对FCN的改进,关于dilaition和DUC
Understanding Convolution for Semantic Segmentation
http://www.cnblogs.com/xiangs/p/9780895.html
https://blog.csdn.net/qq_21997625/ar
https://mp.csdn.net/postedit
https://www.zhihu.com/question/54149221/answer/323880412
https://github.com/fregu856/deeplabv3/tree/master/visualization
图 4:Dense Pose 纹理转换 (texture transfer) 的实验结果。该任务的目标是,将输入的视频图像中所有人的身体表面纹理,转换成目标纹理。图中第 1 行为目标纹理 1 和纹理 2。第 2、3 行从左至右依次为,输入图像,转换为纹理 1 的图像,以及转换为纹理 2 的图像。
在 ECCV 2018 上,论文 [1] 的三名作者发表了 Dense Pose 的一个后续应用,即「密集姿态转移」(dense pose transfer,
HDC(hybrid dilated convolution)代替双线性。cat+conv代替+
1.级联?res+dilation+F.upsample(conv(GAP))?
2.shuffleV3+reset+desnet+cat+conv
3. 从 DeepLabv3 开始去掉 CRFs,可以pass了
4.有个问题是,res+rpn后就接pooler了,pooler过程有选层操作,那么如果选层不够精细,可能后面分支也不够好,现在对各个分支的更改都是对pooler之后的某一RoI特征进行进一步提取,其实这个RoI已经是认定为“所谓的目标”,那么对目标提来踢去确实可以是关节点“优化”。但是,是不是说或可以对pooler之前的四层都给优化一下呢?那么跟着,rpn也是会优化的 。
还有分配公式这里会不会有点问题?
res是1/4;1/8;1/16;1/32 有没有办法这里加个小模块?并且是same。1,2,3?
针对output_stride=8的情况,rate=2×(6,12,18).并行处理后的特征图在集中通过256个1×1卷积(BN),最后就是输出了,依旧是1×1卷积。

主要提出DUC(dense upsampling convolution)和HDC(hybrid dilated convolution),其中DUC相当于用通道数来弥补卷积/池化等操作导致的尺寸的损失,HDC为了消除在连续使用dilation convolution时容易出现的gridding effect。
DUC是可以学习的,它能够捕获和恢复细节的信息,比如,如果一个网络的下采样倍数为16,但是一个物体的长或者宽小于16个像素,下采样之后双线性插值就很难恢复这个物体了。这样最终的label map就会丢失细节信息了。DUC的输出和输入分辨率是一致的,而且可以集成到FCN中,实现端到端的分割。
2. 解码部分的问题
大部分语义分割模型主要采用双线性插值上采样来获得输出label map。但是双线性插值不是可学习的而且会丢失信息。本文提出了密集上采样卷积(DUC),来一次性恢复label map的全部分辨率,通过学习一系列上采样滤波器来对下采样的feature map进行恢复到要求的分辨率。
本文首先提出了 dense upsampling convolution,可以捕获和解码更详细的信息,这些细节信息是双线性插值不能获取的;然后提出了一个 dense upsampling convolution框架,可以增加感受视野扩大全局信息,并且解决了网格问题,这是由于标准的空洞卷积造成的。
不过光理解卷积和空洞卷积的工作原理还是远远不够的,要充分理解这个概念我们得重新审视卷积本身,并去了解他背后的设计直觉。以下主要讨论 dilated convolution 在语义分割 (semantic segmentation) 的应用。
一、重新思考卷积: Rethinking Convolution
在赢得其中一届ImageNet比赛里VGG网络的文章中,他最大的贡献并不是VGG网络本身,而是他对于卷积叠加的一个巧妙观察。
This (stack of three 3 × 3 conv layers) can be seen as imposing a regularisation on the 7 × 7 conv. filters, forcing them to have a decomposition through the 3 × 3 filters (with non-linearity injected in between).
