tensorflow中cifar-10文档的Read操作
前言
在tensorflow的官方文档中得卷积神经网络一章,有一个使用cifar-10图片数据集的实验,搭建卷积神经网络倒不难,但是那个cifar10_input文件着实让我费了一番心思。配合着官方文档也算看的七七八八,但是中间还是有一些不太明白,不明白的mark一下,这次记下一些已经明白的。
研究
cifar10_input.py文件的read操作,主要的就是下面的代码:
if not eval_data:
filenames = [os.path.join(data_dir, 'data_batch_%d.bin' % i)
for i in xrange(1, 6)]
num_examples_per_epoch = NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN
else:
filenames = [os.path.join(data_dir, 'test_batch.bin')]
num_examples_per_epoch = NUM_EXAMPLES_PER_EPOCH_FOR_EVAL
...
filename_queue = tf.train.string_input_producer(filenames)
...
label_bytes = 1 # 2 for CIFAR-100
result.height = 32
result.width = 32
result.depth = 3
image_bytes = result.height * result.width * result.depth
# Every record consists of a label followed by the image, with a
# fixed number of bytes for each.
record_bytes = label_bytes + image_bytes
# Read a record, getting filenames from the filename_queue. No
# header or footer in the CIFAR-10 format, so we leave header_bytes
# and footer_bytes at their default of 0.
reader = tf.FixedLengthRecordReader(record_bytes=record_bytes)
result.key, value = reader.read(filename_queue)
...
if shuffle:
images, label_batch = tf.train.shuffle_batch(
[image, label],
batch_size=batch_size,
num_threads=num_preprocess_threads,
capacity=min_queue_examples + 3 * batch_size,
min_after_dequeue=min_queue_examples)
else:
images, label_batch = tf.train.batch(
[image, label],
batch_size=batch_size,
num_threads=num_preprocess_threads,
capacity=min_queue_examples + 3 * batch_size)开始并不明白这段代码是用来干什么的,越看越糊涂,因为之前使用tensorflow最多也就是使用哪个tf.placeholder()这个操作,并没有使用tensorflow自带的读写方法来读写,所以上面的代码看的很费劲儿。不过我在官方文档的How-To这个document中看到了这个东西:
Batching
def read_my_file_format(filename_queue):
reader = tf.SomeReader()
key, record_string = reader.read(filename_queue)
example, label = tf.some_decoder(record_string)
processed_example = some_processing(example)
return processed_example, label
def input_pipeline(filenames, batch_size, num_epochs=None):
filename_queue = tf.train.string_input_producer(
