前言
本专题大纲:

本文为本专题倒数第二篇文章。
在上篇文章中我们一起学习了Spring中的事务抽象机制以及动手模拟了一下Spring中的事务管理机制,那么本文我们就通过源码来分析一下Spring中的事务管理到底是如何实现的,本文将选用Spring5.2.x版本。
从@EnableTransactionManagement开始
Spring事务管理的入口就是@EnableTransactionManagement注解,所以我们直接从这个注解入手,其源码如下:
public @interface EnableTransactionManagement {
// 是否使用cglib代理,默认是jdk代理
boolean proxyTargetClass() default false;
// 使用哪种代理模式,Spring AOP还是AspectJ
AdviceMode mode() default AdviceMode.PROXY;
// 为了完成事务管理,会向容器中添加通知
// 这个order属性代表了通知的执行优先级
// 默认是最低优先级
int order() default Ordered.LOWEST_PRECEDENCE;
}
需要注意的是,@EnableTransactionManagement的proxyTargetClass会影响Spring中所有通过自动代理生成的对象。如果将proxyTargetClass设置为true,那么意味通过@EnableAspectJAutoProxy所生成的代理对象也会使用cglib进行代理。关于@EnableTransactionManagement跟@EnableAspectJAutoProxy混用时的一些问题等我们在对@EnableTransactionManagement有一定了解后再专门做一个比较,现在我们先来看看这个注解到底在做了什么?
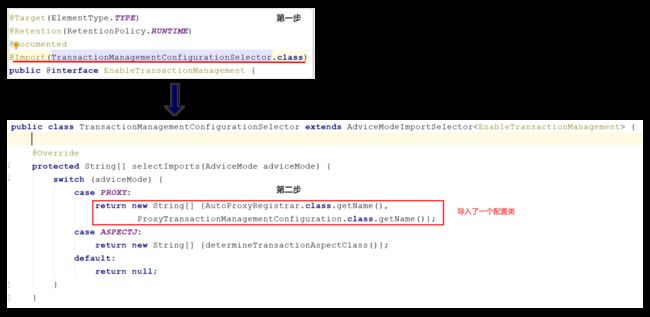
从上图中可以看出这个注解做的就是向容器中注册了AutoProxyRegistrar跟一个ProxyTransactionManagementConfiguration(这里就不考虑AspectJ了,我们平常都是使用SpringAOP),
AutoProxyRegistrar用于开启自动代理,其源码如下:
AutoProxyRegistrar分析
这个类实现了ImportBeanDefinitionRegistrar,它的作用是向容器中注册别的BeanDefinition,我们直接关注它的registerBeanDefinitions方法即可
// AnnotationMetadata,代表的是AutoProxyRegistrar的导入类的元信息
// 既包含了类元信息,也包含了注解元信息
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) {
boolean candidateFound = false;
// 获取@EnableTransactionManagement所在配置类上的注解元信息
Set annTypes = importingClassMetadata.getAnnotationTypes();
// 遍历注解
for (String annType : annTypes) {
// 可以理解为将注解中的属性转换成一个map
AnnotationAttributes candidate = AnnotationConfigUtils.attributesFor(importingClassMetadata, annType);
if (candidate == null) {
continue;
}
// 直接从map中获取对应的属性
Object mode = candidate.get("mode");
Object proxyTargetClass = candidate.get("proxyTargetClass");
// mode,代理模型,一般都是SpringAOP
// proxyTargetClass,是否使用cglib代理
if (mode != null && proxyTargetClass != null && AdviceMode.class == mode.getClass() &&
Boolean.class == proxyTargetClass.getClass()) {
// 注解中存在这两个属性,并且属性类型符合要求,表示找到了合适的注解
candidateFound = true;
// 实际上会往容器中注册一个InfrastructureAdvisorAutoProxyCreator
if (mode == AdviceMode.PROXY) {
AopConfigUtils.registerAutoProxyCreatorIfNecessary(registry);
if ((Boolean) proxyTargetClass) {
AopConfigUtils.forceAutoProxyCreatorToUseClassProxying(registry);
return;
}
}
}
}
// ......
