python高级—— 从趟过的坑中聊聊爬虫、反爬、反反爬,附送一套高级爬虫试题
前言:
时隔数月,我终于又更新博客了,然而,在这期间的粉丝数也就跟着我停更博客而涨停了,唉
是的,我改了博客名,不知道为什么要改,就感觉现在这个名字看起来要洋气一点。
那么最近到底咋不更新博客了呢?说起原因那就多了,最主要的还是没时间了,是真的没时间,前面的那些系列博客都还没填坑完毕的(后续都会填上的)
最近有点空余就一直在开发我的项目,最近做了两个项目:
IPproxy,看名字就知道啦,就是一个ip代理池,爬取了各大免费的代理网站,然后检测可用性, github地址 相关的介绍github上已经说明了
get_jobs,爬取了几十个招聘类网站的数据, github地址 同样的,相关的介绍github上已经说明了
根据以上爬取的大概也许可能接近上百个网站吧,加上我初学爬虫的时候爬的网站,现在也算是爬了有接近上千个网站了,对爬虫也算是小有心得了,下面就开始说说吧
以下是总结式的解析,个人觉并不太适合零基础的朋友,也不会有过多的图文展示,当然我也会尽量的把问题说清楚点,而且我也不是爬虫大佬,只是根据最近的爬虫经历总结出的经验,我确实不太建议零基础的朋友往下看,你可以先看看我之前的博客文章或者看其他大神的文章之后再来看我这篇,因为爬虫涉及了前端和后端还有前后端之间的交互等的技术,一些底层的原理之类的,不是说不给零基础的朋友看,是如果没这些知识做基础可能看不懂(不是瞧不起小白的意思,我也是小白过来的)。当然爬虫界的大佬们如果偶然点开,那还请多多包涵,我目前技术确实还有待提升
爬虫前提:
1.法律问题
最近时不时总是冒出一两个因为爬虫入狱的新闻



不一一截图了,自己网上搜吧,其实现在越来越多了
有朋友要说,“为什么我学个爬虫都被抓吗?我犯法了吗?” 这个目前还真的不好说,主要是什么,目前爬虫相关的就只有一个robots协议,而我们都知道robots协议是针对于通用爬虫而言的,而聚焦爬虫(就是我们平常写的爬虫程序)则没有一个严格法律说禁止什么的,但也没有说允许,所以目前的爬虫就处在了一个灰色地带,而很多情况下是真的不好判定你到底是违法还是不违法的。 好消息是,据说有关部门正在起草爬虫法,不久便会颁布,后续就可以按照这个标准来进行了。
2.爬虫分类:
上面说了,有通用爬虫和聚焦爬虫
通用爬虫:
针对于百度,搜狗,谷歌这类搜索引擎类的爬虫程序
聚焦爬虫:
又名定向爬虫,就是我们平时写的针对某个需求或者某个问题而写的程序
3.爬虫能爬什么数据:
一句话, 所见即所得 ,什么意思,你用浏览器能访问,能查看的网页数据,用爬虫就可以爬到,反过来,你浏览器都无法访问的,爬虫是无法爬到的,除非你用一些违法的手段获取到
举个例子:
- 你用浏览器打开百度,打开淘宝,可以看到的一切数据,爬虫都可以获取到
- 你有优酷的vip账号,你可以用浏览器看vip视频,那么爬虫也可以获取到
- 你没有优酷的vip账号,你无法查看vip视频,爬虫也就无法获取到
我知道有一部分圈子里的朋友之间流传着有什么破解vip之类的,那种其实也是符合所见所得的,你没有vip,别人有啊,假如一个已有vip账号的人把视频下载下来上传到云服务器A,然后你访问某个网站,网站后台请求的是云服务器A,最后呈现视频数据给你,不说了,扯远了
爬虫工具:
一.工具分类:
分类看以什么分了,有自动的,有手动的,有在线的,有离线的,有傻瓜式的,有非傻瓜式的,有分析辅助为主的,有自开发式的,看每个人怎么定义了
傻瓜式的:
比如什么 八爪鱼,爬山虎 ,啥啥的一大堆,在线的傻瓜式的工具,根据提示点点鼠标,输入几个字就完了,但是这种工具普遍得到的结果不是很理想
分析类的:
以下的都是作为辅助分析整个请求过程的工具
- fiddler :常用的抓包分析工具
- charles:和fiddler类似,优点是可以自定义上下行网速、代理、反向代理,且配置简单、可解析AMF协议数据
- wireshark:网络封包分析软件,功能非常强大,但是在爬虫层面来说,辅助的意义不算大
- burpsuite:类似fiddler,但是功能更多更具体,且这个包在网络安全行业来说是个必不可少的大杀器
- .......
