城市类知识图谱的搭建(elasticsearch+Django)(上)
这里写一篇博文来整理一下如何构建城市类的知识图谱,废话不多说,一般来说在知识图谱中比较重要的技术点就是实体识别和关系抽取。就比如在城市的类别中,一个城市有它的一些特性,比如说北京,如下图所示:
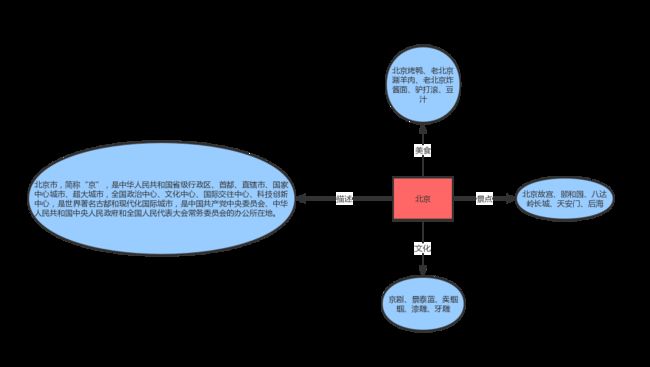
中间表示是城市北京,蓝色圆框中间表示一些内容,而连接线表示北京与这些内容的一些关系,我们在做知识图谱的时候就要建立这些实体之间的关系。
首先第一步是数据的整理,我们需要从网上爬取城市的数据,这里比较好的数据是城市百科,我们可以从这个网站上爬取中国所有地级市的景点、美食、文化和人物信息。以北京微例子,如下图所示:
红色方框框住的部分就是我们要爬取的部分,甚至我们可以建立更完整的城市信息,把人物、历史、自然、建设和学校的信息一起爬取下来,建立更完整的知识图谱。然后城市的简介是爬取百度百科的第一段简介。如下图所示:

好了,知道如何获取数据以后,我们看看完整的数据是长什么样子的吧。在这里我只用了最基本的简介、景点、美食和文化。下面就是我们的数据了,长这个样子:

总的数据,去掉一些空的数据和不完整的数据,一共有365个地级市,分别是城市名city,景点scenery,美食food,文化culture和简介describe,不同的特征选项之间是用英文的逗号“,”隔开的,特征内部是用中文的逗号“,”隔开的,我们在待会提取数据的时候可以通过 split 方法将其提取出来。有了这些数据之后,我们就可以将数据导入 elasticsearch 数据库了,朋友们可以导到您本机的 elasticsearch 上,下面是批量导入数据到 elasticsearch 上的代码:
#!/usr/bin/python
# coding=utf-8
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulk
# set mapping
def set_mapping(es, index_name="城市信息", doc_type_name="FAQ"):
mapping = {
# 导入的数据的city, scenery, foods, culture 和 describe
# ik_smart 表示索引和查询搜索分词的时候按照最粗的粒度进行分词操作
"properties": {
"city": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
},
"scenery": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
},
"foods": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
},
"cultures": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
},
"describe": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
},
}
}
es.indices.delete(index=index_name, ignore=[400, 404])
es.indices.create(index=index_name, ignore=True)
es.indices.put_mapping(index=index_name, doc_type=doc_type_name, body=mapping)
def set_date(elasticsearch, index_name="城市信息", doc_type_name="FAQ"):
actions = []
i = 1
with open(u'city.txt', 'r', encoding="utf-8") as cityfile:
for row in cityfile:
try:
# 逐行读取数据,然后通过split(',')获取城市的各个数据信息
row = row.strip().split(',')
action = {
"_index": index_name,
"_type": doc_type_name,
"_id": i,
"_source": {
"city": row[1],
"scenery": row[2],
"foods": row[3],
"cultures": row[4],
"describe": row[5],
}
}
i = i + 1
actions.append(action)
except Exception as e:
print(row, e)
success, _ = bulk(elasticsearch, actions, index=index_name, raise_on_error=True)
print('Performed %d actions' % success)
if __name__ == '__main__':
# 您要导入的服务器IP,端口号默认是9200
es = Elasticsearch(hosts=["192.168.1.118:9200"], timeout=5000)
set_mapping(es)
set_date(es)
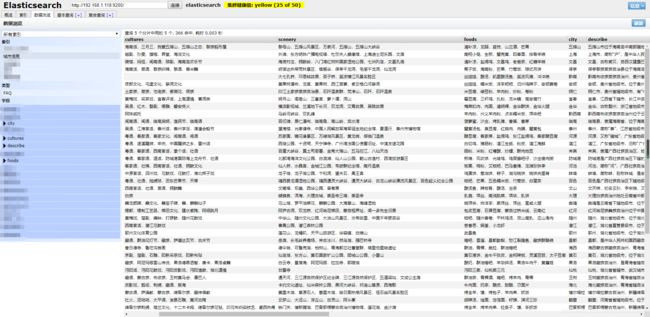
导入数据成功之后,我们可以看到服务器上的数据长得这个样子:
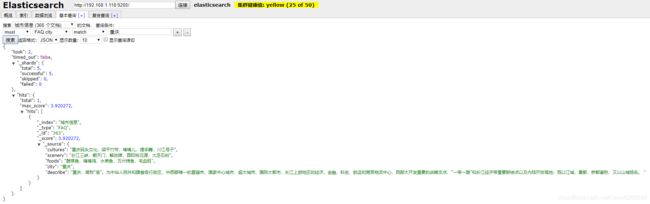
之所以我们选择使用 elasticsearch 的原因是因为它在数据关键词搜索上表现非常棒,举个例子,比如我搜一个重庆,在 elasticsearch 里面就可以将重庆所有的信息展示出来,如图所示:
甚至我随便搜一个臭豆腐,elasticsearch 就能够把所有美食包含有臭豆腐的城市给找出来,如图所示:

