2017校招笔试面试总结(挂满辛酸泪)
具体是哪家公司的就不说了,反正我不记得,也没我份。。。。另外,问题是别人的,答案是自己的,不保证是否正确。
1、线程的实现方式有几种?分别是什么?
三种,一种是继承Thread类,一种是实现Runnable接口,第三种是使用ExecutorService、Callable、Future实现有返回结果的多线程(具体分析请移步此处http://blog.csdn.net/aboy123/article/details/38307539,同时感谢评论中BarackHusseinObama的提醒)。
2、java的特点是什么?有哪些特性?
我的回答是:面向对象,主要包含以下三个特性:封装、多态、继承
此外,还有五大基本原则:
(1)单一职责原则(Single-Responsibility Principle,SRP):指一个类的功能要单一,不能包罗万象,如同一个人一样,分配的工作不能太多,否则一天到晚虽然忙忙碌碌,但效率不高。
(2)开放封闭原则(Open-Closed Principle,OCP):一个模块在扩展性方面应该是开放的,而在更改性方面应该是封闭的。比如,一个网络模块,原来只服务端功能,而现在要加入客户端功能。那么应该不用修改服务端代码的前提下,就能够增加客户端功能的实现代码。这要求在设计之初就应当将服务端和客户端分开,公共部分抽象出来。
(3)里氏替换原则(Liskov-Substituent Principe,LSP):子类应当可以替换父类并出现在父类能够出现的任何地方。比如:公司搞年度晚会,所有员工都可以参加抽奖,那么无论是老员工还是新员工,也管是总部员工还是外派员工,都应当可以参加抽奖。
(4)依赖原则(Dependency-Inversion Principle,DIP):具体依赖抽象,上层依赖下层。假设B是较A低的模块,但B需要用到A的功能,这个时候,B不应该直接使用A中的具体类,而应当由B定义一抽象口,并由A来实现这个抽象接口,B只使用这个抽象接口,这样就达到了依赖倒置的目的,B也解除了对A的依赖,反过来是A依赖于B定义的抽象接口,通过上层模块难以避免赖下层模块,加入B也直接依赖A实现,那么就可能造成循环依赖,一个常见的问题就是编译A模块时需要直接包含到B模块的CPP文件,而编译B时同样需要直接包含到A模块的CPP文件。
(5)接口分离原则(the interface Segregation Principe,ISP):模块间要通过抽象接口隔离开,而不是通过具体的类强耦合起来。
该题部分答案来自http://www.cnblogs.com/hnrainll/archive/2012/09/18/2690846.html
3、抽象类可以继承抽象类吗?
可以,抽象类也是类,所以具有类的特性,详情如下:
abstract class A{
abstract void add();
public void delete(){}
}
abstract class B extends A{
//继承了抽象A类,因为也是抽象的,可以不写抽象方法,当然也可以重写抽象方法(切记抽象方法是没有方法体的)
//abstract void add(); //也是没有问题的
abstract void getXX();
}
public class extends B{
//必须实现抽象方法
//继承了B,也就继承了A,A B方法都有,所以必须重写这两个抽象类的抽象方法
public void add(){}
public void delete(){}
public void getXX(){}
}4、接口可以实现接口吗?
不可以,因为接口的成员方法都具有抽象属性,不具有方法体,无法实现继承的接口,但是可以继承接口,并且可以继承多个接口(针对java7而言,java8已允许通过default关键字在接口中实现方法体,下同),如下:
public interface Interface2 extends Interface1,Interface3{
}
5、接口可以继承抽象类吗?
不可以,接口里的方法是不能有方法体的,但抽象类允许方法体,所以会有冲突。但是抽象类可以实现接口。
6、接口和抽象类的区别?