而需要点技术的就是自开发式的,比如自己借助某个开发语言写爬虫程序(或者说脚本)就是了
二.自开发式的哪些开发语言可以作为爬虫
其实还挺多的
- php
- javascript —— node.js
- java
- python
- golang
php写爬虫是可以的,但是多线程多进程不太支持,所以针对大型一点的项目不够理想
nodejs的curl工具也是可以写爬虫的,有什么优缺点我暂时不知道,我没用过
java的话,听大佬说的,写出来的爬虫程序很臃肿,不是说不好哈,我暂时只是有耳闻,没用过
golang天生支持高并发,性能提升很多,也可以做爬虫,这个我暂时只是有耳闻,没用过
python的话写爬虫真的是一种神器般的存在,目前网上的爬虫程序,可能百分之八九十都是用Python写的
其他语言只要支持网络服务应该都可以写爬虫,这里就不多说了
三.python的哪些相关的工具可以写爬虫
自带的库:
python2下:
- urllib
- urllib2
- urllib3
- httplib
- htttplib2
- re
- ......
python3下:
- urllib
第三方的库:
- requests
- crawley
- protia
- newspaper
- pyspider
- python-goose
- scripy
- scripy-redis
其他相关的库:
- lxml
- json
- beautifulsoup
- re
- pyquery
- execjs
- js2py
目前就想到这么多
平常的话,做网络交互我就用requests库,但是有些小问题,用多了的人应该都知道,requests库里的异常类不够全,有时候报错了无法捕获
做数据解析的话我用 json,re , lxml, beautifulsoup,pyquery,execjs,js2py 都有在用,只要有场景需要就会用
大型项目就上 scripy ,需要分布式就上 scripy-redis
四.爬虫中常见的问题,常见的反爬机制
其实我之前转载过一篇爬虫相关的文章 打造一个健壮高效的网络爬虫 ,转载的爬虫大佬崔庆才的文章,他的文章总结性就非常强了,各种层面都涉及了,我还要自己再写一篇的原因就是,下面的问题真的是我亲身经历的问题,以下的有些问题很可能对有些老哥还说不算问题,各有各的开发思路,按照我那样的思路也许就会遇到这些问题,一来是做个记录,二来是帮助那些遇到跟我同样问题的朋友。
重头戏终于来了,哈哈,我也有点按奈不住了
1.请求头之User-agent
这个稍微接触过一点点爬虫的应该都不陌生,不是说接触Python爬虫,不管你用什么开发语言来写爬虫,应该都会用到这个。大概解释一下,就是一个身份的象征,这个可以用浏览器自带的调试工具查看,访问一个网站的时候,按f12键或者鼠标右键打开调试(有的浏览器叫检查,或者查看元素),然后切换到network(网络),重新刷新一次网站,就会出现所有的请求,随机点击一个,右边出现的就是请求头信息了,如下,这是我访问某某网站的,我使用的浏览器是火狐,然后图上标注的就是user-agent
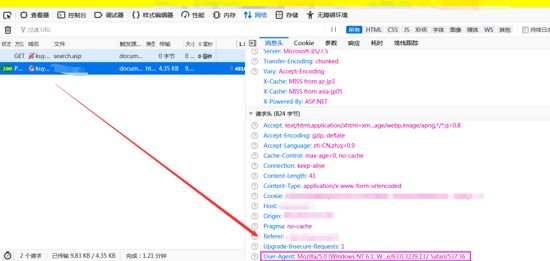
具体怎么用呢?
