LruCache 源码剖析
LruCache 源码剖析
前言
有一定经验的开发者都知道这个类, 大多数情况 LruCache 类都被用在图片缓存这一块, 而其中使用了一个听起来高大上的算法 —— “近期最少使用算法”。 在经过一轮源码的解析之后, 我们会发现内部是使用了简单的技巧来实现的。
源码剖析
首先我们来看一下 LruCache 的构造方法
public LruCache(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
this.maxSize = maxSize;
this.map = new LinkedHashMap(0, 0.75f, true);
} 可以看到内部使用 LinkedHashMap 实现。
在一般情况下, 当需要缓存某个对象时, 调用的是 put 方法
LruCache#put
public final V put(K key, V value) {
// 键和值都不能为空
if (key == null || value == null) {
throw new NullPointerException("key == null || value == null");
}
V previous;
synchronized (this) {
putCount++;
// ②
size += safeSizeOf(key, value);
// ③
previous = map.put(key, value);
if (previous != null) {
size -= safeSizeOf(key, previous);
}
}
if (previous != null) {
entryRemoved(false, key, previous, value);
}
// ④
trimToSize(maxSize);
return previous;
}我们来看一下 ②, 调用了 safeSizeOf 方法, 该方法用来计算 value 占用大小的。
private int safeSizeOf(K key, V value) {
int result = sizeOf(key, value);
if (result < 0) {
throw new IllegalStateException("Negative size: " + key + "=" + value);
}
return result;
}
/**
* Returns the size of the entry for {@code key} and {@code value} in
* user-defined units. The default implementation returns 1 so that size
* is the number of entries and max size is the maximum number of entries.
*
* An entry's size must not change while it is in the cache.
*/
protected int sizeOf(K key, V value) {
return 1;
}可以看到 sizeof 方法默认返回1, 所以我们在使用 LruCache 类时常常需要重写该方法, 指定 key 和 value 的占用空间大小。
再回到 put 方法中, 研究一下③方法, 调用了 map 的 put 方法, map 即为初始化时候的 LinkedHashMap, 而 LinkedHashMap 继承了 HashMap 的 put 方法。
HashMap#put
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = sun.misc.Hashing.singleWordWangJenkinsHash(key);
// hash 值与 length -1 作与操作, 相当于取余, 计算出位标
int i = indexFor(hash, table.length);
// 找到 i 位置hash和key相同的位置, 如果不为空, 且 hash 值与 key 值相同, 替换旧数值
for (HashMapEntry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
} 要注意 LinkedHashMap 重写了 HashMap 的 addEntry 方法, 好像没啥用, 接着看 HashMap 的方法。
LinkedHashMap#addEntry
void addEntry(int hash, K key, V value, int bucketIndex) {
// Previous Android releases called removeEldestEntry() before actually
// inserting a value but after increasing the size.
// The RI is documented to call it afterwards.
// **** THIS CHANGE WILL BE REVERTED IN A FUTURE ANDROID RELEASE ****
// Remove eldest entry if instructed
LinkedHashMapEntry eldest = header.after;
if (eldest != header) {
boolean removeEldest;
size++;
try {
removeEldest = removeEldestEntry(eldest);
} finally {
size--;
}
if (removeEldest) {
removeEntryForKey(eldest.key);
}
}
super.addEntry(hash, key, value, bucketIndex);
} HashMap#addEntry
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length); //扩容到原来的2倍
hash = (null != key) ? sun.misc.Hashing.singleWordWangJenkinsHash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}可以看到, 如果添加对象过后的大小大于指定值, 将进行扩容, 在这里先不管它。 继续看方法末尾调用的 createEntry 方法。
HashMap#createEntry
/**
* This override differs from addEntry in that it doesn't resize the
* table or remove the eldest entry.
*/
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMapEntry old = table[bucketIndex];
LinkedHashMapEntry e = new LinkedHashMapEntry<>(hash, key, value, old);
table[bucketIndex] = e;
e.addBefore(header);
size++;
}
private static class LinkedHashMapEntry<K,V> extends HashMapEntry<K,V> {
// These fields comprise the doubly linked list used for iteration.
LinkedHashMapEntry before, after;
LinkedHashMapEntry(int hash, K key, V value, HashMapEntry next) {
super(hash, key, value, next);
}
...
} 我们可以看到, 新增结点除了初始化 LinkedHashMapEntry (实质初始化 HashMapEntry 的内部属性, 初始化时使用链地址法解决冲突) 内的属性外, 还调用了 LinkedHashMapEntry 对象的 addBefore 方法。
LinkedHashMapEntry#addBefore
private void addBefore(LinkedHashMapEntry existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
} 这个 header 又是个啥?
我们看看 header 对象的初始化过程, 在构造 LinkedHashMap 初始化的过程, (同时父类 HashMap 也初始化, 并调用 init 方法), 调用了 init 方法。
/**
* The head of the doubly linked list. 双向链表的头, 初始化时 header 的前驱后继都指向自己
*/
private transient LinkedHashMapEntry header;
@Override
void init() {
header = new LinkedHashMapEntry<>(-1, null, null, null);
header.before = header.after = header;
} header 是默认没有键和值的, 默认前驱和后继都指向自己。 如图:
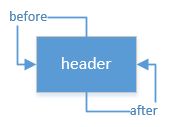
所以调用完上面的 addBefore 方法后, 结构是这样的:
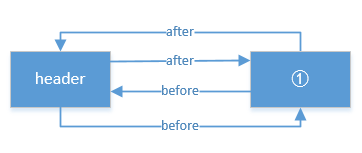
如果添加第二个结点的话, 还是看 addBefore 方法, 结构是这样的:

最后让我们回到 LruCache 的 put 方法, 看最后一步 ④, trimToSize 是干嘛的呢?