(1)抽象类可以有方法实现,接口完全抽象,不存在方法实现;
(2)抽象类可以有构造器,接口不能有;
(3)抽象类除了不能实例化,其他和普通的java类没有什么区别,接口是完全不同的类型;
(4)抽象类可以有public、protected和default这些修饰符,接口默认public,不允许其他的修饰符;
(5)抽象类可以继承一个类,实现多个方法,接口可以继承一个或多个其他接口;
(6)抽象类速度比接口快,因为接口需要时间去寻找在类中实现的方法。
(7)抽象类可以添加新的方法,可以给该方法提供默认实现,因此可以不需要改变子类。接口一旦添加方法,实现该接口的类也必须改变。
来源:http://www.importnew.com/12399.html7、静态代码块、构造代码块、构造方法、main方法执行顺序
public class StaticCode {
//执行顺序:(优先级从高到低。)静态代码块>main方法>构造代码块>构造方法。
int i = 1;
static int j = 2;
//这是静态代码块:项目启动时初始化,而静态方法则是被调用时初始化
static{
j=3;
//i=1;编译报错
System.out.println("静态代码块1");
}
static{
System.out.println("静态代码块2");
}
//这是构造代码块:实例化对象时执行
{
j=2;
i=3;
System.out.println("构造代码块1");
}
{
System.out.println("构造代码块2");
}
public StaticCode(){
System.out.println("构造方法");
}
public static void main(String[] args) {
System.out.println("main方法");
new StaticCode();
new StaticCode();
}
}运行结果:
静态代码块1
静态代码块2
main方法
构造代码块1
构造代码块2
构造方法
构造代码块1
构造代码块2
构造方法
8、同步的实现方法
(1)同步方法synchronized
由于java的每个对象都有一个内置锁,当使用该关键字修饰方法时,内置锁会保护整个方法。在调用该方法前,需要获得内置锁,否则处于阻塞状态。
代码示例:
public synchronized void synchronizedMethod1(){
}改关键字也可以修饰静态方法,如果调用该静态方法,将会锁住整个类。
(2)同步代码块
被synchronized修饰的代码块,例如:
int account;
public void synchronizedMethod2(){
synchronized (this) {
account= 1000;
}
}同步是一种高开销的操作,因此应该尽量减少同步的内容。通常没必要同步整个方法,使用同步代码块即可。
(3)使用重入锁
JavaSE5.0新增了一个java.util.concurrent包来实现同步
ReentrantLock类是可重入、互斥、实现了Lock接口的锁,他与使用synchronized方法和块具有相同的基本行为和语义,并且扩展了其能力。
ReentrantLock常用方法:
a、ReentrantLock():创建实例;
b、lock():获得锁,c、unlock():释放锁。
9、线程有哪几种状态?
五种:
(1)新建:使用new;
(2)就绪:调用start()方法后的状态;
(3)运行:处于run()方法的状态;
(4)阻塞/等待/睡眠;
(5)死亡:run()完成时,此时调用start()会报错;
状态的转换:
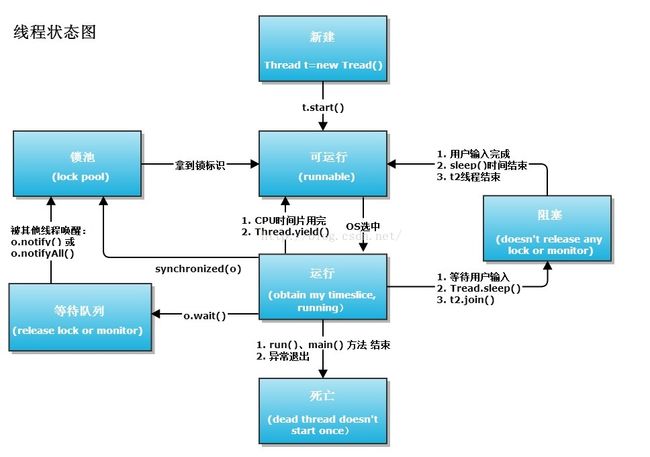
图片来自:https://my.oschina.net/mingdongcheng/blog/139263
10、mysql中InnoDB和MyIsam(默认)的区别
(1)InnoDB支持外键和事务,MyIsam不支持;
(2)InnoDB支持数据行锁定,MyISAM只支持锁定整张表;
(3)InnoDB不支持全文索引FULLTEXT,MyISAM支持;
(4)InnoDB主键范围更大;
(5)MyISAM支持gis数据,InnDB不支持。
(6)MyISAM会保存表的行数,所以select (*) from table;的速度更快,但如果带有where子句,而俩者的操作是一样的。
11、mysql回滚的实现原理
似乎是使用保存点savepoint实现的,后期补充
12、spring事务配置方式
13、String的缓存机制
参见此处(http://blog.csdn.net/tiantiandjava/article/details/46309163)
14、spring的核心是什么?
