性能提升约 7 倍!Apache Flink 与 Apache Hive 的集成
导读:随着 Flink 在流式计算的应用场景逐渐成熟和流行,如果 Flink 能同时把批量计算的应用场景处理好,就能减少用户在使用 Flink 时开发和维护的成本,并且能够丰富 Flink 的生态。SQL 是批计算中比较常用的工具,所以 Flink 针对于批计算也以 SQL 为主要接口。本次分享主要介绍 Flink 对批处理的设计与 Hive 的集成。主要分为下面三点展开:
设计架构
项目进展
性能测试
重要:点击文末「阅读原文」可查看作者现场分享的视频。
设计架构
首先和大家分享一下 Flink 批处理的设计架构。
1. 背景

Flink 提升批处理的主要原因是为了减少客户的维护成本和更新成本和更好的完善 Flink 生态环境。SQL 是批计算场景中一个非常重要的工具,所以希望以 SQL 作为在批计算场景的主要接口,为此我们着重优化了 Flink SQL 的功能。当前 Flink SQL 主要有下面几点需要优化:
需要完整的元数据管理体制。
缺少对 DDL(数据定义语言 DDL 用来创建数据库中的各种对象,如表、视图、索引、同义词、聚簇等)的支持。
与外部系统进行对接不是很方便,尤其是 Hive, 因为 Hive 是大数据领域最早的 SQL 引擎,所以 Hive 的用户基础非常广泛,新的一些 SQL 工具,如 Spark SQL、Impala 都提供了与 Hive 对接的功能,这样用户才能更好地将其应用从 Hive 迁移过来,所以与 Hive 对接对 Flink SQL 而言也十分重要。
2. 目标

所以我们要完成以下目标:
定义统一的 Catalog 接口,这个是 Flink SQL 更方便与外部对接的前提条件。如果大家用过 Flink 的 TableSource 和 TableSink 来对接外部的系统的表,会发现不管是通过写程序还是配置 yaml 文件会跟传统的 SQL 使用方式会有些不同。所以我们肯定不希望 Hive 的用户迁移 Flink SQL 需要通过定义 TableSouces 和 TableSink 的方式来与 Hive 进行交互。因此我们提供了一套新的 Catalog 接口以一种更接近传统 SQL 的方式与 Hive 进行交互。
提供基于内存和可持久化的实现。基于内存就是 Flink 原有的方式,用户所有的元数据的生命周期是跟他的 Session(会话)绑定的,Session(会话)结束之后所有的元数据都没有了。因为要跟 Hive 交互所以肯定还要提供一个持久化的 Catalog。
支持 Hive 的互操作。有了 Catalog 之后用户就可以通过 Catalog 访问 Hive 的元数据,提供 Data Connector 让用户能通过 Flink 读写 Hive 的实际数据,实现 Flink 与 Hive 的交互。
支持 Flink 作为 Hive 的计算引擎(长期目标),像 Hive On Spark,Hive On Tez。
3. 全新设计的 Catalog API(FlIP-30)
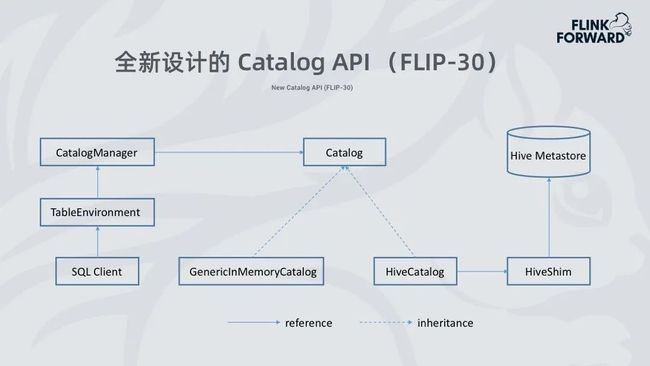
用户通过 SQL Client 或者 Table API 提交请求,Flink 会创建 TableEnvironment, TableEnvironment 会创建 CatalogManager 加载并配置 Catalog 实例,并且 Catalog 支持多种元数据类型 table、database、function、view、partition 等,在 1.9.0 的版本当中 Catalog 会有两个实现:
一个是基于内存的 GenericinMemoryCatalog。
另一是 HiveCatalog,HiveCatalog 通过 HiveShim 与 Hive Metasotre 交互来操作 Hive 元数据,HiveShim 的作用是处理 Hive 在大版本中 Hive Metastore 不兼容的问题。
从这种实现的方式可以看出,用户可以创建多个 Catalog,也可以访问多个 Hive Metastore,来达到跨 Catalog 查询的操作。
4. 读写 Hive 数据

有了元数据之后我们就可以实现 Flink SQL 的 Data Connector 来真正的读写 Hive 实际数据。Flink SQL 写入的数据必须要兼容 Hive 的数据格式,也就是 Hive 可以正常读取 Flink 写入的数据,反过来也是一样的。为了实现这一点我们大量复用 Hive 原有的 Input/Output Format、SerDe 等 API,一是为了减少代码冗余,二是尽可能的保持兼容性。
在 Data Connect 中读取 Hive 表数据具体实现类为:HiveTableSource、HiveTableInputFormat。写 Hive 表的具体实现类为:HiveTableSink、HiveTableOutputFormat。
项目进展
其次和大家分享 Flink 1.9.0 的现状和 1.10.0 中的新特性还有未来工作。
1. Flink 1.9.0 的现状