意思是 7 x 7 的卷积层的正则等效于 3 个 3 x 3 的卷积层的叠加。而这样的设计不仅可以大幅度的减少参数,其本身带有正则性质的 convolution map 能够更容易学一个 generlisable, expressive feature space。这也是现在绝大部分基于卷积的深层网络都在用小卷积核的原因。

然而 Deep CNN 对于其他任务还有一些致命性的缺陷。较为著名的是 up-sampling 和 pooling layer 的设计。
主要问题有:
- Up-sampling / pooling layer (e.g. bilinear interpolation) is deterministic. (a.k.a. not learnable)是确定性的、不可学习。
- 内部数据结构丢失;空间层级化信息丢失。
- 小物体信息无法重建 (假设有四个pooling layer 则 任何小于 2^4 = 16 pixel 的物体信息将理论上无法重建。)
在这样问题的存在下,语义分割问题一直处在瓶颈期无法再明显提高精度, 而 dilated convolution 的设计就良好的避免了这些问题。
1.空洞卷积的拯救之路:Dilated Convolution to the Rescue
题主提到的这篇 MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS 可能(?) 是第一篇尝试用 dilated convolution 做语义分割的文章。后续图森组和 Google Brain 都对于 dilated convolution 有着更细节的讨论,推荐阅读:Understanding Convolution for Semantic Segmentation Rethinking Atrous Convolution for Semantic Image Segmentation
对于 dilated convolution, 我们已经可以发现他的优点,即内部数据结构的保留和避免使用 down-sampling 这样的特性。但是完全基于 dilated convolution 的结构如何设计则是一个新的问题。
潜在问题 1:The Gridding Effect
假设我们仅仅多次叠加 dilation rate 2 的 3 x 3 kernel 的话,则会出现这个问题:

发现 kernel 并不连续,也就是并不是所有的 pixel 都用来计算了,因此这里将信息看做 checker-board 的方式会损失信息的连续性。这对 pixel-level dense prediction 的任务来说是致命的。
潜在问题 2:Long-ranged information might be not relevant. 远程信息
我们从 dilated convolution 的设计背景来看就能推测出这样的设计是用来获取 long-ranged information。然而光采用大 dilation rate 的信息或许只对一些大物体分割有效果,而对小物体来说可能则有弊无利了。如何同时处理不同大小的物体的关系,则是设计好 dilated convolution 网络的关键。
1.1通向标准化设计:Hybrid Dilated Convolution (HDC)
[1,2,5]、[1,2,3]
HDC的好处是可以使用任意的rate,对于识别相对大的物体表现得很好。增加RF.一组内的rate不应该有公因子关系,否则Gridding问题仍然存在,这就是HDC和ASPP最大的不同.
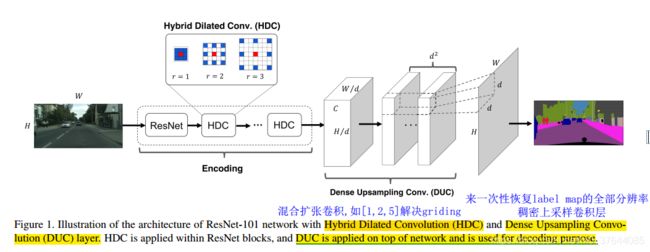
1.2多尺度分割的另类解:DeepLabV3之Atrous Spatial Pyramid Pooling (ASPP)
在处理多尺度物体分割时,我们通常会有以下几种方式来操作:((d)为DeepLabV2的图)
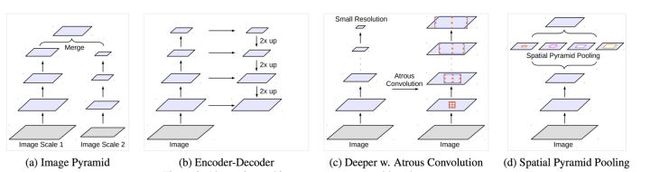
然而仅仅(在一个卷积分支网络下)使用 dilated convolution 去抓取多尺度物体是一个不正统的方法。比方说,我们用一个 HDC 的方法来获取一个大(近)车辆的信息,然而对于一个小(远)车辆的信息都不再受用。假设我们再去用小 dilated convolution 的方法重新获取小车辆的信息,则这么做非常的冗余。