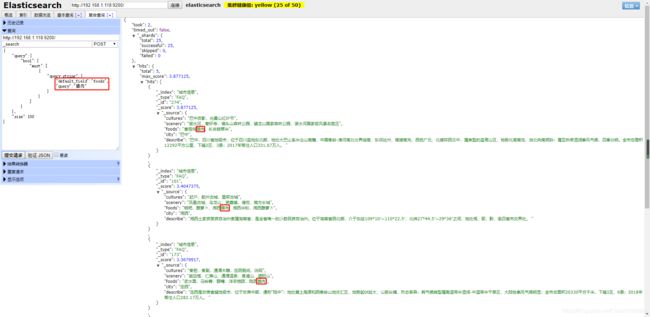
有这么强大的搜索工程,我们在后续进行搜索的时候就非常方便了。顺便提一句,在后续搜索的时候我们需要用到搜索语句,是json 的格式,比如在搜所美食的时候,就要修改 “default_field” 和 “query” 这两个字段的内容,如图所示:
除了这些数据以外,因为在后续我们会进行实体的识别,所以我们这里要把所有的 city、culture、food 和 scenery 提取出来,并打上相应的标签,命名实体和标签中间是空格,得到city.txt、culture.txt、food.txt 和 scene.txt如下图所示:
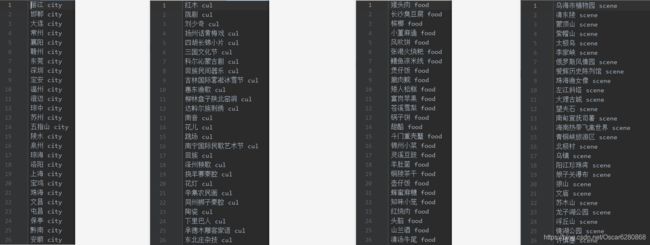
这个过程非常简单,就把爬取下来的数据进行 set 去重,然后分别打上标签就好了,后续我们会用到这些命名实体的。好了,到目前为止,数据方面的处理就完成了,接下来我们需要去进行语义的解析,来判断 query 想问的东西。代码详见 GitHub 。