比如:
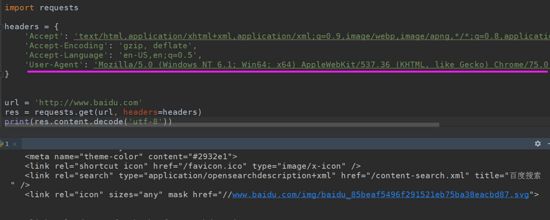
这样就可以带上UA了
如果不带的话,你的目标网站服务端是可以检测到是浏览器还是爬虫工具在访问数据的,就看你的目标网站的友好度了,如果反爬机制做的很高效,到这里你就被ban了
2.调试工具之痛
很多时候我们为了查看网页的DOM结构可能就直接用浏览器自带的调试工具(就是上面说的按f12键)来查看,这个的话,大部分网页是可以应对的,但是,少部分网站用调试工具查看的DOM结构和整个网页的源码是不一致的,说个最近的事,我爬某视频网站,调试工具打开他在每个重要信息都加了一个css样式,这个css样式是通过定位某个html标签(假设为标签)设置上的,我解析网页的时候就很痛苦,调了很久,就是得不到结果,最后发现这个span标签是用js拼接上的,换句话说,服务端回应的是不带有这个span标签的,所以就要没有这个span标签来处理。说这么多不知道看官您能不能理解,遇到过这个问题的朋友应该明白我在说什么
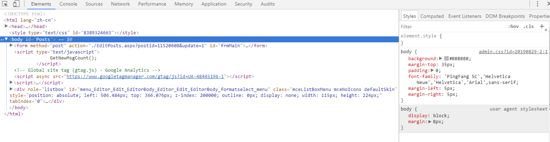
3.异步请求
上面说的DOM结构不一致还有一种可能,就是前后端用的Ajax 异步请求 的,所以你打开浏览器的调试工具查看DOM结构和你用Python获取的结果也是不一致的,这个相信会玩爬虫的老哥们都不陌生
4.请求头之Cookies
有一部分网站,当你访问首页时,会自动设置一个cookie,然后访问同站下的其他页面就会验证这个字段,如果不匹配就会禁止访问
如下,访问百度都会自动设置一些cookie:

5.请求头之特殊字段
特殊字段是什么呢,就是某网站特有的一些字段,比如以下的boss直聘网:
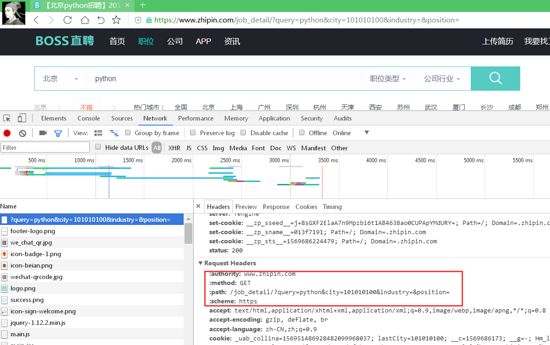
会带有这些特殊的字段。当然这里只是举个例子,,经过我的测试,我圈出来的那几个[:method]等的字段其实请求的时候是不用带上的
6.请求头之Referer
这个referer是干嘛的呢?首先该字段的值都是上一级网站的url,根据我的理解,它有以下作用:
1.做前端的朋友知道,可以借用这个字段直接返回到上个页面
2.还可以通过这个追踪流量来源,比如某某公司在百度上做了SEO(打了个推广广告),当用户通过百度点进来的话,就可以通过referer追踪来源,对用户做进一步的行为分析
3.检测来源的合法性,因为都可以知道通过某某url路径过来的,那么就可以判断来源是否合法,如果异常的话就可以做拦截请求等等的

有的网站就是因为有这个验证,所以返回的数据不正常,带上就OK了。还有的网站更奇怪,你不带上也不会报错,返回的数据也是希望的数据,但是无法和页码匹配,比如你请求的是第一页的数据,它有可能返回的是第5页的数据。遇到过这个问题的老哥应该知道我在说什么
7.请求头之accept:
不知道老哥您遇到过这个问题没有,在请求头里,如果服务端返回的结果是普通的html页面的话,值就应该是如下的:
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
如果返回的是json字符串(返回json字符串的话,往往是属于异步请求)的话,值就应该是这个:
'Accept': 'application/json, text/javascript, */*; q=0.01',
这个不知道你们有没有体会,反正我记得我爬某网站的时候,因为都通用的同一个请求头,有的网站就是返回json数据,我怎么改代码都无法得到正确的值,就是因为本来是json字符串的我的accept用的上面的html页面用的,导致返回数据不符合事实。
8.请求头之 Connection

这个字段字面意思就是http连接嘛,http链接最根本的就是tcp/ip连接了,什么三次握手,四次握手之类的,这些就不展开了,要说就占篇幅了。我们都知道,http请求属于短连接,访问就有,关闭浏览器就会自动断开的,这种就是短连接,对应的长连接就是websocket,这个就不展开了,自行百度了。这个Connection字段有两个值,一个是 keep-alive,一个是close,keep-alive的话往往就跟前面的带有cookie相关,他会保存session会话(如果关闭浏览器的话就没了,有的网站是保存一个字段,默认有几天的有效期),作为同一个连接来请求另一个页面,如果是close的话,就是每次访问都是重新和服务端建立一个连接,不会保存session
这个问题的话,在一般情况下还是不会遇到,主要就是在高并发请求的时候,有可能同一个时刻请求多次来自同一个站点的数据,触发该网站的反爬机制的频率限制,就会出现什么scoket.timeout,urllib3.connection.HTTPConnection之类的错误。所以从那次之后我的爬虫程序如果用了高并发的话,我都会把这个connection设置为close