基于港中文和商汤组的 PSPNet 里的 Pooling module (其网络同样获得当年的SOTA结果),ASPP 则在网络 decoder 上对于不同尺度上用不同大小的 dilation rate 来抓去多尺度信息,每个尺度则为一个独立的分支,在网络最后把他合并起来再接一个卷积层输出预测 label。这样的设计则有效避免了在 encoder 上冗余的信息的获取,直接关注与物体之间之内的相关性。
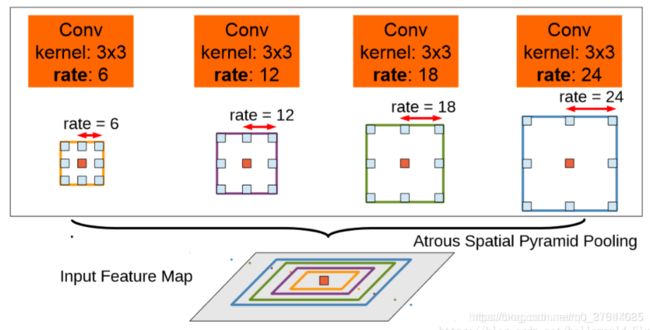
deeplabv2中的aspp如上图所示,在特征顶部映射图使用了四中不同采样率的空洞卷积。这表明以不同尺度采样时有效的,在Deeolabv3中向ASPP中添加了BN层。不同采样率的空洞卷积可以有效捕获多尺度信息,但会发现随着采样率的增加,滤波器有效权重(权重有效的应用在特征区域,而不是填充0)逐渐变小。
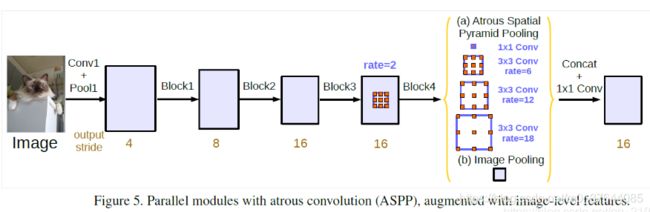
https://blog.csdn.net/qq_21997625/article/details/87080576
class ASPP(nn.Module):
def __init__(self, in_channel=512, depth=256):
super(ASPP,self).__init__()
# global average pooling : init nn.AdaptiveAvgPool2d ;also forward torch.mean(,,keep_dim=True)
self.mean = nn.AdaptiveAvgPool2d((1, 1))
self.conv = nn.Conv2d(in_channel, depth, 1, 1)
# k=1 s=1 no pad
self.atrous_block1 = nn.Conv2d(in_channel, depth, 1, 1)
self.atrous_block6 = nn.Conv2d(in_channel, depth, 3, 1, padding=6, dilation=6)
self.atrous_block12 = nn.Conv2d(in_channel, depth, 3, 1, padding=12, dilation=12)
self.atrous_block18 = nn.Conv2d(in_channel, depth, 3, 1, padding=18, dilation=18)
self.conv_1x1_output = nn.Conv2d(depth * 5, depth, 1, 1)
def forward(self, x):
size = x.shape[2:]
image_features = self.mean(x)
image_features = self.conv(image_features)
image_features = F.upsample(image_features, size=size, mode='bilinear')
atrous_block1 = self.atrous_block1(x)
atrous_block6 = self.atrous_block6(x)
atrous_block12 = self.atrous_block12(x)
atrous_block18 = self.atrous_block18(x)
net = self.conv_1x1_output(torch.cat([image_features, atrous_block1, atrous_block6,
atrous_block12, atrous_block18], dim=1))
return net官方版:tensorflow
def atrous_spatial_pyramid_pooling(inputs, output_stride, batch_norm_decay, is_training, depth=256):
"""Atrous Spatial Pyramid Pooling.
