论文浅尝 | Enriching Pre-trained Language Model with Entity Information for Relation Classification
论文针对句子级别的关系抽取问题提出了一种结合BERT预训练模型和目标实体信息的模型。
1. 文章主要贡献
-
提出将 BERT 用在了关系抽取任务, 探索了实体和实体位置在预训练模型中的结合方式。
-
可以通过在实体前后加标识符得方式表明实体位置, 代替传统位置向量的做法,论文也证实了这种方法得有效性。
2. 论文模型详解
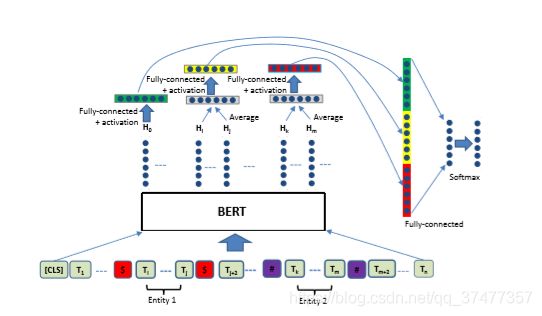
2.1 数据预处理
1)针对输入进来的句子,需要在句首增加[cls]符号
2)在第一个实体前后增加$符号
3)在第二个实体前后增加#符号
e.g. “The kitchen is the last renovated part of the house.“这句话输入BERT模型前应改为”[cls]The $kitchen$ is the last renovated part of the #house#.”
2.2 BERT模型处理
和经典的BERT模型一致,输入序列处理后得到的对应的序列输出向量。
2.3 输出处理
对于BERT模型处理输出的向量,在之后输入到全连接层中:
1)[cls] 位置的输出可以作为句子的向量表示, 记作 H 0 H_0 H0. 它经过 tanh 激活和线性变换后得到。
H 0 ′ = W 0 ∗ t a n h ( H 0 ) + b 0 H_0' = W_0*tanh(H_0) + b_0 H0′=W0∗tanh(H0)+b0
2)两个实体向量的处理方法:
假设BERT 输出的 实体1、2的开始和终止向量分别为 H i , H j , H k , H m H_i,H_j,H_k,H_m Hi,Hj,Hk,Hm,则实体1、2的向量表示为:
e 1 = 1 j − i + 1 ∑ t = i j H t e_1 = \frac{1}{j-i+1}\sum_{t=i}^{j}H_t e1=j−i+11t=i∑jHt
e 2 = 1 m − k + 1 ∑ t = k m H t e_2 = \frac{1}{m-k+1}\sum_{t=k}^{m}H_t e2=m−k+11t=k∑mHt
H 1 ′ = W 1 e 1 + b 1 H_1' = W_1e_1 + b_1 H1′=W1e1+b1
H 2 ′ = W 2 e 2 + b 2 H_2' = W_2e_2 + b_2 H2′=W2e2+b2
3)最后将 H 0 ′ , H 1 ′ , H 2 ′ H_0',H_1',H_2' H0′,H1′,H2′三个组合起来,输入线性层做softmax:
h ′ ′ = W 3 [ c o n c a t ( H 0 ′ , H 1 ′ , H 2 ′ ) ] + b 3 h'' = W_3[concat(H_0',H_1',H_2')] + b_3 h′′=W3[concat(H0′,H1′,H2′)]+b3
p = s o f t m a x ( h ′ ′ ) p = softmax(h'') p=softmax(h′′)
3. 效果分析
论文在 SemEval-2010 Task 8 dataset 上做了实验, 实验证明 R-BERT 比其他的模型如CR-CNN, ATTENTION- CNN 等效果都要好。
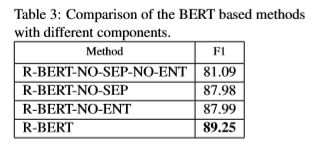
除此之外,作者的还做了三个消融实验,结论表明:仅使用[CLS]而不使用实体的词向量会使模型得 F1 从 89.25% 降至 87.99%;不加上特殊标记 ‘$’ 和 ‘#会使模型的F1从89.25%降低至87.98%;以及既不加特殊标记也不使用[CLS]会使模型的F1从89.25%降低至81.09%。说明给实体前后增加标识符确实可以帮助模型提供实体信息 ,想办法主动明确实体信息对模型是有帮助的。
4.个人应用启发
这种方法简单而且功能强大,能够很好的应用到知识图谱关系抽取任务中。计划尝试研究这种方法在自动化知识图谱构建的应用。