论文浅尝 | K-BERT: Enabling Language Representation with Knowledge Graph
1.论文动机
论文认为通过泛用型公开语料预训练得到的BERT模型只拥有“常识”,在特定垂直领域(如科技、医疗、教育等)的任务中表现效果存在提升空间。由于pre-training and fine-tuning在领域上的差异,利用BERT做知识驱动任务的时候表现不尽如人意。
论文提出的K-BERT通过引进知识图谱(将知识库中的结构化信息(三元组)融入到预训练模型)中,可以更好地解决领域相关任务。
如何将外部知识整合到模型是论文解决的核心难点,他存在两个问题:
Heterogeneous Embedding Space: 即文本的单词embedding和知识库的实体实体embedding通常是通过不同方式获取的,使得他俩的向量空间不一致;
Knowledge Noise: 即过多的知识融合可能会使原始句子偏离正确的本意,过犹不及。
2.论文提出的解决方案
论文提出的K-BERT模型主要包括四部分:
1)Knowledge layer
2)Embedding layer
3)Seeing layer
4)Mask-Transformer Encoder

1)Knowledge layer
这层包含一个知识图谱和输入的语言,需要将知识图谱的内容嵌入到语句当中,生成语句树,通过两步完成:
K-Query 输入句子中涉及的所有实体都被选中,并查询它们在KG中对应的三元组;
K-Inject 将查询到的三元组注入到句子中,将三元组插入到它们相应的位置,并生成一个句子树。

2)Embedding layer
K-BERT的输入和原始BERT的输入形式是一样的,都需要token embedding, position embedding和segment embedding,不同的是,K-BERT的输入是一个句子树,因此问题就变成了句子树到序列化句子的转化,并同时保留结构化信息。

Token embedding:要将句子树转化为一个序列,作者提出一种简单的重排策略:分支中的token被插入到相应节点之后,而后续的token被向后移动。例如对于上图中的句子树,则重排后变成了Tim Cook CEO Apple is visiting Beijing capital China is a City now。
Soft-position embedding:Token embedding重排后的句子显然是毫无意义的,这里利用了position embedding来还原回结构信息。还是以上图为例,重排后,CEO和Apple被插入在了Cook和is之间,但是is应该是接在Cook之后一个位置的,那么我们直接把is的position number 设置为3即可。这样来看可以认为输入了Tim Cook is visiting Beijing now + Tim Cook CEO Apple + Beijing capital China 三句话。
Segment embedding:同BERT一样。
3)Seeing Layer
这是与BERT最大的不同,使用了一个可视化矩阵,即只有同一分支的词相互可见。作者认为Seeing layer的mask matrix是K-BERT有效的关键,主要解决了前面提到的Knowledge Noise问题。栗子中China仅仅修饰的是Beijing,和Apple半毛钱关系没有,因此像这种token之间就不应该有相互影响。
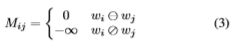
为此定义一个可见矩阵,判断句子中的单词之间是否彼此影响。

4)Mask-Transformer Encoder
BERT中的Transformer Encoder不能接受上述可见矩阵作为输入,因此需要稍作改进。
传统Transformer模型中的self-attention为:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
Mask-Transformer是一层层mask-self-attention的堆叠,mask-self-attention公式如下:

如图,对于[cls]而言,Apple修饰Cook,不能影响他,但是底层Apple影响Cook,再由Cook影响[cls],在堆叠中实现了知识图谱中实体对句子的影响。

3.总结
K-BERT最大的创新点在于提出了Seeing Layer层,并且通过堆叠的方式整合进了BERT原有框架中,使得BERT模型能够很好兼容K-BERT。
得益于知识图谱的辅助,K-BERT相比于BERT能更好的完成知识驱动类型的任务。