9.返回数据gzip
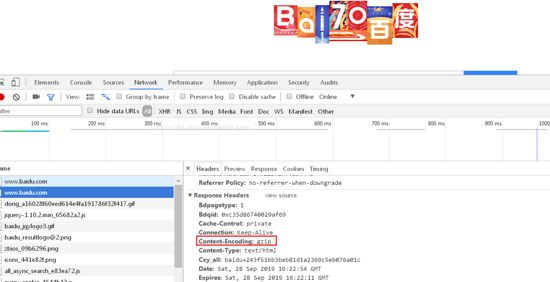
gzip的意思就是这个网站的数据是做呀gzip压缩的,在浏览器(客户端)访问之后,会自动处理这类格式的数据。但是使用Python的标准款urllib的话,是不会处理这类格式的, 解决方法就是用requests库,会自动处理gzip格式,反正这个库真的太强大了
10.reqeusts库的弊端
嘿嘿,刚说完requests很强大,马上说它的弊端,是的,就是这么骚气。它有什么弊端呢,如果经常使用requests库作为主要的网络请求的话,使用时间越长的老哥,就越会发现它有个弊端,就是它封装的异常类不够全,在报错各种各样的异常的时候,它有时候捕获不到,无法进行针对性的处理,这就是它的弊端,这个怎么解决呢,目前我的话,没有一个很好的解决方法,只能用Eception或者BaseEception类来捕获。
当然这个问题也不是一定会遇到,有时候只是某个其他的异常爆出,导致后续的代码跟着出错,然后跟着抛出异常,所以也不能盲目的用异常基类来捕获
11.登录验证
有的网站为了解决网络请求的拥塞,就做了账号登录验证,你必须登录账号之后才能正常访问页面,一般的网站登录之后返回的就是上面说的cookie字段,有的也会返回一个特殊的字段作为验证,我记得百度登录之后用的字段是BAIDUID。这个不需要多说什么,找到登录接口,提交账号密码参数访问登录接口就行了
12.请求头之token
这个token在语义上就是个令牌的意思,用的比较多的地方就是在手机端上用token验证,此手机端的验证对应的电脑端用的session验证,而电脑端用token的情况就是,特殊字段的变异,有的网站就放在请求头的authorized键里,值就是token,用uuid生成的,有的就是自定义的键,比如boss直聘的就是__zp_stoken__,必须要带上这个字段才能爬取(因为boss直聘的反爬机制升级了,以前直接可以爬,现在必须带上这个字段才行,说句题外话,目前我还没找到boss直聘这个字段是怎么生成的,用fiddler抓包发现请求了阿里云的服务端,但是返回的数据是空,反正没找到它是怎么生产的)

13.登录验证+token
有的网站在用户登录之后感觉还不够安全,就会再对token验证,如果登录验证和token都通过了说明是正常登录操作,才放行。当然也有的网站不需要登录也会分配一个token,比如上面的boss直聘,这个就不多说了,就是以上的结合
14.设备验证(手机,电脑)
一般情况下,电脑能访问的页面,手机一定能访问,只是如果该站没有作响应式的话,用手机访问的页面排版很乱,因为手机和电脑的尺寸不一样嘛。
但是手机能访问的,电脑不一定能访问,比如某app,或者微信小程序,它会做设备验证,发现不是手机页面的话就会拦截或者提示让你用手机下载该app查看。有朋友要问了,是用的什么来检测你是手机还是电脑的呢?就是前面最开始说的User-agent,说到这,怎么解决这个问题不用多说了吧,同样的伪造成手机的UA就行了,当然如果是针对app的爬取的话,一般就在电脑上下载模拟器(夜神模拟器啥啥的),然后fiddler抓包分析,然后再爬取
15.重定向
这个跟http的状态码有关了,不多说,返回的状态码是3**的就是重定向范畴里的,比如下面的百度:

这种网站怎么爬取呢,requests会自动处理重定向的问题,没错,requests就是这么抗打
16.触发跳转到新的标签页
什么意思呢,就是比如我在某一个网站点一下按钮,触发机制,用新的网页标签打开的,前端的朋友应该知道,就是a标签属性里加了个target='_blank',这种的话,我们用浏览器分析的就无法即使的通过调试工具查看了。其实习惯上我喜欢用浏览器自带的调试工具分析,方便快捷的操作,实在不行的话就上fiddler啥的抓包工具,没错,解决方法我已经说了,用抓包工具就可以破
17.调试工具触发js的debug监听器
这个我不知道你们遇到过没,我有一次抓某个网站,它就是为了防止我这类瞎jb搞的人分析它的代码,分析它的请求过程,所以当我一打开调试工具,就触发它的监听器,然后我就发现我电脑的CPU立马跑满了,一直在消耗我的电脑资源直到电脑卡死,所以我只能感觉关闭调试工具或者关闭浏览器,实在不行只能重启了,它就是监听的debuger,我不知道这个是一个函数还是一个类,以下是我保存的代码,看有缘人能不能看懂,看懂的话我就以身相....,不对,走错片场了,卧槽。。。
var check = (function () {
var callbacks = [], timeLimit = 50, open = false;
setInterval(loop, 1);
return {
addListener: function (fn) {
