FLink DataStream开发之Time与Window
Time
Flink 流式处理中,存在时间的不同概念
- Event Time: 事件的创建时间,通常由事件中的时间戳描述,相当于食品的生产日期
- Ingestion Time:数据进入flink的时间,相当于食品快递到你家的时间
- Processing Time:是每个执行基于时间操作的算子的本地系统时间,与机器相关 ,默认的时间属性就是 Processing Time ,相当于你吃到汉堡的时间
通过实际场景理解:
- 一条日志进入到Flink的时间为2020-4-26 11:30:00:111 (Ingestion Time),
- 到达Windows的系统时间为2020-4-26 11:30:00:222 (Processing),
- 日志的内容为2020-4-26 10:30:00:333 ERROR Worker: RECEIVED SIGNAL TERM (Event Time)
使用场景分析
一般来说在生产环境中将 Event Time 与 Processing Time 对比的比较多,这两个也是我们常用的策略,Ingestion Time 一般用的较少。
用 Processing Time 的场景大多是用户不关心事件时间,它只需要关心这个时间窗口要有数据进来,只要有数据进来了,我就可以对进来窗口中的数据进行一系列的计算操作,然后再将计算后的数据发往下游。
而用 Event Time 的场景一般是业务需求需要时间这个字段(比如购物时是要先有下单事件、再有支付事件;借贷事件的风控是需要依赖时间来做判断的;机器异常检测触发的告警也是要具体的异常事件的时间展示出来;商品广告及时精准推荐给用户依赖的就是用户在浏览商品的时间段/频率/时长等信息),只能根据事件时间来处理数据,而且还要从事件中获取到事件的时间。
但是使用事件时间的话,就可能有这样的情况:数据源采集的数据往消息队列中发送时可能因为网络抖动、服务可用性、消息队列的分区数据堆积的影响而导致数据到达的不一定及时,可能会出现数据出现一定的乱序、延迟几分钟等,庆幸的是 Flink 支持通过 WaterMark 机制来处理这种延迟的数据
Time策略设置
初始化流处理环境后通过env.setStreamTimeCharacteristic设置时间策略
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 其余两种:
// env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
// env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
Window
window分类
三种窗口机制:
1) CountWindows
按照指定的数据条数生成一个Window,与时间无关.
2.)TimeWindow:
按照时间生成Windown.
3.)Session Window
按会话间隔生成Window(特)
注意:DataStreamAPI 提供用户自定义的Window操作,
两种数据聚合流程:
1)滚动窗口(Tumbling Window )
将数据依据固定的窗口长度对数据进行切片。
特点: 时间对齐,窗口长度固定,没有重叠。

滚动窗口分配器将每个元素分配到一个指定窗口大小的窗口中,滚动窗口有一个固定的大小,并且不会出现重叠。
2)滑动窗口(Sliding Window).
滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成。
特点: 时间对齐,窗口长度固定,有重叠。
滑动窗口分配器将元素分配到固定长度的窗口中,与滚动窗口类似,窗口的大小由窗口大小参数来配置,另一个窗口滑动参数控制滑动窗口开始的频率。因此,滑动窗口如果滑动参数小于窗口大小的话,窗口是可以重叠的,在这种情况下元素会被分配到多个窗口中。
例如,你有 10 分钟的窗口和 5 分钟的滑动,那么每个窗口中 5 分钟的窗口里包含着上个 10
分钟产生的数据,如下图所示:

实例
1. CountWindow
对于TimeWindow,可以根据窗口实现原理的不同分为类:
- 滚动窗口(Tumbling Window ) .
dataStream.keyBy(1)
.countWindow(3) //统计每 3 个元素的数量之和
.sum(1);
- 滑动窗口(Sliding Window).
dataStream.keyBy(1)
.countWindow(4, 3) //每隔 3 个元素统计过去 4 个元素的数量之和
.sum(1);
CountWindow 根据窗口中相同 key 元素的数量来触发执行,执行时只计算元素数量达到窗口大小的 key 对应的结果。
注意:CountWindow 的 window_size 指的是相同 Key 的元素的个数,不是输入的所有元素的总数。
1) 滚动窗口
默认的 CountWindow 是一个滚动窗口,只需要指定窗口大小即可,当元素数量达到窗口大小时,就会触发窗口的执行。
实例:
package hctang.tech.streaming.streamAPI.windowAPI
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.api.scala._
object StreamCountWindow {
def main(args:Array[String]):Unit={
//获取执行环境
val env=StreamExecutionEnvironment.getExecutionEnvironment
//创建sockSource
val stream=env.socketTextStream("localhost",9999)
//对stream进行梳理并按key聚合
val streamKeyBy=stream.map(item=>(item.split(" ")(0),item.split(" ")(1).toLong)).keyBy(0)
val streamWindow=streamKeyBy.countWindow(5)//这里的 5 指的是 5 个相同 key 的元素计算一次
val streamReduce=streamWindow.reduce((item1,item2)=>(item1._1,item1._2 + item2._2))//聚合
streamReduce.print()
//执行程序
env.execute("TumblinWindow")
}
}
netcat作为server端启动一个tcp的监听
nc -l 9999

