SynonymNet: 基于多个上下文双向匹配的同义实体发现
来自:RUC AI Box
论文:https://arxiv.org/abs/1901.00056
代码:https://github.com/czhang99/SynonymNet
命名实体的同义发现在许多NLP任务中起到了重要的作用。同义发现任务中一个核心的问题是如何衡量一对实体之间的语义相似度。基于表示学习(representation learning)的同义实体发现致力于学习更好的词表示(word embedding)或者字符表示(character-level embedding)。这些方法大都可以很好的处理表述相似的同义实体(例如airplane/aeroplane), 但在衡量语义相似的同义实体下表现不佳(例如clogged nose/nasal congestion)。近年来,基于上下文(context)的同义实体发现多基于分布式语义模型(Distributional Semantics Models)的假设 ,即“在相同的上下文中出现的词汇在某种程度上有类似的含义“。在实际应用中,一个命名实体会通常出现在许多不同的上下文中。对于每个命名实体,现有基于分布式语义模型的方法大多将单个上下文的信息拿来做匹配。
IJCAI2020的一篇论文 (“Entity Synonym Discovery via Multipiece Bilateral Context Matching”) 在如何利用多个上下文信息来做同义实体发现问题上进行了一些新的探索。作者认为对于一对命名实体,若对每个实体能利用多个不同的上下文来做匹配不仅可以更全面的学习其上下文语意表示从而提高衡量实体之间语义相似度的准确性,还可以增加匹配的鲁棒性,减少因采用某个低质量上下文而引入的噪声。为了达到这一目标,作者在同义词发现任务上将传统的基于单个上下文的匹配(single-piece context matching)扩展至多个上下文(multi-piece context),并通过多个上下文之间的双向匹配(bilateral context matching) 来学习实体间的相似度,从而用于海量文本中的同义实体发现。在公开/特定领域(医疗),英文/中文文本数据集上均取得了较佳的表现。
模型解析
SynonymNet核心idea是对于每个命名实体查找一组(多个)其出现的上下文句子,并通过对两组上下文句子之间进行匹配得到最终命名实体间的相似度。那么这样的匹配要如何实现呢?
作者采用了如下图所示的模型结构:检索器 (context retriever)通过检索的方式从海量文本中选择一组实体被提到的句子;编码器(context encoder)将每一个上下文信息进行编码; 双向匹配(bilateral matching)+泄漏单元(leaky unit)则将两个实体对应的两组上下文信息进行双向匹配;合成器(context aggregation)利用匹配的信息选择具有代表性,且在匹配中较为informative的上下文信息进行多上下文的聚合。作者考虑了两种不同的架构:一是针对二元实体组 的siamese 结构,根据同义实体是否匹配进行二分类;二是针对三元实体组 的triplet 结构,希望同义实体 的得分超过非同义实体 。

双向匹配。
对于一组命名实体 , 上下文检索+编码将器将 转化为了两组上下文的向量:
对于每个提到实体 的上下文向量 , 作者用bi-linear项来计算和每一个提到实体 的上下文向量 的匹配分数:

同样的,对于每一个提到实体 的上下文向量 ,作者也利用相同的方式计算匹配分数:
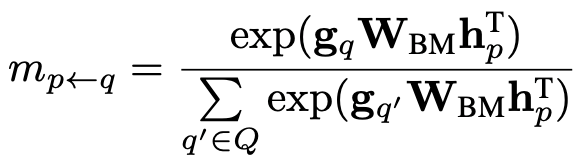
这样的匹配看似需要进行 次,但在实际实现中可以通过矩阵乘法进行高效计算: ,并通过按行/列取softmax得到两个方向的匹配分数。
泄露单元。
当需要和多个上下文进行匹配的时候,可能会存在没有高质量的上下文进行匹配,甚至上下文存在错误的情况。为了更好的解决这个问题,作者引入了泄漏单元(leaky unit)的概念。Leaky unit的想法是在双向匹配时引入一个多余的上下文向量 。该向量可以随模型学习,目的是为了在没有高质量上下文匹配时承担一些匹配的分数,从而减弱低质量上下文在匹配过程中带来的噪声和干扰。
在每个匹配方向上,Leaky unit会额外和 / 个上下文向量计算匹配分数:
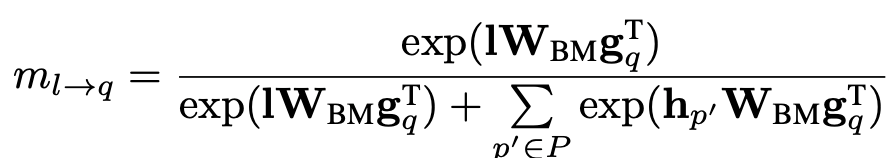
当存在某个低质量的上下文,比如因为实体 在句子语义成分中不重要时,其对应的上下文向量 在和提到实体 的 个上下文向量进行匹配时:

分母中的泄漏单元会承担匹配分数; 会减弱该 在上下文在匹配时的影响。横向比较上方两个公式的分子:当 > 时,泄漏单元会比低质量的上下文在匹配中更活跃,占用额外的匹配分数,从而减弱低质量上下文在匹配时的分数。
上下文信息聚合。
作者将多个上下文基于attention思想进行聚合。当已经获得了 个上下文之间的匹配分数后,作者认为某一个上下文 在 个上下文聚合过程中的重要的程度取决于在与另一边 个上下文匹配时最被需要的程度:

这里的动机是如果 个上下文和 匹配时最高的匹配分数已经很低,那么可以说明 在整个匹配过程中不够informative,聚合时应当给较小的attention;反之,如果 在和 个上下文匹配时最高的匹配分数很高,那么可以说明 在匹配过程中非常被需要。作为informative的上下文 在聚合时应当得到更大的attention。基于这个思路,聚合时采用了基于最强匹配分数进行的attention聚合,得到聚合后的上下文向量:
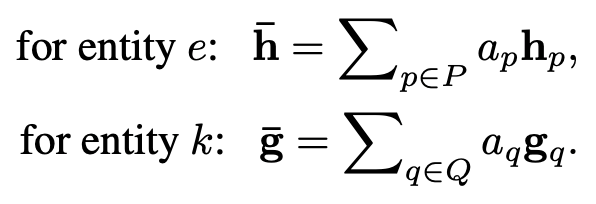
泄漏单元虽然在匹配时分担了匹配分数,但泄漏单元不参与聚合过程。因此泄漏单元不会在聚合过程中贡献信息给聚合后的上下文向量。这样是为了保证泄露的噪声能被隔离开,不去影响最终聚合的质量。
siamese/triplet 结构。
作者尝试了两种不同的模型结构/损失函数。siamese 结构以二元实体组 作为输入,损失函数利用聚合后的上下文向量刻画两个实体同义与否。triplet结构以三元实体组 作为输入,损失函数利用聚合后的上下文向量希望同义实体比非同义实体获得更高的分数: 大于一个margin。
实体发现流程
作者利用SynonymNet衡量实体间语义相似度的能力将其用于文本中的实体发现。如图所示,实体发现分为四步:1)根据文本训练word embedding;2)对于一个query entity , 通过其在embedding space上的 最近邻获得candidate entity;3)对于 < query entity, candidate entity > 利用SynonymNet获得相似度分数;4)最后根据SynonymNet分数获得同义实体对。

实验表现
作者在Wiki + Freebase, PubMed + UMLS, MedBook + MKG 三个数据集上进行了评估。实验采用AUC和MAP评价采用相同的word embedding时不同模型结构对于衡量实体同义相似度的影响。

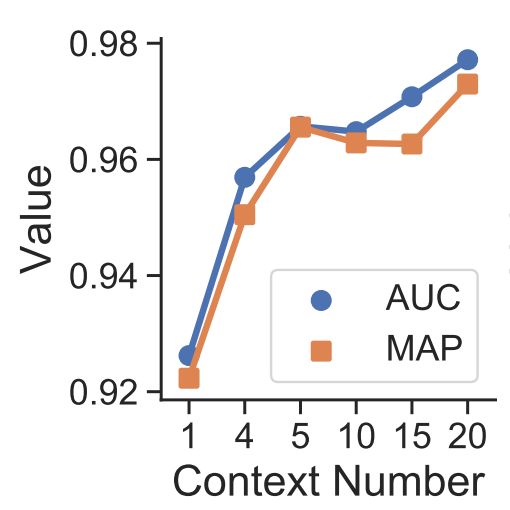
作者对上下文个数对性能的影响进行了评估。结果显示采用多个上下文进行匹配可以降低单个上下文匹配时可能带来的噪声,从而显著提高同义相似度的准确性。
作者还在真实的同义实体发现任务中进行了一些分析。word2vec采用了利用上下文来对实体语义进行建模的思想,用cosine similarity进行embedding最近邻选取可以得到初筛后的candidate entity。对于query entity “UNGA”,获得的candidates虽然大多出现在类似的上下文中,不相关的实体仍在前列。经过SynonymNet对于上下文更细粒度的刻画,以及多上下文的双向匹配后,同义实体的排名变得更靠前了。

总结
根据多个上下文进行双向匹配来确定两个实体同义程度,利用泄漏单元来处理多个上下文匹配时可能存在噪音的情况,思路直观,实现的方式简洁。实验结果上验证了采用多个上下文进行匹配来带准确度和鲁棒性上的提升。
该框架对于编码器,检索器的选择比较灵活。目前文中采用的是bi-LSTM结构,和基于transformer的众多预训练语言模型碰撞之后说不定也能有一些新的发现。在需要用多个上下文进行匹配的时候,如何利用多个上下文带来的多样性,全面地学习实体表示也是一个很有意思的问题。在处理由之产生的噪声方面,文中的泄漏单元给出了一个比较新颖的观点。
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
 。
。投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记
专辑 | NLP论文解读
整理不易,还望给个在看!