利用Tensorflow的队列多线程读取数据
利用Tensorflow的队列多线程读取数据
在tensorflow中,有三种方式输入数据1.利用feed_dict送入numpy数组
2.利用队列从文件中直接读取数据
3.预加载数据
其中第一种方式很常用,在tensorflow的MNIST训练源码中可以看到,通过feed_dict={},可以将任意数据送入tensor中。
第二种方式相比于第一种,速度更快,可以利用多线程的优势把数据送入队列,再以batch的方式出队,并且在这个过程中可以很方便地对图像进行随机裁剪、翻转、改变对比度等预处理,同时可以选择是否对数据随机打乱,可以说是非常方便。该部分的源码在tensorflow官方的CIFAR-10训练源码中可以看到,但是对于刚学习tensorflow的人来说,比较难以理解:
1.使用tf.train.string_input_producer函数把我们需要的全部文件打包为一个tf内部的queue类型,之后tf开文件就从这个queue中取目录了,要注意一点的是这个函数的shuffle参数默认是True,也就是你传给他文件顺序是1234,但是到时候读就不一定了,我一开始每次跑训练第一次迭代的样本都不一样,还纳闷了好久,就是这个原因。
首先,把CIFAR-10的测试集文件读取出来,生成文件名列表。
path = 'E:\Dataset\cifar-10\cifar-10-batches-py'
filenames = [os.path.join(path, 'data_batch_%d' % i) for i in range(1, 6)]"""
os.path.join()函数
语法: os.path.join(path1[,path2[,......]])
返回值:将多个路径组合后返回
注:第一个绝对路径之前的参数将被忽略
"""
有了列表以后,利用tf.train.string_input_producer函数生成一个读取队列
搞一个reader,不同reader对应不同的文件结构,比如度bin文件tf.FixedLengthRecordReader就比较好,因为每次读等长的一段数据。如果要读什么别的结构也有相应的reader。
filename_queue = tf.train.string_input_producer(filenames)3.用reader的read方法,这个方法需要一个IO类型的参数,就是我们上边string_input_producer输出的那个queue了,reader从这个queue中取一个文件目录,然后打开它经行一次读取,reader的返回是一个tensor(这一点很重要,我们现在写的这些读取代码并不是真的在读数据,还是在画graph,和定义神经网络是一样的,这时候的操作在run之前都不会执行,这个返回的tensor也没有值,他仅仅代表graph中的一个结点)。
对这个tensor做些数据与处理,比如CIFAR1-10中label和image数据是糅在一起的,这里用slice把他们切开,切成两个tensor(注意这个两个tensor是对应的,一个image对一个label,对叉了后便训练就完了),然后对image的tensor做data augmentation。
接下来,我们调用read_cifar10函数,得到一幅一幅的图像,该函数的代码如下:
def read_cifar10(filename_queue):
label_bytes = 1
IMAGE_SIZE = 32
CHANNELS = 3
image_bytes = IMAGE_SIZE*IMAGE_SIZE*3
record_bytes = label_bytes+image_bytes
# define a reader
reader = tf.FixedLengthRecordReader(record_bytes)
key, value = reader.read(filename_queue)
record_bytes = tf.decode_raw(value, tf.uint8)
label = tf.strided_slice(record_bytes, [0], [label_bytes])
depth_major = tf.reshape(tf.strided_slice(record_bytes, [label_bytes],
[label_bytes + image_bytes]),
[CHANNELS, IMAGE_SIZE, IMAGE_SIZE])
image = tf.transpose(depth_major, [1, 2, 0])
return image, label第9行,定义一个reader,来读取固定长度的数据,这个固定长度是由CIFAR-10数据集图片的存储格式决定的,1byte的标签加上32 *32 *3长度的图像,3代表RGB三通道,由于图片的是按[channel, height, width]的格式存储的,为了变为常用的[height, width, channel]维度,需要在17行reshape一次图像,最终我们提取出了一副完整的图像与对应的标签
对图像进行预处理
我们取出的image与label均为tensor格式,因此预处理将变得非常简单
if not distortion:
IMAGE_SIZE = 32
else:
IMAGE_SIZE = 24
# 随机裁剪为24*24大小
distorted_image = tf.random_crop(tf.cast(image, tf.float32), [IMAGE_SIZE, IMAGE_SIZE, 3])
# 随机水平翻转
distorted_image = tf.image.random_flip_left_right(distorted_image)
# 随机调整亮度
distorted_image = tf.image.random_brightness(distorted_image, max_delta=63)
# 随机调整对比度
distorted_image = tf.image.random_contrast(distorted_image, lower=0.2, upper=1.8)
# 对图像进行白化操作,即像素值转为零均值单位方差
float_image = tf.image.per_image_standardization(distorted_image)distortion是定义的一个输入布尔型变量,默认为True,表示是否对图像进行处理
填充队列与随机打乱
调用tf.train.shuffle_batch或tf.train.batch函数,以tf.train.shuffle_batch为例,函数的定义如下:
def shuffle_batch(tensors, batch_size, capacity, min_after_dequeue,