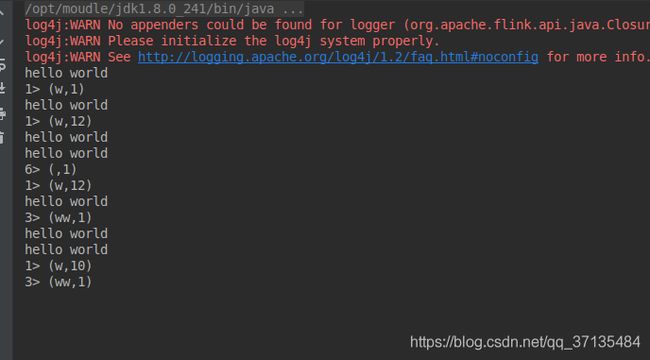
结果如图:

也就是说统计五次之后处理完就清空,然后重新统计,而滑动窗口是没有达到window_size时,每sliding_size倍数时处理一次,达到后处理一次,同时抛弃sliding_size个数据,以window_size=5,sliding_size=2为例子:
2,4,5,5,5,5,5,5,5,5,5…
2) 滑动窗口
滑动窗口和滚动窗口的函数名是完全一致的,只是在传参数时需要传入两个参数,一个是window_size,一个是 sliding_size。
package hctang.tech.streaming.streamAPI.windowAPI
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object StreamCounSlidtWindow {
def main(args:Array[String]):Unit={
//获取执行环境
val env=StreamExecutionEnvironment.getExecutionEnvironment
//创建sockSource
val stream=env.socketTextStream("localhost",9999)
//对stream进行梳理并按key聚合
val streamKeyBy=stream.map(item=>(item.split(" ")(0),item.split(" ")(1).toLong)).keyBy(0)
//滚动窗口
val streamWindow=streamKeyBy.countWindow(5,2)//当相同 key 的元素个数达到 2 个时,触发窗口计算,计算的窗口范围为 5
val streamReduce=streamWindow.reduce((item1,item2)=>(item1._1,item1._2 + item2._2))//聚合
streamReduce.print()
//执行程序
env.execute("TumblinWindow")
}
}
看看输入和输出会好理解点
输入:
logs$ nc -l 9999
q 1
w 1
e 1
r 1
t 1
q 1
w 1
w 1
e 1
y 1
u 1
r 1
t 1
r 1
r 1
q 1
w 1
e 1
e 1
e 1
e 1
e 1
输出:

举个例子,流水线,有零件需要机器整理,不同的零件,有很多的机器,不同的零件对应不同的零件,机器只有两只手,一只手只能抓一个,当两只手都抓有零件的时候需要将零件放入旁边的盒子里,而一个盒子最多放五个,机器每放一次盒子自动报数:2,4,5,5,5,5,5…
2.TimeWindow
TimeWindow 是将指定时间范围内的所有数据组成一个 window,一次对一个 window 里面的所有数据进行计算。
对于TimeWindow,可以根据窗口实现原理的不同分为类:
- 滚动窗口(Tumbling Window ) .
dataStream.keyBy(1)
.timeWindow(Time.minutes(1)) //time Window 每分钟统计一次数量和
.sum(1);
- 滑动窗口(Sliding Window).
dataStream.keyBy(1)
.timeWindow(Time.minutes(1), Time.seconds(30)) //sliding time Window 每隔 30s 统计过去一分钟的数量和
.sum(1);
1) 滚动窗口
Flink 默认的时间窗口根据 Processing Time 进行窗口的划分,将 Flink 获取到的数据根据进入 Flink 的时间划分到不同的窗口中。
package hctang.tech.streaming
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
object WindosWrodCount {
def main(args:Array[String]){
import org.apache.flink.api.scala._
val env=StreamExecutionEnvironment.getExecutionEnvironment
val text=env.socketTextStream("localhost",9999)
val counts=text.flatMap{_.toLowerCase.split("\\W+") filter{_.nonEmpty}}
.map{(_,1)}.keyBy(0)
.timeWindow(Time.seconds(5))//统计一秒内接收到的单词
.sum(1)
counts.print()
env.execute("Window Stream WordCount")
}
}
时间间隔可以通过 Time.milliseconds(x),Time.seconds(x),Time.minutes(x)等其中的一个来指定。
2) 滑动窗口(SlidingEventTimeWindows)
滑动窗口和滚动窗口的函数名是完全一致的,只是在传参数时需要传入两个参数,一个是window_size,一个是 sliding_size。
下面代码中的 sliding_size 设置为了 2s,也就是说,窗口每 2s 就计算一次,每一次计算的
window 范围是 5s 内的所有元素。
package hctang.tech.streaming.streamAPI.windowAPI
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
object StreamTimeslidWindos{
def main(args:Array[String]){
import org.apache.flink.api.scala._
val env=StreamExecutionEnvironment.getExecutionEnvironment
val text=env.socketTextStream("localhost",9999)
val counts=text.flatMap{_.toLowerCase.split("\\W+") filter{_.nonEmpty}}
.map{(_,1)}.keyBy(0)
.timeWindow(Time.seconds(5),Time.seconds(2))
.sum(1)
counts.print()
env.execute("Window Stream WordCount")
}
}
3.会话窗口
由一系列事件组合一个指定时间长度的 timeout 间隙组成,类似于 web 应用的 session,也就是一段时间没有接收到新数据就会生成新的窗口。
特点: 时间无对齐
session 窗口分配器通过 session 活动来对元素进行分组,session 窗口跟滚动窗口和滑动窗口相比,不会有重叠和固定的开始时间和结束时间的情况,相反,当它在一个固定的时间周期内不再收到元素,即非活动间隔产生,那个这个窗口就会关闭。一个 session 窗口通过一个 session 间隔来配置,这个 session 间隔定义了非活跃周期的长度,当这个非活跃周期产生,那么当前的 session 将关闭并且后续的元素将被分配到新的 session 窗口中去。