IOC和AOP
IOC:传统上使用一个对象需要使用new关键字实例化,而使用IOC则允许在配置文件中配置而后注入到对应的类中;
AOP: 面向切面变成,可以在方法前、方法后、实例化前、实例化后做一下操作,如传统的日志记录需要在每个类中做处理,而使用AOP则只需要写一个类,之后配置一下即可
15、mysql隔离机制?
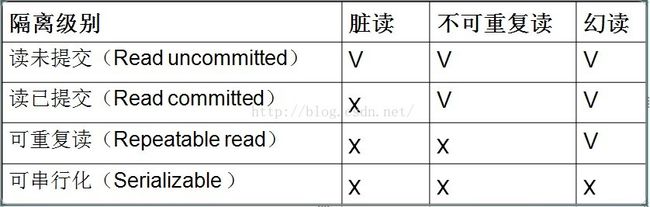
图片来源:http://xm-king.iteye.com/blog/770721
脏读:一个事务未提交,而另一个事务可以读到这部分未提交的数据,而这部分数据由于未提交,可能会回滚;
不可重复读:事务A先查询一遍,之后事务B提交,事务A在查询,发现数据被更改;
幻读:幻读,是指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。同时,第二个事务也修改这个
表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好象发生了幻觉一样.
16、事务的特性
(1)原子性:要么都完成,要么都不完成;
(2)一致性:事务完成前后数据的完整性保持不变(如外键不会被破坏);
(3)隔离性:当多个事务同时操作数据库时,可能存在并发现象,此时应保持事务之间隔离,彼此不受影响;
(4)持久性:事务一旦提交,那么改变的数据就是永久的,不能再回滚。
17、拼接字符串有哪些方式?
http://blog.csdn.net/kimsoft/article/details/3353849
18、如何在http头中指定缓存?
http中缓存主要是以下内容:
(1)Expires和Cache-Control
Expires: Sun, 16 Oct 2016 05:43:02 GMT(绝对时间)
Cache-Control: max-age:600(相对时间,解决上述设置由于客户端时间设置引起的问题)
(2)Last-Modifed和If-Modify-since
客户端第一次访问资源的时候,服务端返回资源内容的同时返回了Last-Modifed:Wed, 07 Aug 2013 15:32:18 GMT
服务端在告诉客户端:你获取的这个文件我最后的修改时间是Wed, 07 Aug 2013 15:32:18 GMT 。浏览器在获取这个文件存到缓存中的时候,给缓存中的文件同时记录上这个最后修改时间。
第二次访问的时候(我们假设这里没有设置expires或者cache-control)。那么客户端访问资源的时候会带上If-Modify-since:Wed, 07 Aug 2013 15:32:18 GMT ;
客户端询问服务端:喂,我需要的这个资源其实我这边已经有缓存了,我的缓存文件的最后修改时间是这个,如果你那边的资源在这个时间以后没有修改的话,你就告诉我一下就好了,不需要返回实际的资源内容。反之,要是你有修改的话,你就把文件内容返回给我吧。
服务端回应说:哦。行为是看下资源是否在这个时间后没有修改过,如果没有修改返回个304告诉客户端,我没有修改过。如果有变化了,我就返回200,并且带上资源内容。
(3)ETag和If-None-Match
第一次客户端访问资源的时候,服务端返回资源内容的同时返回了ETag:1234,告诉客户端:这个文件的标签是1234,我如果修改了我这边的资源的话,这个标签就会不一样了。
第二次客户端访问资源的时候,由于缓存中已经有了Etag为1234的资源,客户端要去服务端查询的是这个资源有木有过期呢?所以带上了If-None-Match: 1234。告诉服务端:如果你那边的资源还是1234标签的资源,你就返回304告诉我,不需要返回资源内容了。如果不是的话,你再返回资源内容给我就行了。服务端就比较下Etag来看是返回304还是200。
(4)各种刷新
理解了上面的缓存标签之后就很好理解各种刷新了。
刷新有三种
a、浏览器中写地址,回车
b、F5
c、Ctrl+F5
假设对一个资源:
浏览器第一次访问,获取资源内容和cache-control: max-age:600,Last_Modify: Wed, 10 Aug 2013 15:32:18 GMT
于是浏览器把资源文件放到缓存中,并且决定下次使用的时候直接去缓存中取了。
浏览器url回车
浏览器发现缓存中有这个文件了,好了,就不发送任何请求了,直接去缓存中获取展现。(最快)
下面我按下了F5刷新
F5就是告诉浏览器,别偷懒,好歹去服务器看看这个文件是否有过期了。于是浏览器就胆胆襟襟的发送一个请求带上If-Modify-since:Wed, 10 Aug 2013 15:32:18 GMT
然后服务器发现:诶,这个文件我在这个时间后还没修改过,不需要给你任何信息了,返回304就行了。于是浏览器获取到304后就去缓存中欢欢喜喜获取资源了。
但是呢,下面我们按下了Ctrl+F5