filenames, num_epochs=num_epochs, shuffle=True)
example, label = read_my_file_format(filename_queue)
# min_after_dequeue defines how big a buffer we will randomly sample
# from -- bigger means better shuffling but slower start up and more
# memory used.
# capacity must be larger than min_after_dequeue and the amount larger
# determines the maximum we will prefetch. Recommendation:
# min_after_dequeue + (num_threads + a small safety margin) * batch_size
min_after_dequeue = 10000
capacity = min_after_dequeue + 3 * batch_size
example_batch, label_batch = tf.train.shuffle_batch(
[example, label], batch_size=batch_size, capacity=capacity,
min_after_dequeue=min_after_dequeue)
return example_batch, label_batch感觉豁然开朗,再研究一下其官方文档API就能大约明白期间意思。最有代表性的图示官方文档中也给出来了,虽然官方文档给的解释并不多。
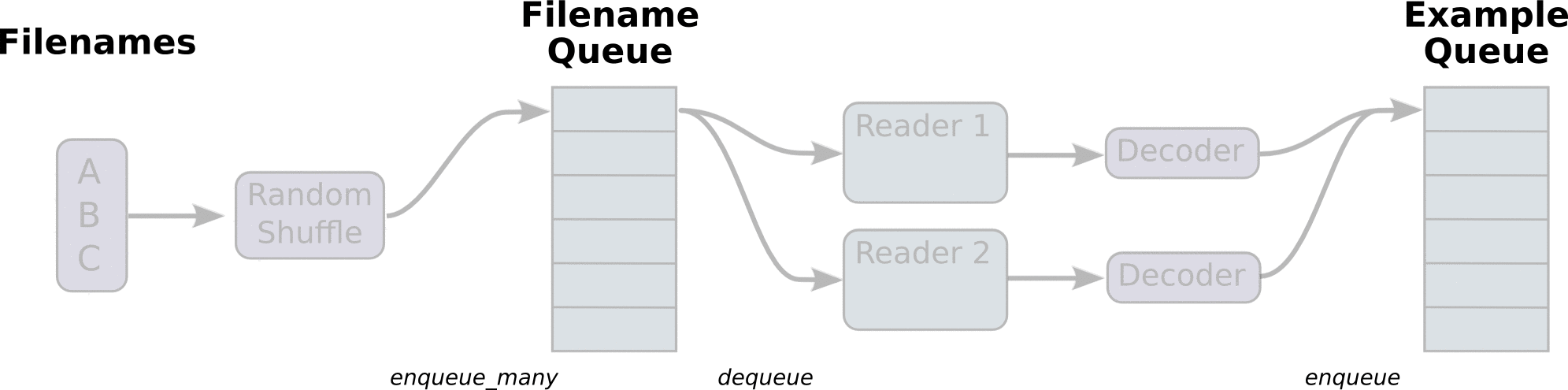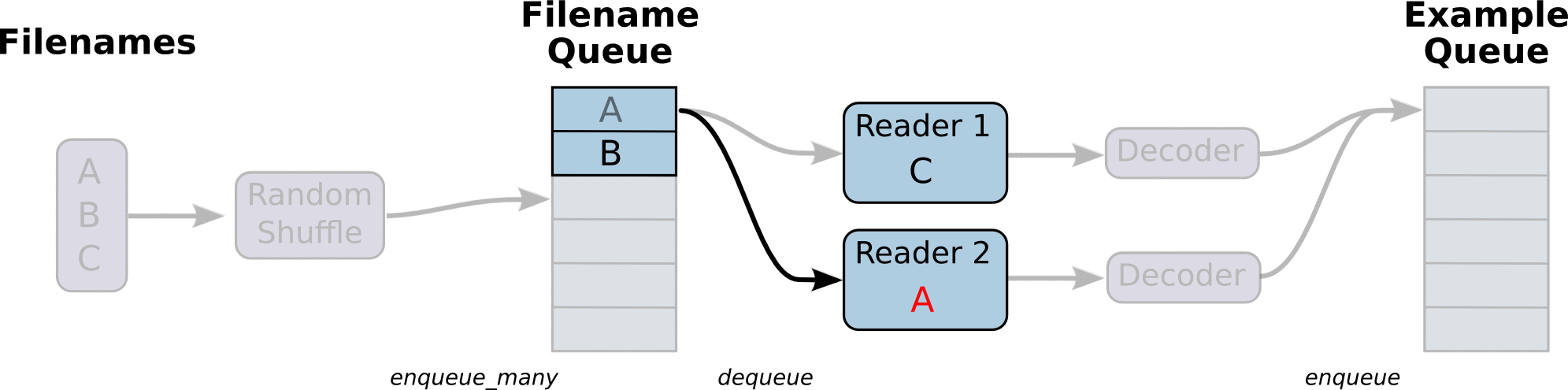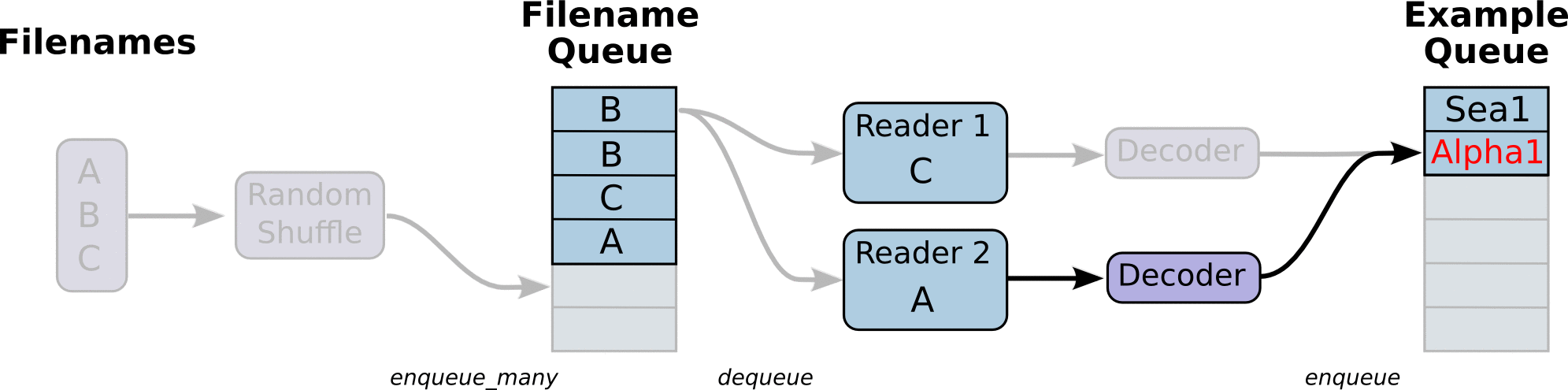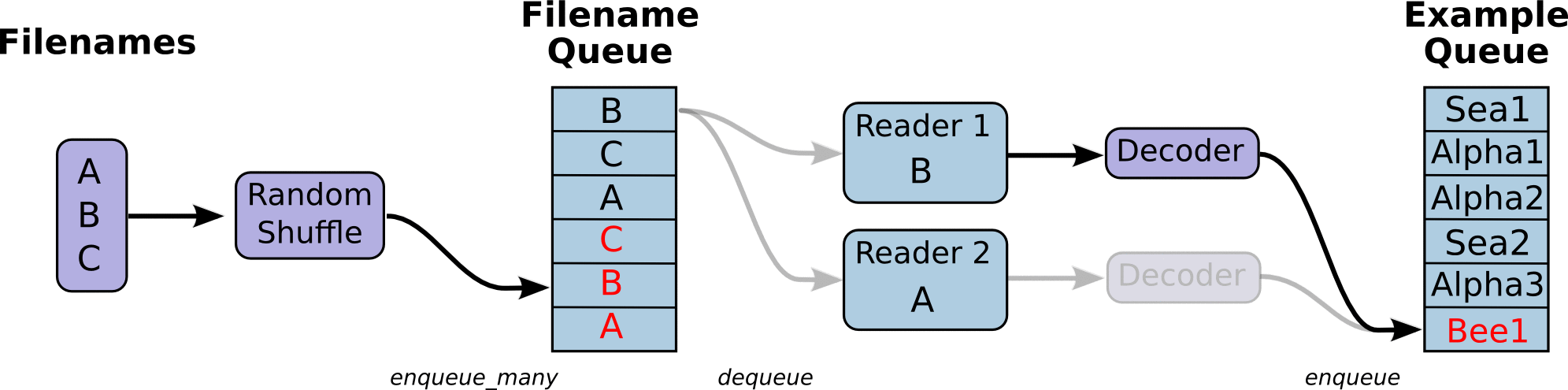
API我就不一一解释了,我们下面通过实验来明白。
实验
首先在tensorflow路径下创建两个文件,分别命名为test.txt以及test2.txt,其内容分别是:
test.txt:
test line1
test line2
test line3
test line4
test line5
test line6test2.txt:
test2 line1
test2 line2
test2 line3
test2 line4
test2 line5
test2 line6然后再命令行里依次键入下面的命令:
import tensorflow as tf
filenames=['test.txt','test2.txt']
#创建如上图所示的filename_queue
filename_queue=tf.train.string_input_producer(filenames)
#选取的是每次读取一行的TextLineReader
reader=tf.TextLineReader()
init=tf.initialize_all_variables()
#读取文件,也就是创建上图中的Reader
key,value=reader.read(filename_queue)
#读取batch文件,batch_size设置成1,为了方便看
bs=tf.train.batch([value],batch_size=1,num_threads=1,capacity=2)
sess=tf.Session()
#非常关键,这个是连通各个queue图的关键
tf.train.start_queue_runners(sess=sess)
#计算有reader的输出
b=reader.num_records_produced()然后我们执行:
>>> sess.run(bs)
array(['test line1'], dtype=object)
>>> sess.run(b)
4
>>> sess.run(bs)
array(['test line2'], dtype=object)
>>> sess.run(b)
5
>>> sess.run(bs)
array(['test line3'], dtype=object)
>>> sess.run(bs)
array(['test line4'], dtype=object)
>>> sess.run(bs)
array(['test line5'], dtype=object)
>>> sess.run(bs)