dataStream.keyBy(1)
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(5)))//表示如果 5s 内没出现数据则认为超出会话时长,然后计算这个窗口的和
.sum(1);
Window Reduce
给 window 赋一个 reduce 功能的函数,并返回一个聚合的结果。
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
object StreamWindowReduce {
def main(args: Array[String]): Unit = {
// 获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 创建 SocketSource
val stream = env.socketTextStream("node01", 9999)
// 对 stream 进行处理并按 key 聚合
val streamKeyBy = stream.map(item => (item, 1)).keyBy(0)
// 引入时间窗口
val streamWindow = streamKeyBy.timeWindow(Time.seconds(5))
// 执行聚合操作
val streamReduce = streamWindow.reduce(
(item1, item2) => (item1._1, item1._2 + item2._2)
)
// 将聚合数据写入文件
streamReduce.print()
// 执行程序
env.execute("TumblingWindow")
}
}


Window Apply
apply 方法可以进行一些自定义处理,通过匿名内部类的方法来实现。当有一些复杂计算时使用。
用法
- 实现一个 WindowFunction 类
- 指定该类的泛型为 [输入数据类型, 输出数据类型, keyBy 中使用分组字段的类型, 窗口类型]
package hctang.tech.streaming.streamAPI.windowAPI
import org.apache.flink.streaming.api.scala.function.RichWindowFunction
import org.apache.flink.streaming.api.scala.{DataStream, KeyedStream, StreamExecutionEnvironment, WindowedStream}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
import org.apache.flink.streaming.api.scala._
object StreamWindowApplyDemo {
def main(args: Array[String]):Unit={
//1. 获取流处理运行环境
val env=StreamExecutionEnvironment.getExecutionEnvironment
//2. 构建 socket 流数据源,并指定 IP 地址和端口号
val textDataStream = env.socketTextStream("localhost", 9999).flatMap(_.split(" "))
//3. 对接收到的数据转换成单词元组
val wordDataStream = textDataStream.map(_->1)
//4. 使用 keyBy 进行分流(分组)
val groupedDataStream: KeyedStream[(String, Int), String] = wordDataStream.keyBy(_._1)
//5. 使用 timeWinodw 指定窗口的长度(每 3 秒计算一次)
val windowDataStream: WindowedStream[(String, Int), String, TimeWindow] = groupedDataStream.timeWindow(Time.seconds(3))
//6. 实现一个 WindowFunction 匿名内部类
val reduceDatStream: DataStream[(String, Int)] = windowDataStream.apply(new RichWindowFunction[(String, Int), (String, Int), String, TimeWindow] {
//在 apply 方法中实现数据的聚合
override def apply(key: String, window: TimeWindow, input: Iterable[(String, Int)], out: Collector[(String, Int)]):
Unit = {
println("hello world")
val tuple = input.reduce((t1, t2) => { (t1._1, t1._2 + t2._2)
})
//将要返回的数据收集起来,发送回去
out.collect(tuple)
}
})
reduceDatStream.print()
env.execute()
}
}
Window Fold
给窗口赋一个 fold 功能的函数,并返回一个 fold 后的结果。
fold: 折叠,具有初始值的被 Keys 化数据流上的“滚动”折叠。将当前数据元与最后折叠的值组合并发出新值。折叠函数,当应用于序列(1,2,3,4,5)时,发出序列“start-1”,“start-1-2”,“start-1-2-3”,. …
val result: DataStream[String] = keyedStream.fold(“start”)((str, i) => { str + “-” + i })