这个可是要命了,告诉浏览器,你先把你缓存中的这个文件给我删了,然后再去服务器请求个完整的资源文件下来。于是客户端就完成了强行更新的操作...
注意:那个ETag实际上很少人使用,因为它的计算是使用算法来得出的,而算法会占用服务端计算的资源,所有服务端的资源都是宝贵的,所以就很少使用etag了。
本题来源:http://www.cnblogs.com/yjf512/p/3244882.html
设置缓存的方式如下:
- response.setHeader("Pragma","No - cache");
- response.setHeader("Cache - Control","no - cache");
- response.setDateHeader("Expires",0)
19、java是按值传递还是按地址传递?
原生类型按值传递,自定义类型按地址传递
此外:
a、“在Java里面参数传递都是按值传递”这句话的意思是:按值传递是传递的值的拷贝,按引用传递其实传递的是引用的地址值,所以统称按值传递。
b、在Java里面只有基本类型(包括其包装类)和按照下面这种定义方式的String是按值传递,其它的都是按引用传递。就是直接使用双引号定义字符串方式:String str = “Java私塾”;
示例1(基础数据封装类):
public class Main {
public static void main(String[] args) {
Integer integer = 10;
test(integer);
System.out.println(integer);
}
private static void test(Integer integer) {
// TODO Auto-generated method stub
integer = 20;
}
}输出10
示例2(自定义类):
public class Main {
public static void main(String[] args) {
A a = new A();
a.a = 10;
test(a);
System.out.println(a.a);
}
private static void test(A a) {
// TODO Auto-generated method stub
a.a = 20;
}
}
class A{
int a;
}解决示例2因为按地址传递导致结果被改变的方法:在test方法中重新new对象:
public class Main {
public static void main(String[] args) {
A a = new A();
a.a = 10;
test(a);
System.out.println(a.a);
}
private static void test(A a) {
// TODO Auto-generated method stub
a = new A();
a.a = 20;
}
}
class A{
int a;
}输出10
20、js定义一个对象
http://group.cnblogs.com/topic/37998.html
21、以下俩行代码有何区别:
public class Main {
private static final int a = 10;
private static final int b = 11;
private static int c = 10;
private static int d = 11;
public static void main(String[] args) {
int e = a + b; //1
int f = c + d; //2
}
}22、九种基本类型大小及封装类

虽然定义了boolean这种数据类型,但是只对它提供了非常有限的支持。在Java虚拟机中没有任何供boolean值专用的字节码指令,Java语言表达式所操作的boolean值,在编译之后都使用Java虚拟机中的int数据类型来代替,而boolean数组将会被编码成Java虚拟机的byte数组,每个元素boolean元素占8位”。这样我们可以得出boolean类型占了单独使用是4个字节,在数组中又是1个字节。
文字来自:http://blog.csdn.net/syc434432458/article/details/49964089
23、switch能否用string做参数:
Cannot switch on a value of type boolean. Only convertible int values, strings or enum variables are permitted
从上面的话中可以看出,switch只支持byte、char、int、string(1.6及之前不支持string)、short、enum,而不支持long、double、float、boolean
24、equals和等号的区别?