}
@EnableTransactionManagement跟@EnableAspectJAutoProxy
如果对AOP比较了解的话,那么应该知道@EnableAspectJAutoProxy注解也向容器中注册了一个能实现自动代理的bd,那么当@EnableAspectJAutoProxy跟@EnableTransactionManagement同时使用会有什么问题吗?答案大家肯定知道,不会有问题,那么为什么呢?我们查看源码会发现,@EnableAspectJAutoProxy最终调用的是
AopConfigUtils#registerAspectJAnnotationAutoProxyCreatorIfNecessary,其源码如下
public static BeanDefinition registerAspectJAnnotationAutoProxyCreatorIfNecessary(
BeanDefinitionRegistry registry, @Nullable Object source) {
return registerOrEscalateApcAsRequired(AnnotationAwareAspectJAutoProxyCreator.class, registry, source);
}
@EnableTransactionManagement最终调用的是,AopConfigUtils#registerAutoProxyCreatorIfNecessary,其源码如下
public static BeanDefinition registerAutoProxyCreatorIfNecessary(
BeanDefinitionRegistry registry, @Nullable Object source) {
return registerOrEscalateApcAsRequired(InfrastructureAdvisorAutoProxyCreator.class, registry, source);
}
它们最终都会调用registerOrEscalateApcAsRequired方法,只不过传入的参数不一样而已,一个是AnnotationAwareAspectJAutoProxyCreator,另一个是InfrastructureAdvisorAutoProxyCreator。
registerOrEscalateApcAsRequired源码如下:
private static BeanDefinition registerOrEscalateApcAsRequired(
Class cls, BeanDefinitionRegistry registry, @Nullable Object source) {
if (registry.containsBeanDefinition(AUTO_PROXY_CREATOR_BEAN_NAME)) {
BeanDefinition apcDefinition = registry.getBeanDefinition(AUTO_PROXY_CREATOR_BEAN_NAME);
if (!cls.getName().equals(apcDefinition.getBeanClassName())) {
// 当前已经注册到容器中的Bean的优先级
int currentPriority = findPriorityForClass(apcDefinition.getBeanClassName());
// 当前准备注册到容器中的Bean的优先级
int requiredPriority = findPriorityForClass(cls);
// 谁的优先级大就注册谁,AnnotationAwareAspectJAutoProxyCreator是最大的
// 所以AnnotationAwareAspectJAutoProxyCreator会覆盖别的Bean
if (currentPriority < requiredPriority) {
apcDefinition.setBeanClassName(cls.getName());
}
}
return null;
}
// 注册bd
RootBeanDefinition beanDefinition = new RootBeanDefinition(cls);
beanDefinition.setSource(source);
beanDefinition.getPropertyValues().add("order", Ordered.HIGHEST_PRECEDENCE);
beanDefinition.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
registry.registerBeanDefinition(AUTO_PROXY_CREATOR_BEAN_NAME, beanDefinition);
return beanDefinition;
}
InfrastructureAdvisorAutoProxyCreator跟AnnotationAwareAspectJAutoProxyCreator的优先级是如何定义的呢?我们来看看AopConfigUtils这个类中的一个静态代码块
static {
APC_PRIORITY_LIST.add(InfrastructureAdvisorAutoProxyCreator.class);
APC_PRIORITY_LIST.add(AspectJAwareAdvisorAutoProxyCreator.class);
APC_PRIORITY_LIST.add(AnnotationAwareAspectJAutoProxyCreator.class);
}
实际上它们的优先级就是在APC_PRIORITY_LIST这个集合中的下标,下标越大优先级越高,所以AnnotationAwareAspectJAutoProxyCreator的优先级最高,所以AnnotationAwareAspectJAutoProxyCreator会覆盖InfrastructureAdvisorAutoProxyCreator,那么这种覆盖会不会造成问题呢?答案肯定是不会的,因为你用了这么久了也没出过问题嘛~那么再思考一个问题,为什么不会出现问题呢?这是因为InfrastructureAdvisorAutoProxyCreator只会使用容器内部定义的Advisor,但是AnnotationAwareAspectJAutoProxyCreator会使用所有实现了Advisor接口的通知,也就是说AnnotationAwareAspectJAutoProxyCreator的作用范围大于InfrastructureAdvisorAutoProxyCreator,因此这种覆盖是没有问题的。限于篇幅原因这个问题我不做详细解答了,有兴趣的同学可以看下两个类的源码。
@EnableTransactionManagement除了注册了一个AutoProxyRegistrar外,还向容器中注册了一个ProxyTransactionManagementConfiguration。
那么这个ProxyTransactionManagementConfiguration有什么作用呢?
