Python 数据分析微专业课程--项目03 视频网站数据清洗整理和结论研究
1.项目说明
- 读取爱奇艺网站数据,对数据进行清洗和整理,分析不同导演电影的好评率,
- 对2001-2016电影影评人数分析,筛选出当年热门电影
2.项目具体要求
- 数据清洗 - 去除空值;时间标签转化
- 分析出不同导演电影的好评率,并筛选出TOP20
- 统计分析2001-2016年每年评影人数总量,分析每年人数变化规律,筛选查看异常值,看异常值是否是当年热门电影
3.实现思路:
- 数据清洗:对空值进行填充,数值型字段填充0,非数值型字段填充’缺失数据’;时间字段格式为’xxxx年xx月xx日’,可以使用datetime.datetime.strptime()方法转化为时间标签。
- 查看数据可知数据是按天获取了一个月的视频数据,因此数据有重复,所以需要筛选出每一部视频最后获取日期的数据。
可以根据剧名取最大值,获取各剧最后日期的数据,然后根据导演分组求’好评数’和’评分人数’的总数,即可计算得到好评率。
根据上映年份分组统计该年份评分人数总数,用该数据绘制面积图,可查看每个年份评分人数总数的变化情况。 - 筛选热门影片可以采用筛选出当年评分人数的异常值,即评分人数特别多的影片。可以先循环绘制各个年份影片评分人数的箱型图。
来查看异常数据的大致情况。然后筛选数各个年份中评分人数超过上外限区间的影片,即可得到当年的热门影片。
4.实现过程:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import warnings
import matplotlib
import datetime
import os
warnings.filterwarnings('ignore')
os.chdir('c://test')
data= pd.read_csv('爱奇艺视频数据.csv',engine = 'python',encoding = 'gbk')
#数据清洗 - 去除空值
#要求:创建函数
#提示:fillna方法填充缺失数据,注意inplace参数
def fillnull(df):
cols = df.columns
for col in cols:
if df[col].dtype =='object':
df[col].fillna('缺失数据',inplace = True)
else:
df[col].fillna(0,inplace = True)
return df
df_c = fillnull(data)
#数据清洗 - 时间标签转化
#① 将时间字段改为时间标签
#② 创建函数
def transformToDate(s):
return s.apply(lambda x:datetime.datetime.strptime(x,'%Y年%m月%d日'))
df_c['数据获取日期'] = transformToDate(df_c['数据获取日期'])
说明:该项目的数据清洗有两个要求,除了常见的缺失数据清洗,还有对不符合日期格式的数据进行处理,
使之转换为日期标签格式,这样就可以用于后面的计算。
df_s = df_c[['导演','数据获取日期','上映年份','评分人数','整理后剧名','好评数']]
df_m = df_s.groupby(by = '整理后剧名').max().reset_index()
#根据导演分组计算好评率
comment_df = df_m.groupby(by = '导演').sum()
comment_df['好评率'] = comment_df['好评数']/comment_df['评分人数']
#获得好评率top20
comment_top = comment_df.sort_values(by = '好评率',ascending= False).iloc[:20]
#图表可视化
fig1 = plt.figure(num = 1,figsize = (15,8))
comment_top['好评率'].plot(kind = 'bar',title = '不同导演电影的好评率',color = 'c',rot = 60)
plt.ylim([0.975,1])
plt.yticks(np.linspace(0.98,1,5))
plt.grid(linestyle = '--')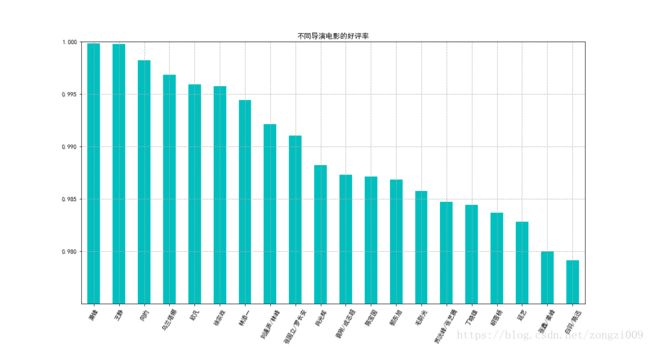