array(['test line6'], dtype=object)
>>> sess.run(bs)
array(['test2 line1'], dtype=object)
>>> sess.run(bs)
array(['test2 line2'], dtype=object)
>>> sess.run(bs)
array(['test2 line3'], dtype=object)
>>> sess.run(bs)
array(['test2 line4'], dtype=object)
>>> sess.run(bs)
array(['test2 line5'], dtype=object)
>>> sess.run(bs)
array(['test2 line6'], dtype=object)
>>> sess.run(bs)
array(['test2 line1'], dtype=object)
>>> sess.run(bs)
array(['test2 line2'], dtype=object)
>>> sess.run(bs)
array(['test2 line3'], dtype=object)
>>> sess.run(bs)
array(['test2 line4'], dtype=object)
>>> sess.run(bs)
array(['test2 line5'], dtype=object)
>>> sess.run(bs)
array(['test2 line6'], dtype=object)
>>> sess.run(bs)
array(['test line1'], dtype=object)我们发现,当batch_size设置成为1的时候,bs的输出是按照文件行数进行逐步打印的,原因是,我们选择的是单个Reader进行操作的,这个Reader先将test.txt文件读取,然后逐行读取并将读取的文本送到example queue(如上图)中,因为这里batch设置的是1,而且用到的是tf.train.batch()方法,中间没有shuffle,所以自然而然是按照顺序输出的,之后Reader再读取test2.txt。但是这里有一个疑惑,为什么reader.num_records_produced的第一个输出不是从1开始的,这点不太清楚。
另外,打印出filename_queue的size:
>>> sess.run(filename_queue.size())
32发现filename_queue的size有32个之多!这点也不明白。。。
我们可以更改实验条件,将batch_size设置成2,会发现也是顺序的输出,而且每次输出为2行文本(和batch_size一样)
我们继续更改实验条件,将tf.train.batch方法换成tf.train.shuffle_batch方法,文本数据不变:
import tensorflow as tf
filenames=['test.txt','test2.txt']
filename_queue=tf.train.string_input_producer(filenames)
reader=tf.TextLineReader()
init=tf.initialize_all_variables()
key,value=reader.read(filename_queue)
bs=tf.train.shuffle_batch([value],batch_size=1,num_threads=1,capacity=4,min_after_dequeue=2)
sess=tf.Session()
tf.train.start_queue_runners(sess=sess)
b=reader.num_records_produced()
继续刚才的执行:
>>> sess.run(bs)
array(['test2 line2'], dtype=object)
>>> sess.run(bs)
array(['test2 line5'], dtype=object)
>>> sess.run(bs)
array(['test2 line6'], dtype=object)
>>> sess.run(bs)
array(['test2 line4'], dtype=object)
>>> sess.run(bs)
array(['test2 line3'], dtype=object)
>>> sess.run(bs)
array(['test line1'], dtype=object)
>>> sess.run(bs)
array(['test line2'], dtype=object)
>>> sess.run(bs)