Args:
inputs: A tensor of size [batch, height, width, channels].
output_stride: The ResNet unit's stride. Determines the rates for atrous convolution.
the rates are (6, 12, 18) when the stride is 16, and doubled when 8.
batch_norm_decay: The moving average decay when estimating layer activation
statistics in batch normalization.
is_training: A boolean denoting whether the input is for training.
depth: The depth of the ResNet unit output.
Returns:
The atrous spatial pyramid pooling output.
"""
with tf.variable_scope("aspp"):
if output_stride not in [8, 16]:
raise ValueError('output_stride must be either 8 or 16.')
atrous_rates = [6, 12, 18]
if output_stride == 8:
atrous_rates = [2*rate for rate in atrous_rates]
with tf.contrib.slim.arg_scope(resnet_v2.resnet_arg_scope(batch_norm_decay=batch_norm_decay)):
with arg_scope([layers.batch_norm], is_training=is_training):
inputs_size = tf.shape(inputs)[1:3]
# (a) one 1x1 convolution and three 3x3 convolutions with rates = (6, 12, 18) when output stride = 16.
# the rates are doubled when output stride = 8.
conv_1x1 = layers_lib.conv2d(inputs, depth, [1, 1], stride=1, scope="conv_1x1")
conv_3x3_1 = resnet_utils.conv2d_same(inputs, depth, 3, stride=1, rate=atrous_rates[0], scope='conv_3x3_1')
conv_3x3_2 = resnet_utils.conv2d_same(inputs, depth, 3, stride=1, rate=atrous_rates[1], scope='conv_3x3_2')
conv_3x3_3 = resnet_utils.conv2d_same(inputs, depth, 3, stride=1, rate=atrous_rates[2], scope='conv_3x3_3')
# (b) the image-level features
with tf.variable_scope("image_level_features"):
# global average pooling
image_level_features = tf.reduce_mean(inputs, [1, 2], name='global_average_pooling', keepdims=True)
# 1x1 convolution with 256 filters( and batch normalization)
image_level_features = layers_lib.conv2d(image_level_features, depth, [1, 1], stride=1, scope='conv_1x1')
# bilinearly upsample features
image_level_features = tf.image.resize_bilinear(image_level_features, inputs_size, name='upsample')
net = tf.concat([conv_1x1, conv_3x3_1, conv_3x3_2, conv_3x3_3, image_level_features], axis=3, name='concat')
net = layers_lib.conv2d(net, depth, [1, 1], stride=1, scope='conv_1x1_concat')
return net
DeepLabV3+
DeepLab-v3+ 是由 DeepLab-v3 扩充而来,增加了解码器模组(encoder和上面是一样的),能够细化分割结果,能够更精准的处理物体的边缘,并进一步将深度卷积神经网络应用在空间金字塔池化(Spatial Pyramid Pooling,SPP)和解码器上,大幅提升处理物体大小以及不同长宽比例的能力,最后得到强而有力的语义分割编码解码器网络。
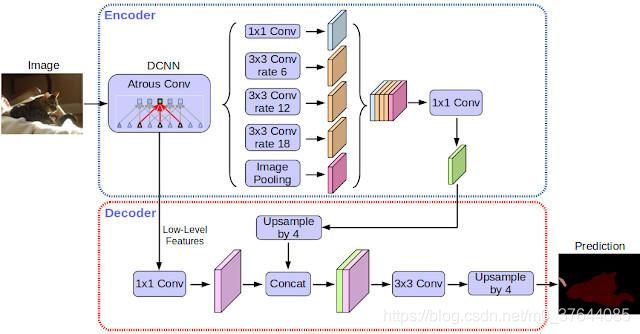
https://github.com/rishizek/tensorflow-deeplab-v3-plus
def deeplab_v3_plus_generator(num_classes,
output_stride,
base_architecture,
pre_trained_model,
batch_norm_decay,
data_format='channels_last'):
"""Generator for DeepLab v3 plus models.
Args:
num_classes: The number of possible classes for image classification.
output_stride: The ResNet unit's stride. Determines the rates for atrous convolution.
the rates are (6, 12, 18) when the stride is 16, and doubled when 8.
base_architecture: The architecture of base Resnet building block.
pre_trained_model: The path to the directory that contains pre-trained models.
batch_norm_decay: The moving average decay when estimating layer activation
statistics in batch normalization.
data_format: The input format ('channels_last', 'channels_first', or None).