说明:根据不同导演好评柱状图发现TOP20的导演的好评率都达到98%,差距较小。
从数据分析的角度来看需要注意以下几点:
1.一个导演的好评率行业平均一般是多少,这么高的好评率是否有问题,这个需要从两方面来分析:
第一:数据准确性(刷数据?);
第二:统计量是否合适;
2.分析导演相关问题,是否有其他更加合适统计量
#计算统计出2001-2016年每年评影人数总量
comment_year = df_m[(df_m['上映年份']>=2001)&(df_m['上映年份']<=2016)].drop('数据获取日期',axis = 1)
comment_group = comment_year.groupby('上映年份')[['评分人数']].sum()
#制作面积图,分析每年人数总量变化规律
fig2 = plt.figure(num = 2,figsize = (13,8))
comment_group[['评分人数']].plot.area(alpha = 0.8,color = 'lightblue',figsize = (13,8))
plt.title('2001-2016年每年影评人数总量统计')
plt.xticks(comment_group.index)
plt.xlim([2001,2016])
#验证是否有异常值(极度异常)
fig3,axs = plt.subplots(4,4,figsize = (13,18),)
n = 2001
for i in range(4):
for j in range(4):
g= comment_year1.loc[comment_year1['上映年份'] == n]
g[['评分人数','好评数']].boxplot(sym = 'o',whis = 3,ax =axs[i,j])
axs[i,j].set_title('%i' % n)
n+=1
plt.tight_layout(3)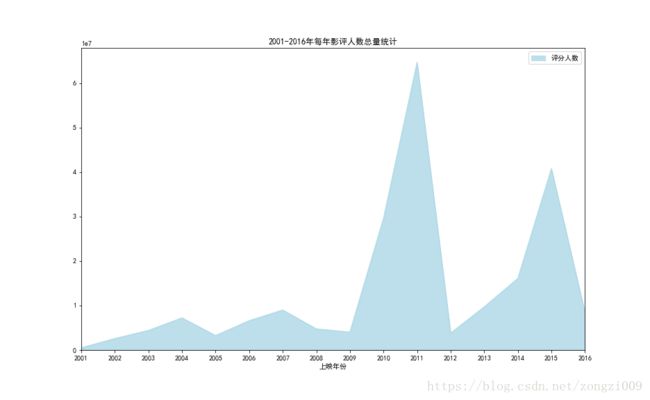

说明:面积图非常直观的反映每年度评影人数总量的变化情况,这里可以发现评影人数在2011,2015年由两个峰值,
可以说明这两年有比较多的热门剧,或者有非常热门的剧出现。
创建子图,再循环绘制各年度评分人数和好评数的箱型图,可以查看各年度评分人数的分布情况,以及异常值情况。
由各年度箱型图发现在2011年和2015年有都有比较多的异常值,且异常值数值都较大。与面积图的情况相符
#创建函数获外限最大和最小区间
def get_limits(df,loc):
q1 = df[loc].quantile(0.25)
q3 = df[loc].quantile(0.75)
iqr = q3 - q1
lim_max = q3+3*iqr
lim_min = q1-3*iqr
return (lim_max,lim_min)
#筛选异常值,同过评分人数中的异常值,超过外限最大区间的为当年热门电影
for i in range(2001,2017):
data_year = comment_year1[comment_year1['上映年份'] ==i] #获得该年份上映的数据
loc = '评分人数' #以评分人数作为判定标准
m = get_limits(data_year,loc) #获得上下限区间
overLim_list = data_year[data_year['评分人数']>m[0]] #评分人数大于上限区间的异常值数据
print('%i年一共有%i条数据:' % (i,len(overLim_list)))
print(overLim_list,'\n\n\n ----------')说明:这里将以超过外限区间的值为异常值,区间计算:最大值区间Q3+3IQR,最小值区间Q1-3IQR (IQR=Q3-Q1)
超过最大值区间的数据评分人数都比较多,可视为热门电影,这里是采用根据年度进行循环筛选,筛选出当年的热门影视剧。
查看筛选出来的影视剧可知这些剧都为当年比较热门的影视剧。2011年的非常热门影视剧是:宫锁心玉, 回家的诱惑.
也可以对热门影视剧的类型进行分析,看哪些类型的影视剧容易成3为热门
5.总结
- 知识点上这个项目主要还是考查对pandas,numpy,matplotlib的使用,特别是对异常值的查看和筛选。
- 通过对该项目的完成对数据分析的实际运用有了新的认识,就是如何运用对数据异常值来分析热门的事物。