array(['test2 line1'], dtype=object)
>>> sess.run(bs)
array(['test line4'], dtype=object)
>>> sess.run(bs)
array(['test line5'], dtype=object)
>>> sess.run(bs)
array(['test2 line1'], dtype=object)
>>> sess.run(bs)
array(['test line3'], dtype=object)我们发现的是,使用了shuffle操作之后,明显的bs的输出变得不一样了,变得没有规则,然后我们看filename_queue的size:
>>> sess.run(filename_queue.size())
32发现也是32,由此估计是tensorflow会根据文件大小默认filename_queue的长度。
注意这里面的capacity=4,min_after_dequeue=2这些个命令,capacity指的是example queue的最大长度,
而min_after_dequeue是指在出队列之后,example queue最少要保留的元素个数,为什么需要这个,其实是为了混合的更显著。也正是有这两个元素,让shuffle变得可能。
到这里基本上大概的思路能明白,但是上面的实验都是对于单个的Reader,和上一节的图不太一致,根据官网教程,为了使用多个Reader,我们可以这样:
import tensorflow as tf
filenames=['test.txt','test2.txt']
filename_queue=tf.train.string_input_producer(filenames)
reader=tf.TextLineReader()
init=tf.initialize_all_variables()
key_list,value_list=[reader.read(filename_queue) for _ in range(2)]
bs2=tf.train.shuffle_batch_join([value_list],batch_size=1,capacity=4,min_after_dequeue=2)
sess=tf.Session()
sess.run(init)
tf.train.start_queue_runners(sess=sess)运行的结果如下:
>>> sess.run(bs2)
[array(['test2.txt:2'], dtype=object), array(['test2 line2'], dtype=object)]
>>> sess.run(bs2)
[array(['test2.txt:5'], dtype=object), array(['test2 line5'], dtype=object)]
>>> sess.run(bs2)
[array(['test2.txt:6'], dtype=object), array(['test2 line6'], dtype=object)]
>>> sess.run(bs2)
[array(['test2.txt:4'], dtype=object), array(['test2 line4'], dtype=object)]
>>> sess.run(bs2)
[array(['test2.txt:3'], dtype=object), array(['test2 line3'], dtype=object)]
>>> sess.run(bs2)
[array(['test2.txt:1'], dtype=object), array(['test2 line1'], dtype=object)]
>>> sess.run(bs2)
[array(['test.txt:4'], dtype=object), array(['test line4'], dtype=object)]
>>> sess.run(bs2)
[array(['test.txt:3'], dtype=object), array(['test line3'], dtype=object)]
>>> sess.run(bs2)
[array(['test.txt:2'], dtype=object), array(['test line2'], dtype=object)]
可以看出,上面代码中得bs2输出后,打印出的诗两个Reader的分别输出,这点我倒是挺奇怪,只能日后再研究了。个人感觉是随着Reader个数增加貌似filename_queue里面文件有了新的copy备份,好了今天就这样。有疑问的改日再看,于北京。