前者比较内容,后者比较地址
25、object有哪些公用方法?
equals、hashcode、wait、notify、notifyAll、clone、getClass
26、 Java的四种引用,强弱软虚,用到的场景。
强引用:不会被gc回收,平常使用的便是强引用,如Object object = new Object();就是;
软引用:内存空间足够,垃圾回收器就不会回收它,如果内存空间不足了,就会回收这些对象的内存
弱引用:一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存
虚引用(幽灵引用):发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列
强弱次序:强>软>弱>虚
注:可通过System.gc();提醒虚拟机执行垃圾回收,但虚拟机未必会执行。
来源:http://blog.csdn.net/u011860731/article/details/48714321
27、hashcode方法的作用
hashCode方法的主要作用是为了配合基于散列的集合一起正常运行,这样的散列集合包括HashSet、HashMap以及HashTable。(因为equals方法代价比较大)
28、ArrayList、LinkedList、Vector的区别。
ArrayList 是一个可改变大小的数组.当更多的元素加入到ArrayList中时,其大小将会动态地增长.内部的元素可以直接通过get与set方法进行访问,因为ArrayList本质上就是一个数组.
LinkedList 是一个双链表,在添加和删除元素时具有比ArrayList更好的性能.但在get与set方面弱于ArrayList.
当然,这些对比都是指数据量很大或者操作很频繁的情况下的对比,如果数据和运算量很小,那么对比将失去意义.
Vector 和ArrayList类似,但属于强同步类。如果你的程序本身是线程安全的(thread-safe,没有在多个线程之间共享同一个集合/对象),那么使用ArrayList是更好的选择。
Vector和ArrayList在更多元素添加进来时会请求更大的空间。Vector每次请求其大小的双倍空间,而ArrayList每次对size增长50%.
而 LinkedList 还实现了 Queue 接口,该接口比List提供了更多的方法,包括 offer(),peek(),poll()等.
注意: 默认情况下ArrayList的初始容量非常小,所以如果可以预估数据量的话,分配一个较大的初始值属于最佳实践,这样可以减少调整大小的开销。
来源:http://blog.csdn.net/renfufei/article/details/17077425
29、String、StringBuffer与StringBuilder的区别。
性能上来讲:StringBuilder>StringBuffer>String
原因:
String内部定义如下:
/** The value is used for character storage. */
private final char value[];
/** The offset is the first index of the storage that is used. */
private final int offset;
/** The count is the number of characters in the String. */
private final int count; StringBuffer是线程安全的,StringBuilder是线程不安全的。
使用策略:
(1)基本原则:如果要操作少量的数据,用String ;单线程操作大量数据,用StringBuilder ;多线程操作大量数据,用StringBuffer。
(2)不要使用String类的"+"来进行频繁的拼接,因为那样的性能极差的,应该使用StringBuffer或StringBuilder类,这在Java的优化上。
是一条比较重要的原则
(3)为了获得更好的性能,在构造 StringBuffer 或 StringBuilder 时应尽可能指定它们的容量。
来源:http://blog.csdn.net/kingzone_2008/article/details/9220691