callbacks.push(fn);
},
cancleListenr: function (fn) {
callbacks = callbacks.filter(function (v) {
return v !== fn;
});
}
}
function loop() {
var startTime = new Date();
debugger;
if (new Date() - startTime > timeLimit) {
if (!open) {
callbacks.forEach(function (fn) {
fn.call(null);
});
}
open = true;
window.stop();
} else {
open = false;
}
}
})();
18.js加密cookie
这个大概的原理就是,访问该网站的时候会访问两次,第一次服务端返回响应头里给了一段加密的js代码,前端(浏览器)自动调用js然后反解出cookie,然后第二次访问的时候带上cookie去访问,才会返回一个正常的值,这个我在写IPproxy项目的时候遇到的66ip(http://www.66ip.cn/)网站就是这样的,而且很多同类的网站都是类似的操作。解决方法就是打开浏览器的调试工具,然后打断点测试,看看流程,基本都会有一系列的操作然后赋值给一个变量,找到这个变量名被如果的替换就行了,主要的破解难点就在js的部分,有的是做了js混淆加密的,有的是做了自定义处理的,这个就只有多尝试了
说到这,如果是那种监听debug工具的+js加密的话,那可就真的难操作了,哈哈哈,好像我还没有遇到网站这么干的
这个相关的破解教程的话,可以移步这里: https://www.cnblogs.com/zdfbk/p/8806282.html
19.urllib库之编码
有的时候如果要传递参数到服务端的话,那么就得做url编码,使用url编码解码就可以用urllIb.parse.quote和urlib.parse.unquote,使用quote方法作编码的话,默认使用的是utf-8的编码,但有时候一些网站用的gbk,所以这是一个坑,你得用quote(kw,encoding='gbk')才能转为gbk的编码,不熟悉这个的话就很难发现这个,因为我们一般就直接用quote就行了,根本不在意是用了什么编码

20.request.post之痛
嘿嘿,又是requests库的问题,准确说其实不是requests的问题,而是跟上面的quote一样,我们平常遇到的网站基本都是不会出现这个情况,当出现的时候我们就傻眼了,requests库的粉丝们,放下你们手上的菜刀,我是友军啊,我也一直在用requests,只是发现了这一两个情况而已
不多说了,requests做post请求时,提交的data字段会默认将data字段作url编码,且默认用的utf-8编码,对的,又是编码的锅,而有的网站用的并不是utf-8编码的,假如某网站用的是gbk编码,如果我们还是默认的操作的话,就会出错,解决办法就是,手动编码:

21.xpath解析tbody
解析网页结构的工具很多,比如一大杀气正则表达式,然后就是xpath,再然后就是bs4,最近我痴迷于xpath,我觉得写起来异常的顺畅,非常有感觉,但是在其中还是遇到了问题如下,无法解析带有tbody标签,这个是我最近发现的,不知道是不是版本问题,只要网页的DOM结构用tbody,比如table标签下有tbody/tr/td时,我要取td下的数据,按理就是写的response.xpath('//table/tbody/tr/td/text()'),但是这样写就是TMD的拿不到,得去掉tbody,写成这样就可以拿到:response.xpath('//table/tr/td/text()'),总之就是不能带tbody,如果有就直接跳到下一级就行,我估计是这个tbody被错误的解析成body标签了
22.xpath元素选取
一般情况下,我们获取某个数据的话,直接就根据class属性或者id属性,反正就一些非常特定的属性三两下就可以定位元素,但是有的元素就是什么属性都没带的,就只是一个标签名,而且这个标签用的还异常的多,此时此刻的话,你就可以你的目标元素就近的标签有没有很特殊的属性,直接就可以定位的,然后用following-sibling定位兄弟元素即可,比如:following-sibling::span[1]/text(),补充一个:回到上级:用 【..】表示回到上级,再补充一个,用contains(text(),'xxx'):根据一个元素的内容包含某个字段来定位
当然这几个都是很简单的,这个本来就是xpath的基础部分,但是我跟你说,这三个配套使用的话就没有锁定不了的元素,通通一杀一个准,真的,我感觉用多了xpath,比用beautifulsoup还顺手