Flink SQL 作为 1.9.0 版本中作为试用功能发布的,它的功能还不是很完善:
支持的数据类型还不全。(1.9.0 中带参数的数据类型基本上都不支持:如 DECIMAL,CHAR 等)
对分区表的支持不完善,只能读取分区表,不能写分区表。
不支持表的 INSERT OVERWRITE。
2. Flink 1.10.0 中的新特性

Flink SQL 在 1.10.0 版本里我们做了比较多的进一步开发,与 Hive 集成的功能更加完整。
支持读写静态分区和动态分区表。
在表级别和分区级别都支持 INSERT OVERWRITE。
支持了更多地数据类型。(除 UNION 类型都支持)
支持更多地 DDL。(CREATE TABLE/DATABASE)
支持在 Flink 中调用 Hive 的内置函数。(Hive 大约 200 多个内置函数)
支持了更多的 Hive 版本。(Hive 的 1.0.0~3.1.1)
做了很多性能优化如,Project/Predicate Pushdown,向量的读取 ORC 数据等。
3. Module 接口

为了能让用户调用 Flink SQL 中调用 Hive 的内置函数,我们在 Flink 1.10 当中引入了一个 Module 接口。这个 Module 是为了让用户能够方便的把外部系统的内置函数接入到系统当中。
使用方式和 Catalog 类似,用户可以通过 Table API 或 Yaml 文件来配置 Module。
Module 可以同时加载多个,Flink 解析函数的时候通过 Module 的加载顺序在多个 Module 中查找函数的解析。也就是如果两个 Module 包含名字相同的 Function,先加载的 Module 会提供 Function 的定义。
目前 Module 有两个实现,CoreModule 提供了 Flink 原生的内置函数,HiveModule 提供了 Hive 的内置函数。
4. 未来工作

未来的工作主要是先做功能的补全,其中包括:
View 的支持(有可能在 1.11 中完成)。
持续改进 SQL CLI 的易用性,现在支持翻页显示查询结果,后续支持滚动显示。并支持 Hive 的 -e -f 这种非交互式的使用方式。
支持所有的 Hive 常用 DDL,例如 CREATE TABLE AS。
兼容 Hive 的语法,让原来在 Hive 上的工程在 Flink 的顺滑的迁移过来。
支持 SQL CLI 的远程模式,类似 HiveServer2 的远程连接模式。
支持流式的写入 Hive 数据。
性能测试
下面是 Flink 在批处理作业下与 HiveMR 对比测试的测试环境和结果。
1. 测试环境

首先我们的测试环境使用了 21 个节点的物理机群,一个 Master 节点和 20 个 Slave 节点。节点的硬件配置是 32 核,64 个线程,256 内存,网络做了端口聚合,每个机器是 12 块的 HDD 硬盘。
2. 测试工具

测试工具使用了 Hortonworks 的 hive-testbench,github 中一个开源的工具。我们使用这个工具生成了 10TB 的 TPC-DS 测试数据集,然后分别通过 Flink SQL 和 Hive 对该数据集进行 TPC-DS 的测试。
一方面我们对比了 Flink 和 Hive 的性能,另一方面我们验证了 Flink SQL 能够很好的访问 Hive 的数据。测试用到了 Hive 版本是 3.1.1,Flink 用到的是 Master 分支代码。
3. 测试结果

测试结果 Flink SQL 对比 Hive On MapReduce 取得了大约 7 倍的性能提升。这得益于 Flink SQL 所做的一系列优化,比如在调度方面的优化,以及执行计划的优化等。总体来说如果用的是 Hive On MapReduce,迁移到 Flink SQL 会有很大性能的提升。
附最新性能对比详情及思路解析:Flink 1.10 和 Hive 3.0 性能对比
作者介绍:
李锐(天离),阿里巴巴技术专家,Apache Hive PMC 成员,加入阿里巴巴之前曾就职于 Intel、IBM 等公司,主要参与 Hive、HDFS、Spark 等开源项目。
王刚(乔燃),阿里巴巴高级开发工程师, Flink Contributor。浙大计算机系毕业后曾任职于蘑菇街数据平台,从事数据交换系统开发。目前在阿里主要专注在 Flink 与 Hive 生态建设。
▼ 更多技术文章 ▼
Demo:基于 Flink SQL 构建流式应用
Flink 1.10 Native Kubernetes 原理与实践
Flink Batch SQL 1.10 实践
Flink on Zeppelin (3) - Streaming 篇
Flink on Zeppelin (2) - Batch 篇
Flink on Zeppelin (1) - 入门篇
从开发到生产上线,如何确定集群大小?
在 Flink 算子中使用多线程如何保证不丢数据?
Flink SQL 如何实现数据流的 Join?
关注 Flink 中文社区,获取更多技术干货

你也「在看」吗?????