in the next video.
我知道有一些机器学习团队,他们如果能遵循这个方针 就可以省下几个月的工作,所以我希望这些方针也能帮到你们,接下来 实际上 你的开发集和测试集的规模,如何选择它们的大小,在深度学习时代也在变化,我们会在下一个视频里提到这些内容。
重点总结:
训练、开发、测试集
训练、开发、测试集选择设置的一些规则和意见:
- 训练、开发、测试集的设置会对产品带来非常大的影响;
- 在选择开发集和测试集时要使二者来自同一分布,且从所有数据中随机选取;
- 所选择的开发集和测试集中的数据,要与未来想要或者能够得到的数据类似,即模型数据和未来数据要具有相似性;
- 设置的测试集只要足够大,使其能够在过拟合的系统中给出高方差的结果就可以,也许 10000 左右的数目足够;
- 设置开发集只要足够使其能够检测不同算法、不同模型之间的优劣差异就可以,百万大数据中 1% 的大小就足够;
参考文献:
[1]. 大树先生.吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(3-1)– 机器学习策略(1)
PS: 欢迎扫码关注公众号:「SelfImprovementLab」!专注「深度学习」,「机器学习」,「人工智能」。以及 「早起」,「阅读」,「运动」,「英语 」「其他」不定期建群 打卡互助活动。