23.简单验证码
简单验证码,比如一些肉眼很好看出的验证码的话,可以借用tesseract库来识别,做ocr提取,比如以下就是我那个IPproxy里的某一段代码:
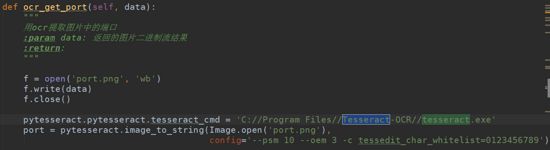
直接就可以把简单的验证码的数据提取出来,更多的操作就不说了,网上一大堆
24.滑动验证码
滑动验证码的话,以极验的滑动验证码为典型,之前网上有一大堆的极验验证码破解,不过都是2.0的破解,更新到3.0之后,破解的人就少了,不过,嘿嘿,我还是破解了,
我不多说,感兴趣的可以看看我的源码,包括腾讯系的我也破解了: GitHub (就在我的github里,我不说是哪个,嘿嘿,皮一把)
网易系的就不多说了,坊间传闻的,网易的滑动验证码本来就是抄袭极验的(不是我说的),所以破解方法差不多,感兴趣的可以根据我的代码自行修改
25.ip代理
终于说到这个问题了,稍微接触过爬虫的人都知道,你知道访问频率太频繁你电脑的公网IP就会被ban的,那么你就需要用上ip代理防止ip被ban无法继续爬数据的,也不多说,各位老哥如果需要请用鼠标滑到这篇文章的顶部,有写好的,现成的哦,不定期更新代码哦~
26.访问频率控制
有的网站比较大型,每天的访问量很大,那么这个网站对访问频率的限制就没那么严格,如果是小网站限制就会严一点,当然凡是无绝对,这个真的就看你的感知了,你如果感觉按你的代码运行下去可能爬不了几个数据就请求超时了,多半是触发访问频率的峰值了。如何解决,就只能看你自己怎么优化代码,保证代码每次请求的都不走空了,这个就没法具体的说了,你可以用协程来回的切换啥啥的
27.提升性能:
提升性能的话,要说的还挺多的,我就说几个比较典型的,如果你发现你的代码运行是串行的,你可以用gevent协程做切换,或者用线程池,或者用线程池+异步的方法,然后网络请求属于IO操作,所以不适合上多进程的方式
如果你还觉得速度不够快,可以弃掉requests库改用aiohttp库,这个也是网络请求的库,不过是异步请求的,requests是阻塞式的请求
还觉得不够快,可以用JIT,即使编译技术,把你觉得比较耗时间的代码块用上JIT
还觉得不够快,可以再用上解释器来直接解释这段代码,比如win平台下,直接用cpython对你的代码进行处理,其他平台的就用其他平台的解释器了,不多说了
还觉得不够快,技术再强点的话,可以写原生的C代码,把几个关键的操作抽离出来,用C来重构,然后运行的使用直接调用这段C代码(python有直接运行C代码的库,很多,网上自行查询)
还觉得不够快,升级你的硬件配置了
还觉得不够快?卧槽,没完了是吧,已经这样了,还想怎么个优化法啊老铁?
好的,以上就是我遇到的问题,在这过程中,有可能会遇到一些非常奇葩的问题,你简直无从下手的,然后慢慢找原因,找为什么,这样发散式的,又学到了新的东西。通过爬虫,我也对Python有了新的理解,新的体悟,从问题中成长,得到提升还是不错的
爬虫还有没有新的技术层面
确切的说,一定有的,据我目前的水平来理解的话,爬虫研究到一定层面的话,还跟网络安全有联系,比如跟逆向工程就有联系,逆向分析一个网站或者app什么的,我是真的觉得爬虫要研究透,估计得爬到上万的网站/app才敢说通透了。好的,以下分享一套爬虫题,这个是我关注的一个 爬虫大佬(人称亚一爬,微博:梁斌penny) 发的一套题,里面就有涉及网络安全的东西,感兴趣的可以自己做一下,先说明,我这里没有答案的哈,自行百度查看答案
1. 使用python中的requests库时(目前版本v2.22),以下哪种说法不正确:
A. 支持自定义请求中的headers顺序
B. 支持不同域名使用不同代理
C. 支持http2
D. 支持socks代理
2. 一般来说, python的requests.get函数会对传入的url进行urlencode操作. 但当如下代码中的keyword为哪个选项时, 无法得到预期的结果:
代码:requests.get('https://baike.baidu.com/item/{}'.format(keyword))
A. '梁斌'
B. 'C# 入门经典'
C. 'r&b'
D. '川上とも子'
3. 如果进行大规模并发抓取(比如1000并发+,单核单进程),下面哪个python的库的效率最好的:
A. urllib
B. requests
C. http.client
D. aiohttp
4. 使用Chrome devtools控制单个Chrome浏览器进行自动化操作时(原生chrome,且不使用插件的情况下),以下哪个说法正确的是:
A. 不能控制Chrome中的多个窗口
B. 不能抓取来自网络层的原始数据
C. 不能动态切换Chrome的代理
D. 不能禁止图片加载
5. 以下对于Chrome headless模式的描述中,哪个是错误的?
