Coursera | Andrew Ng (01-week-4-4.6)—搭建深层神经网络块
该系列仅在原课程基础上部分知识点添加个人学习笔记,或相关推导补充等。如有错误,还请批评指教。在学习了 Andrew Ng 课程的基础上,为了更方便的查阅复习,将其整理成文字。因本人一直在学习英语,所以该系列以英文为主,同时也建议读者以英文为主,中文辅助,以便后期进阶时,为学习相关领域的学术论文做铺垫。- ZJ
Coursera 课程 |deeplearning.ai |网易云课堂
转载请注明作者和出处:ZJ 微信公众号-「SelfImprovementLab」
知乎:https://zhuanlan.zhihu.com/c_147249273
CSDN:http://blog.csdn.net/JUNJUN_ZHAO/article/details/79035623
4.6 Building blocks of deep neural networks 搭建深层神经网络块
(字幕来源:网易云课堂)

In the earlier videos from this week,as well as from the videos from the past several weeks.you’ve already seen the basic building blocks of forward propagation and back propagation.the key components you need to implement a deep neural network.let’s see how you can put these components together to build a deep net.Here’s a network with a few layers let’s pick one layer and look at the computations focusing on just that layer for now,so for layer L you have some parameters W[l] and b[l] ,and for the forward prop you will input the activations, a[l−1] from the previous layer and output a[l] ,so the way we did this previously was you compute z[l] ,equals w[l] x a[l−1] plus b[l]
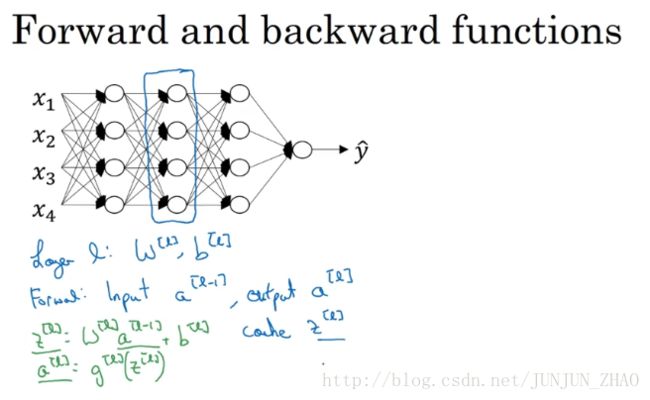
这周的前几个视频,和之前几周的视频里,你已经看到过正向反向传播的基础组成部分了,它们也是深度神经网络的重要组成部分,现在我们来用它们建一个深度神经网络,这是一个层数较少的神经网络 我们选择其中一层,从这一层的计算着手,在第 l 层 你有参数 W[l] 和 b[l] ,正向传播里有输入的激活函数,输入是前一层 a[l−1] 输出是 a[l] ,我们之前讲过 z[l] ,等于 w[l] 乘以 a[l] 减1加上 b[l] , a[l] 又等于 g[l](z[l]) ,那么这就是你如何从输入 a[l−1] 走到输出的。
重点:
Layer l : w[l],b[l]
Forward (正向): Input a[l−1] , Output: a[l]
z[l]=w[l]⋅a[l−1]+b[l]a[l]=g[l](z[l])
um,and then a[l] equals g[l](z[l]) right,so that’s how you go from the input al minus one to the output al,and it turns out that for later use,will be useful to also cache the value z[l] .so let me include this on cache as well because storing the value z[l] ,will be useful forward backward for the back propagation step later,and then for the backward step or three for the back propagation step,again focusing on computation for this layer l,you’re going to implement a function that inputs da[l] ,and outputs da[l−1] ,and just refreshing the details the input is actually da[l] ,as well as the cache so you have available to you,the value of z[l] that you compute it,and in addition to outputting g[l−1] ,you will output you know the gradients you want,in order to implement gradient descent for learning ok,so this is the basic structure of how you implement this forward step,I’m going to call it a forward function,as well as backward step we shall call it backward function,