num_threads=1, seed=None, enqueue_many=False, shapes=None,
allow_smaller_final_batch=False, shared_name=None, name=None):通常情况下,我们只需要输入以上几个变量即可,在CIFAR-10_input.py中,谷歌给出的代码是这样写的:
if shuffle:
images, label_batch = tf.train.shuffle_batch([image, label], batch_size, min_queue_examples+3*batch_size,
min_queue_examples, num_preprocess_threads)
else:
images, label_batch = tf.train.batch([image, label], batch_size,
num_preprocess_threads,
min_queue_examples + 3 * batch_size)min_queue_examples由以下方式得到:
#确保随机乱序有好的混合效果
min_fraction_of_examples_in_queue = 0.4
min_queue_examples = int(NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN
*min_fraction_of_examples_in_queue)当然,这些值均可以自己随意设置,
最终得到的images,labels(label_batch),即为shape=[128, 32, 32, 3]的tensor,其中128为默认batch_size。
激活队列与处理异常
得到了images和labels两个tensor后,我们便可以把这两个tensor送入graph中进行运算了
# input tensor
img_batch, label_batch = cifar10_input.tesnsor_shuffle_input(batch_size)
# build graph that computes the logits predictions from the inference model
logits, predicts = train.inference(img_batch, keep_prob)
# calculate loss
loss = train.loss(logits, label_batch)
定义sess=tf.Session()后,运行sess.run(),然而你会发现并没有输出,程序直接挂起了,仿佛死掉了一样
原因是这样的,虽然我们在数据流图中加入了队列,但只有调用tf.train.start_queue_runners()函数后,数据才会动起来,被负责输入管道的线程填入队列,否则队列将会挂起。
OK,我们调用函数,让队列运行起来
with tf.Session(config=run_config) as sess:
sess.run(init_op) # intialization
queue_runner = tf.train.start_queue_runners(sess)
for i in range(10):
b1, b2 = sess.run([img_batch, label_batch])
print(b1.shape)在这里为了测试,我们取10次输出,看看输出的batch1的维度是否正确。
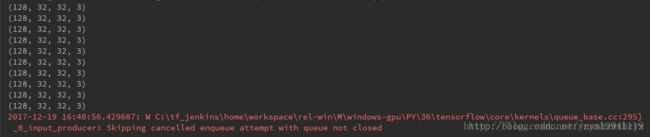
10个batch的维度均为正确的,但是tensorflow却报了错,错误的文字内容如下:
2017-12-19 16:40:56.429687: W C:\tf_jenkins\home\workspace\rel-win\M\windows-gpu\PY\36\tensorflow\core\kernels\queue_base.cc:295] _ 0 _ input_producer: Skipping cancelled enqueue attempt with queue not closed
简单地看一下,大致意思是说我们的队列里还有数据,但是程序结束了,抛出了异常,因此,我们还需要定义一个Coordinator,也就是协调器来处理异常
Coordinator有3个主要方法:
- tf.train.Coordinator.should_stop() 如果线程应该停止,返回True
- tf.train.Coordinator.request_stop() 请求停止线程
- tf.train.Coordinator.join() 等待直到指定线程停止
首先,定义协调器
coord = tf.train.Coordinator()将协调器应用于QueueRunner
queue_runner = tf.train.start_queue_runners(sess, coord=coord)结束数据的训练或测试后,关闭线程
coord.request_stop()
coord.join(queue_runner)最终的sess代码段如下:
coord = tf.train.Coordinator()
with tf.Session(config=run_config) as sess:
sess.run(init_op)
queue_runner = tf.train.start_queue_runners(sess, coord=coord)
for i in range(10):
b1, b2 = sess.run([img_batch, label_batch])
print(b1.shape)
coord.request_stop()
coord.join(queue_runner)得到的输出结果为:
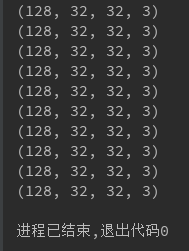
完美解决,利用img_batch与label_batch,把tensor送入graph中,就可以享受tensorflow带来的训练乐趣了
注意:
在这个过程中,有以下几点需要留意:
1.tf.decode_raw()解析出的数据是没有shape的,因此需要调用set_shape()函数来给出tensor的维度。
2.read_and_decode()函数返回的是单个的数据,但是后边的tf.train.shuffle_batch()却能够生成批量数据。
参考文献:
利用Tensorflow的队列多线程读取数据 - CSDN博客 http://blog.csdn.net/zym19941119/article/details/78890490
tensorflow的数据输入 - CSDN博客 http://blog.csdn.net/zzk1995/article/details/54292859