A. headless模式的User-Agent与普通(非headless)模式是不一样的
B. headless模式是有BOM和DOM的
C. headless模式是不支持Webassembly的
D. headless模式是支持鼠标点击事件的
6. 下列那种加密方式能最大限度抵御彩虹表的爆破:
A. HMAC-MD5
B. MD5
C. MD4
D. SHA1
7. 现在很多app采用了证书锁定ssl pinning来防止中间人攻击,关于ssl pinning下列说法错误的是:
A. ssl pinning是将服务端证书打包内置到移动客户端中,HTTPS连接建立时与服务端返回的证书对比一致性,以确定这个连接的合法性
B. 采用ssl pinning的app,仍然可以直接使用mitm proxy,fiddler等抓包工具可获取到明文包
C. 使用frida等工具绕过证书锁定后,抓包工具才能获取到明文HTTPS数据包
D. 采用了ssl pinning证书锁定的app,内置证书一般为自签名证书
8. 以下对xposed的描述中,正确的是:
A. xposed是对内核中init进行修改,使其能够注入到任何进程中
B. xposed不能hook native中的函数
C. xposed中的XposedBridge.jar会出现在任意apk进程的/proc/self/maps中
D. xposed并不支持Android Oreo的版本
9. 以下哪条语句能在frida中输出2019, Pet类定义如下:
public class Pet {
private static int kind = 2019;
private static int kind()
{
return 9102;
}
}
A. console.log( Pet._kind );
B. console.log( Pet.kind );
C. console.log( Pet._kind.value );
D. console.log( Pet.kind.value );
10. 关于app反调试下列说法错误的是:
A. app可以通过ptrace自身,来阻止调试器ptrace附加到app进程实现反调试
B. 在对程序脱壳过程中,经常需要将/proc/pid/mem或者/proc/pid/maps下内存数据dump出来, 可以使用inotify对文件进行监控,如果发现文件系统的的打开,读写,可能程序在被破解,就可以执行kill进程操作
C. 通过遍历程序内存段是否存在断点指令,来判断程序是否正在被调试,是则kill进程
D. 程序处于被调试状态时,某些关键指令的执行速度变化不大,所以通过对比关键代码执行的前后时间差,不能够判断出进程是否被调试
11. 以下关于frida的使用哪项不正确?
A. java层的hook必须在java.perform中执行
B. java层同名函数的hook,可以通过不同参数数量来区分,而不用写overload
C. frida以spawn方式启动app可以hook app在启动时就执行的函数
D. frida可以更改某个native函数的实现
12. 下面通过IDA反汇编的arm指令,其中描述不正确的是?
.text:0000ED72 MOVS R0, R0
.text:0000ED74 POP {R0}
.text:0000ED76 CMP R1, #0
.text:0000ED78 BNE loc_ED84
.text:0000ED7A PUSH {R0,R1,LR}
.text:0000ED7C BL sub_B2544
.text:0000ED80 MOVS R6, R1
.text:0000ED82 MOVS R0, R0
A. BL是带返回的跳转指令
B. 0xED7C位置进行的跳转后LR寄存器的值为0xED81
C. sub_B2544是程序员定义的函数名,此处将调用sub_B2544函数
D. 0xED78位置的指令含义是如果R1 != 0则进行跳转
13. 做爬虫难,还是做反爬难?
发表下您的看法,并简单阐述下原因(100字以内,开放式题目,没有对错,可自由发挥)。
1)下面哪种方式可以让爬虫合理、合法地抓取当日尽可能多的数据?