LruCache#trimToSize
/**
* Remove the eldest entries until the total of remaining entries is at or
* below the requested size.
*
* @param maxSize the maximum size of the cache before returning. May be -1
* to evict even 0-sized elements.
*/
public void trimToSize(int maxSize) {
while (true) {
K key;
V value;
synchronized (this) {
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(getClass().getName()
+ ".sizeOf() is reporting inconsistent results!");
}
if (size <= maxSize || map.isEmpty()) {
break;
}
Map.Entry toEvict = map.entrySet().iterator().next();
key = toEvict.getKey();
value = toEvict.getValue();
map.remove(key);
size -= safeSizeOf(key, value);
evictionCount++;
}
entryRemoved(true, key, value, null);
}
} 可以看到官方注释, 如果请求的空间不够时, 将移除最近未使用的 entry 键值对, 近期最少使用是怎么判断的呢。 先获取存放所有 Entry 的 set 容器, 直接移除 next 方法获取的 Entry, 移除 entry 直到 size 小于 maxSize, 这个技巧真是 666;
现在来研究一下 entrySet 方法和 iterator 方法和 next 方法。 entrySet 方法 LinkedHashMap 是从 HashMap 继承过来的
// ---------------- HashMap--------------
public Set> entrySet() {
return entrySet0();
}
private Set> entrySet0() {
Set> es = entrySet;
return es != null ? es : (entrySet = new EntrySet());
}
private final class EntrySet extends AbstractSet<Map.Entry<K,V>> {
public Iterator> iterator() {
return newEntryIterator(); // !!!!!!!!! 看这
}
...
}
这里要注意一下这个 newEntryIterator 是调用谁的方法的, 我们可以看到 HashMap 和 LinkedHashMap 都有这个方法
// HashMap
Iterator> newEntryIterator() {
return new EntryIterator();
}
private final class EntryIterator extends HashIterator<Map.Entry<K,V>> { // ①
public Map.Entry next() {
return nextEntry();
}
}
// LinkedHashMap 肯定重写了父类 newEntryIterator 方法
Iterator> newEntryIterator() {
return new EntryIterator();
}
private class EntryIterator extends LinkedHashIterator<Map.Entry<K,V>> { // ②
public Map.Entry next() { return nextEntry(); }
}
① 和 ② 明显就不一样, 父类不同。 刚开始我研究的时候, 就看错研究对象了, 搞得最后一脸懵逼。 我们这里研究的对象是 LinkedHashMap, 所以调用 next 方法后, 将会调用 LinkedHashIterator 的 nextEntry 方法。
LinkedHashMap 内部类 LinkedHashIterator
private abstract class LinkedHashIterator<T> implements Iterator<T> {
LinkedHashMapEntry nextEntry = header.after;
LinkedHashMapEntry lastReturned = null;
...
Entry nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (nextEntry == header)
throw new NoSuchElementException();
LinkedHashMapEntry e = lastReturned = nextEntry;
nextEntry = e.after;
return e;
}
} 第一次进行 Iterator 遍历时, 最先得到的即是 header.after 指向的对象, 结合上面的 trimToSize 方法, 可以发现, 第一次 next 得到的对象, map 对其直接作 remove 处理。 厉害了, 那就说明 header.after 指向的对象就是最近最少使用对象。
那, 如果我通过 get 方法, 取出对象使用, LinkedHashMap 的内部结构又会有什么变化呢。
所以我们看看, LinkedHashMap 的 get 方法。
LinkedHashMap#get
public V get(Object key) {
// ①
LinkedHashMapEntry e = (LinkedHashMapEntry)getEntry(key);
if (e == null)
return null;
// ②
e.recordAccess(this);
return e.value;
} 咱们先看看 ① 做了什么。
HashMap#getEntry
final Entry getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : sun.misc.Hashing.singleWordWangJenkinsHash(key);
for (HashMapEntry e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
} 这个方法没什么特殊的, 找到 hash 对应位标, 再找到 hash 值与 key 值相同的对象, 最后依次对象返回。
我们回到 get 方法, 看 ② 发生了什么, 这个方法更厉害了!!
LinkedHashMapEntry#recordAccess
void recordAccess(HashMap m) {
LinkedHashMap lm = (LinkedHashMap)m;
if (lm.accessOrder) { // accessOrder 在 LruCache 初始化 LinkedHashMap 过程中置为 true 了
lm.modCount++;
remove(); //
addBefore(lm.header);
}
} 先看 remove 方法。
private void remove() {
before.after = after;
after.before = before;
}调用完 remove 后, 结构如图:(假设我们要 get 的是图中 ① 对象)
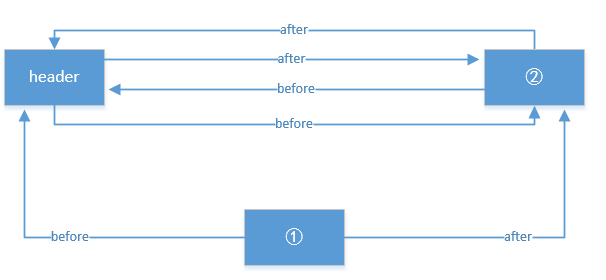
现在看看 addBefore 方法
private void addBefore(LinkedHashMapEntry existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
} 调用完 addBefore 后, 最终的结构如图:

所以当通过 get 方法 “使用” 了一个对象, 该对象将会放在链表最末端, 所以近期最少使用的对象也就是 header.after 指向的对象了。
总结