If set to None, the format is dependent on whether a GPU is available.
Only 'channels_last' is supported currently.
Returns:
The model function that takes in `inputs` and `is_training` and
returns the output tensor of the DeepLab v3 model.
"""
if data_format is None:
# data_format = (
# 'channels_first' if tf.test.is_built_with_cuda() else 'channels_last')
pass
if batch_norm_decay is None:
batch_norm_decay = _BATCH_NORM_DECAY
if base_architecture not in ['resnet_v2_50', 'resnet_v2_101']:
raise ValueError("'base_architrecture' must be either 'resnet_v2_50' or 'resnet_v2_101'.")
if base_architecture == 'resnet_v2_50':
base_model = resnet_v2.resnet_v2_50
else:
base_model = resnet_v2.resnet_v2_101
def model(inputs, is_training):
"""Constructs the ResNet model given the inputs."""
if data_format == 'channels_first':
# Convert the inputs from channels_last (NHWC) to channels_first (NCHW).
# This provides a large performance boost on GPU. See
# https://www.tensorflow.org/performance/performance_guide#data_formats
inputs = tf.transpose(inputs, [0, 3, 1, 2])
# tf.logging.info('net shape: {}'.format(inputs.shape))
# encoder
with tf.contrib.slim.arg_scope(resnet_v2.resnet_arg_scope(batch_norm_decay=batch_norm_decay)):
logits, end_points = base_model(inputs,
num_classes=None,
is_training=is_training,
global_pool=False,
output_stride=output_stride)
if is_training:
exclude = [base_architecture + '/logits', 'global_step']
variables_to_restore = tf.contrib.slim.get_variables_to_restore(exclude=exclude)
tf.train.init_from_checkpoint(pre_trained_model,
{v.name.split(':')[0]: v for v in variables_to_restore})
inputs_size = tf.shape(inputs)[1:3]
net = end_points[base_architecture + '/block4']
encoder_output = atrous_spatial_pyramid_pooling(net, output_stride, batch_norm_decay, is_training)
with tf.variable_scope("decoder"):
with tf.contrib.slim.arg_scope(resnet_v2.resnet_arg_scope(batch_norm_decay=batch_norm_decay)):
with arg_scope([layers.batch_norm], is_training=is_training):
with tf.variable_scope("low_level_features"):
low_level_features = end_points[base_architecture + '/block1/unit_3/bottleneck_v2/conv1']
low_level_features = layers_lib.conv2d(low_level_features, 48,
[1, 1], stride=1, scope='conv_1x1')
low_level_features_size = tf.shape(low_level_features)[1:3]
with tf.variable_scope("upsampling_logits"):
net = tf.image.resize_bilinear(encoder_output, low_level_features_size, name='upsample_1')
net = tf.concat([net, low_level_features], axis=3, name='concat')
net = layers_lib.conv2d(net, 256, [3, 3], stride=1, scope='conv_3x3_1')
net = layers_lib.conv2d(net, 256, [3, 3], stride=1, scope='conv_3x3_2')
net = layers_lib.conv2d(net, num_classes, [1, 1], activation_fn=None, normalizer_fn=None, scope='conv_1x1')
logits = tf.image.resize_bilinear(net, inputs_size, name='upsample_2')
return logits
return model总结
Dilated Convolution 个人认为想法简单,直接且优雅,并取得了相当不错的效果提升。他起源于语义分割,大部分文章也用于语义分割,具体能否对其他应用有价值姑且还不知道,但确实是一个不错的探究方向。有另外的答主提到WaveNet, ByteNet 也用到了 dilated convolution 确实是一个很有趣的发现,因为本身 sequence-to-sequence learning 也是一个需要关注多尺度关系的问题。则在 sequence-to-sequence learning 如何实现,如何设计,跟分割或其他应用的关联是我们可以重新需要考虑的问题。