【pytorch】简单的一个模型做cifar10 分类(五)-使用现代经典模型提升性能
模型vgg:
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(7): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): ReLU(inplace=True)
(10): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(12): ReLU(inplace=True)
(13): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(14): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(16): ReLU(inplace=True)
(17): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(19): ReLU(inplace=True)
(20): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(21): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(26): ReLU(inplace=True)
(27): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(28): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(29): ReLU(inplace=True)
(30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(31): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(32): ReLU(inplace=True)
(33): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(34): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(35): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(36): ReLU(inplace=True)
(37): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(38): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(39): ReLU(inplace=True)
(40): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(41): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(42): ReLU(inplace=True)
(43): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(44): AvgPool2d(kernel_size=1, stride=1, padding=0)
)
(classifier): Linear(in_features=512, out_features=10, bias=True)
)这里比较迷惑的就是,为啥和vgg16本来的模型有点出入呢。因为原来的是后面三层fc,这里只有一层,可能是因为这里只有10分类,所以不需要三层fc呀,哈哈哈。
直接秀结果:
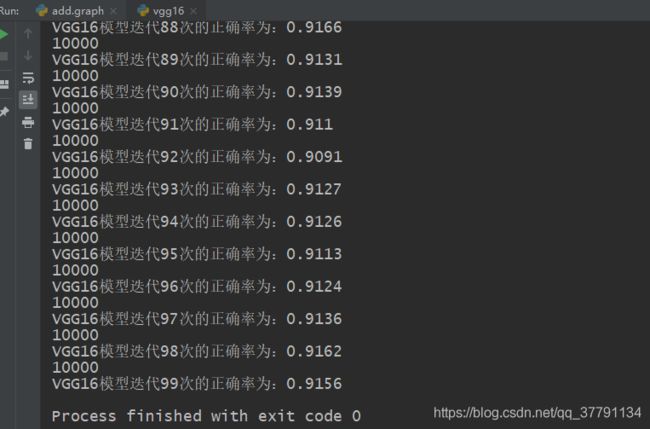
代码如下:
# -*- coding: utf-8 -*-
'''
@Time : 2020/8/13 21:15
@Author : HHNa
@FileName: vgg16.py
@Software: PyCharm
'''
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
cfg = {'VGG16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256,
'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'VGG19':[64, 64, "M", 128, 128, 'M', 256, 256, 256,
256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M']}
class VGG(nn.Module):
def __init__(self, vgg_name):
super(VGG, self).__init__()
self.features = self._make_layers(cfg[vgg_name])
self.classifier = nn.Linear(512, 10)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out
def _make_layers(selfs, cfg):
layers = []
in_channels = 3
for x in cfg:
if x == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
layers += [nn.Conv2d(in_channels, x, kernel_size=3,padding=1),
nn.BatchNorm2d(x),
nn.ReLU(inplace=True)]
in_channels = x
layers += [nn.AvgPool2d(kernel_size=1,stride=1)]
return nn.Sequential(*layers)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#Data
print('==>preparing data..')
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=False, transform=transform_train)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128,
shuffle=True, num_workers=0)
testset = torchvision.datasets.CIFAR10(root='./data',train=False,
download=False,transform=transform_test)
testloader = torch.utils. data.DataLoader(testset, batch_size=100,
shuffle=False, num_workers=0)
classs = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'forg', 'horse'
'ship', 'truck')
#Model
print('====>Building model...')
net = VGG('VGG16')
print(net)
net = net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=0.001)
loss_function = nn.CrossEntropyLoss()
EPOCHES = 100
for ep in range(EPOCHES):
running_loss = 0
for i, data in enumerate(trainloader, 0):
img, label = data
img, label = img.to(device), label.to(device)
optimizer.zero_grad()
net.train()
out = net(img)
loss = loss_function(out, label)
loss.backward()
optimizer.step()
# 显示损失值
running_loss += loss.item()
if i % 2000 == 1999:
print('[%d, %5d] loss: %0.3f' % (ep+1, i+1, running_loss /2000))
net_correct = 0
total = 0
for img, label in testloader:
img, label = img.to(device), label.to(device)
net.eval()
out = net(img)
_, prediction = torch.max(out, 1) # 按行取最大值
total += label.size(0)
net_correct += (prediction == label).sum().item()
print(total)
print("VGG16模型迭代" + str(ep) + "次的正确率为:" + str(net_correct / total))