之后你就可以,把 z[l] 的值缓存起来,我在这里也会把这包括在缓存中,因为缓存的 z[l] 对以后的正向反向传播的步骤非常有用,然后是反向步骤 或者说反向传播步骤,同样也是第 l 层的计算,你会需要实现一个函数 输入为 da[l] ,输出 da[l−1] 的函数,一个小细节需要注意 输入在这里其实是 da[l] ,以及所缓存的 z[l] 值,之前计算好的 z[l] 值,除了输出 g[l−1] 的值以外,也需要输出你需要的梯度,这是为了实现梯度下降学习,这就是基本的正向步骤的结构,我把它成为称为正向函数,
类似的在反向步骤中会称为反向函数。
重点:
正向传播时,将 z[l] 缓存起来。
Backward(反向): Input : da[l] , cache ( z[l] ) ,Output : da[l−1] , dw[l],db[l]
so just to summarize in layer l you’re going to have you know the forward step or the forward prop forward function,input a[l−1] and output a[l] and in order to make this computation,you need to use W[l] and b[l] um,and also output a cache which contains z[l] ,and then on the backward function using the back prop step will be another function,then now inputs da[l] and outputs da[l−1] ,so it tells you given the derivatives respect to these activations,that’s da[l] what are the derivatives or how much do i wish,you know a[l−1] changes computed derivatives respect to the activations from the previous layer,within this box right you need to use w[l] and b[l] ,and it turns out along the way you end up computing dz[l] um,and then this box this backward function can also output dW[l] and db[l] ,well now sometimes using red arrows to denote the backward iterations,so if you prefer we could draw these arrows in red.

总结起来就是,在 l 层你会有正向函数,输入 a[l−1] 并且输出 a[l] 为了计算结果,你需要用 W[l] 和 b[l] ,以及输出到缓存的 z[l] ,然后用作反向传播的反向函数,是另一个函数,输入 da[l] 输出 da[l−1] ,你就会得到对激活函数的导数,也就是 da[l] 这导数是多少呢? 我希望是什么? a[l−1] 是会变的,前一层算出的激活函数导数,在这个方块里你需要 w[l] 和 b[l] 。最后你要算的是 dz[l] ,然后这个方块中 这个反向函数,可以计算输出 dW[l] 和 db[l] ,我会用红色箭头标注标注反向步骤,如果你们喜欢 我可以把这些箭头涂成红色。
so if you can implement these two functions,then the basic computation of the neural network will be as follows,you’re going to take the input features a[0] ,Feed that in and that will compute the activations of the first layer.let’s call that a[1] and to do that you needed w[1] and b[1] ,and then we’ll also you know cache the value z[l] ,now having done that you feed that,this is the second layer and then using w[2] and b[2] ,you’re going to compute the activations our next layer a[2] 1 and so on,until eventually you end up,outputting a capital l which is equal to y hat,and along the way we cashed all of these on values z,so that’s the forward propagation step.

然后如果实现了这两个函数,然后神经网络的计算过程会是这样的,把输入特征 a[0] ,放入第一层并计算第一层的激活函数,用 a[1] 表示 你需要 w[1] 和 b[1] 来计算,之后也缓存 z[l] 值,之后喂到第二层,第二层里 需要用到 w[2] 和 b[2] ,你会需要计算第二层的激活函数 a[2] 后面几层以此类推,直到最后你算出了, a[L] 第 L 层的最终输出值 y^ ,在这些过程里我们缓存了所有的 z 值,这就是正向传播的步骤。
now for the back propagation step what we’re going to do will be a backward sequence of iterations,in which you’re going backwards and computing gradients like so,so as you’re going to feed in here da[l] ,and then this box will give us da[l−1] and so on,until we get da[2] da[1] ,you could actually get one more output to compute da[0] ,but this is derivative respect your input features which is not useful,at least for training the weights of these are supervised neural networks,so you could just stop it there,along the way back prop also ends up outputting dw[l] db[l] right,this used upon so W[L] and b[L] ,this would output dw[3] db[3] and so on,so you end up computing all the derivatives you need.