A. 通过漏洞进入他人计算机系统,把数据库dump出来。
B. 用大量低频关键词在目标站点上搜索,获得当日更全数据。
C. 找到热门的hub页,热门的话题,热门的账号,获取当日更全数据。
D. 用热门关键词在百度等搜索引擎上,用site:www.website.com + 关键词 查询,从而发现新数据
2)以下所列出的方法中,浏览器web数据抓取效率最高的方法是?
A. selenium + phantomjs
B. 使用chrome或者chrome内核抓取
C. 模拟web协议直接用wget或curl抓取
3)下面哪项是手机端抓取app数据相比web端的优势(多选):
A. 手机端协议简单容易分析
B. 手机端可以使用模拟点击
C. 手机端就算出新版了旧版还是可以继续使用,不会立即停掉
D. 通常来说,手机端抓取同样信息量的数据,下载量更低
4)下面哪些代理支持rawsocket连接(多选)?
A. HTTP代理
B. HTTPS代理
C. SOCKS4代理
D. SOCKS5代理
5)下面代码请求实际访问地址url是什么?
url = "https://test.cn/test"
params = {
"xxxx":"1234"
}
headers = {
"Host": "www.test.cn",
"Accept-Encoding": "gzip,deflate",
"Connection": "Keep-Alive"
}
requests.get(url, params, headers =headers, allow_redirects = False, verify = False)
假设http://test.cn/test?xxxx=1234返回的状态码302且response header里有Location:http://www.test.cn/dpool/ttt/domain.php?d=test&xxxx=1234
A. https://test.cn/test
B. https://test.cn/test?xxxx=1234
C. https://www.test.cn/test?xxxx=1234
D.http://www.test.cn/dpool/ttt/domain.php?d=test&xxxx=1234
6)假如你要爬大量youtube视频的二进制内容,存储在本地,最佳的办法是?
A. Mysql数据库存储
B. Redis存储
C. Mongodb存储
D. 文件系统
7)如果想爬自己手机应用上的HTTPS的数据,获得明文,下面哪个说法是正确的?
A. 自己搭建一个HTTPS代理,让手机设置为这个代理,即可获得明文
B. 任何HTTPS明文都是可以获取的
C. 在PC上建立一个无线热点,让手机连这个热点,并使用Wireshare软件分析出HTTPS的明文数据
D. 通过让手机系统信任根证书,使用Man-in-the-middle中间人攻击技术,就可以获取任何HTTPS明文
8)以下哪个功能chromedriver协议不支持?
A. 注入js文件
B. 模拟鼠标滑动
C. 网络请求的响应式处理
D. 同个实例可以同时操作多个页面
9)爬取数据过程中,哪个情况是最不可容忍的?
A. 爬取的数据不完整,有部分数据遗失
B. 爬取程序非法关闭,内存泄露
C. 爬取的数据部分出错,手动修改
D. 不同版本的数据合并在一起
10)爬虫开发不会涉及到的技术或者知识有?
A. tcp,udp传输协议
B. 反汇编技术
C. 数据库存储
D. 音视频流解析
E. 网络路由协议
F. 以上都会涉及
1)如何获得大量IP资源(业界主流方法)
2)如何获得账号资源,如何进行大量账号登陆
3)抓取系统如何构建,如何可扩展
4)如何探测封杀阈值
5)如何将爬虫模拟成正常用户
6)每个模块使用到的最佳工具
7)其他系统杂项trick,如何流量均衡等等
1)爬虫为什么要做DNS缓存?
A:可以节约抓取带宽
B:节约域名解析时间
C: 减少下载数据大小
D:防止多次DNS请求被抓取目标网站封杀
2)Etag干什么用的?
A:防止重复图片download
B:节约http header的大小
C:提示web服务可以接受压缩数据
D:提示网页内容的标签信息
3)Transfer-Encoding为chunked时,会出现什么情况
A:通常没有Content-Type域
B:通常没有Content-Length域
C:网页数据不可能同时即是压缩数据又是chunked数据
D:数据结尾标记是:一个数值(表示总长度)\r\n\r\n
4)tcp最小数据载荷是多少字节(抛出协议头部)? the minimum "data" size of a TCP segment should be?
A:6字节
B:20字节
C:24字节
D:不确定
5)当最后一个包比最小数据载荷还小时,TCP/IP协议如何处理是否结束?
A:在最后一个包的末尾填充特殊字符以表示数据结束
B:最开始协商的数据大小和已经接受的数据一致即可判断结束
C:再发一个最小数据载荷大小的空包已表示数据结束
D:和具体协议实现有关,并不完全确定
6)下面那一项是爬虫工程师不需要的
A:人工智能
B:系统架构
C:网络相关
D:HTTP协议
E:浏览器
F:数据存储
G:待遇持续保持在比较低的水平