对反向传播的步骤而言,我们需要算一系列的反向迭代,就是这样反向计算梯度,你需要把 da[l] 的值放在这里,然后这个方块会给我们 da[l−1] 的值 以此类推,直到我们得到 da[2] 和 da[1] ,你还可以计算多一个输出值 就是 da[0] ,但这其实是你的输入特征的导数 并不重要,起码对于训练监督学习的权重不算重要,你可以止步于此,反向传播步骤中也会输出 dw[l] 和 db[l] ,这个会输出 W[L] 和 b[L] ,这会输出 dw[3] 和 db[3] 等等,目前为止你算好了所有需要的导数。
just a maybe to fill in the structure a little bit more right,these boxes will use those parameters of slow w[l] b[l] ,and it turns out that we’ll see later,that inside these boxes we’ll end up computing dz as well,so one iteration of training for a neural network involves,starting with a[0] ,which is x and going through for profit as follows computing y hat,and then using that to compute this,and then back prop right doing that,and now you have all these derivative terms,and so you know w will get updated as,some w minus the learning rate times dw right for each of the layers,and similarly for b right.now we’ve compute the back prop and have all these derivatives.

稍微填一下这个流程图,这些方块需要用到参数 w[l] 和 b[l] ,我们之后会看到在这些方块中,在这些方块里 我们最后会计算 dz,神经网络的一步训练 包含了,从 a[0] 开始,也就是 x 然后经过一系列正向传播计算得到 y^ ,之后再用输出值计算这个,再实现反向传播,现在你就有所有的导数项了,w 也会在每一层被更新为,每一层里 W 减去学习率乘以 dW,b 也一样,反向传播就都计算完毕,我们有所有的导数值。
重点:
w[l]:=w[l]−α⋅dw[l]b[l]:=b[l]−α⋅db[l]
so that’s one iteration of gradient descent for your neural network,now before moving on just one more implementational detail,conceptually will be useful to think of the cache here as storing,the value of Z for the backward functions,but when you implement this you see this in the programming exercise,when you implement it you find that the cache may be a convenient way to get the value of the parameters at W[1] b[1] into the backward function as well.so the program exercise you actually store the cache is z,as well as W and b all right.so to store z[2] W[2] be to go from an implementational standpoint.I just find this a convenient way to just you know get the parameters copied to where you need to need to use them later,when you’re computing back propagation.so that’s just an implementational detail that you see when you do the programming exercise.so you’ve now seen one of the basic building blocks for implementing a deep neural network.In each layer there’s a forward propagation step and there’s a corresponding backward propagation step,and as cache deposit information from one to the other.in the next video we’ll talk about,how you can actually implement these building blocks.let’s go into the next video.
那么这是神经网络一个梯度下降循环,继续下去之前再补充一个细节,概念上会非常有帮助,那就是把反向函数,计算出来的 z 值缓存下来,当你做编程练习的时候去实现它时,你会发现缓存可能很方便,可以在分享传播函数迅速得到 W[1] 和 b[1] 的值,非常方便的一个方法,在编程练习中你缓存了z,还有 W 和 b 对吧,缓存 z[2] W[2] 从实现角度上看,我认为是一个很方便的方法,可以将参数复制到,你在计算反向传播时所需要的地方。好 这就是实现过程的细节,做编程练习时会用到,现在你们见过,实现深度神经网络的基本元件,在每一层中 有一个正向传播步骤,以及对应的反向传播步骤,以及把信息从一步传递到另一步的缓存,下一个视频我们会,这些元件具体实现过程,我们来看下一个视频吧。

PS: 欢迎扫码关注公众号:「SelfImprovementLab」!专注「深度学习」,「机器学习」,「人工智能」。以及 「早起」,「阅读」,「运动」,「英语 」「其他」不定期建群 打卡互助活动。