如果大家对我文章的风格有一些了解的话就会知道,分析一个类一般有两个切入点
- 它的继承关系
- 它提供的API
大家自己在阅读源码时也可以参考这种思路,分析一个类的继承关系可以让我们了解它从抽象到实现的过程,即使不去细看API也能知道它的大体作用。仅仅知道它的大致作用是不够的,为了更好了解它的细节我们就需要进一步去探索它的具体实现,也就是它提供的API。这算是我看了这么就源码的一点心得,正好想到了所以在这里分享下,之后会专门写一篇源码心得的文章
ProxyTransactionManagementConfiguration分析
继承关系
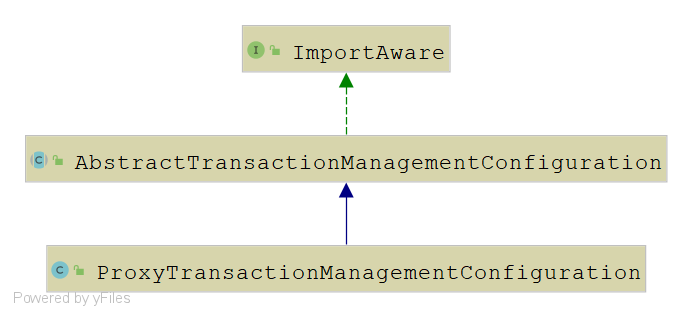
这个类的继承关系还是很简单的,只有一个父类AbstractTransactionManagementConfiguration
AbstractTransactionManagementConfiguration
源码如下:
@Configuration
public abstract class AbstractTransactionManagementConfiguration implements ImportAware {
@Nullable
protected AnnotationAttributes enableTx;
@Nullable
protected TransactionManager txManager;
// 这个方法就是获取@EnableTransactionManagement的属性
// importMetadata:就是@EnableTransactionManagement这个注解所在类的元信息
@Override
public void setImportMetadata(AnnotationMetadata importMetadata) {
// 将EnableTransactionManagement注解中的属性对存入到map中
// AnnotationAttributes实际上就是个map
this.enableTx = AnnotationAttributes.fromMap( importMetadata.getAnnotationAttributes(EnableTransactionManagement.class.getName(), false));
// 这里可以看到,限定了导入的注解必须使用@EnableTransactionManagement
if (this.enableTx == null) {
throw new IllegalArgumentException(
"@EnableTransactionManagement is not present on importing class " + importMetadata.getClassName());
}
}
// 我们可以配置TransactionManagementConfigurer
// 通过TransactionManagementConfigurer向容器中注册一个事务管理器
// 一般不会这么使用,更多的是通过@Bean的方式直接注册
@Autowired(required = false)
void setConfigurers(Collection configurers) {
// .....
TransactionManagementConfigurer configurer = configurers.iterator().next();
this.txManager = configurer.annotationDrivenTransactionManager();
}
// 向容器中注册一个TransactionalEventListenerFactory
// 这个类用于处理@TransactionalEventListener注解
// 可以实现对事件的监听,并且在事务的特定阶段对事件进行处理
@Bean(name = TransactionManagementConfigUtils.TRANSACTIONAL_EVENT_LISTENER_FACTORY_BEAN_NAME)
@Role(BeanDefinition.ROLE_INFRASTRUCTURE)
public static TransactionalEventListenerFactory transactionalEventListenerFactory() {
return new TransactionalEventListenerFactory();
}
}
TransactionalEventListenerFactory
上面的代码中大家可能比较不熟悉的就是TransactionalEventListenerFactory,这个类主要是用来处理@TransactionalEventListener注解的,我们来看一个实际使用的例子
@Component
public class DmzListener {
// 添加一个监听器
// phase = TransactionPhase.AFTER_COMMIT意味着这个方法在事务提交后执行
@TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)
public void listen(DmzTransactionEvent transactionEvent){
System.out.println("事务已提交");
}
}
// 定义一个事件
public class DmzTransactionEvent extends ApplicationEvent {
public DmzTransactionEvent(Object source) {
super(source);
}
}
@Component
public class DmzService {
@Autowired
ApplicationContext applicationContext;
// 一个需要进行事务管理的方法
@Transactional
public void invokeWithTransaction() {
// 发布一事件
applicationContext.publishEvent(new DmzTransactionEvent(this));
// 以一条sout语句提代sql执行过程
System.out.println("sql invoked");
}
}
// 测试方法
public class Main {
public static void main(String[] args) {
AnnotationConfigApplicationContext ac =
new AnnotationConfigApplicationContext(Config.class);
DmzService dmzService = ac.getBean(DmzService.class);
dmzService.invokeWithTransaction();
}
}
// 最后程序会按顺序输出
// sql invoked
// 事务已提交
通过上面的例子我们可以看到,虽然我们在invokeWithTransaction方法中一开始就发布了一个事件,但是监听事件的方法却是在invokeWithTransaction才执行的,正常事件的监听是同步的,假设我们将上述例子中的@TransactionalEventListener注解替换成为@EventListener注解,如下:
@Component
public class DmzListener {
// 添加一个监听器
@EventListener
public void listen(DmzTransactionEvent transactionEvent){
System.out.println("事务已提交");
}
}
这个时候程序的输出就会是
// 事务已提交
// sql invoked
那么@TransactionalEventListener注解是实现这种看似异步(实际上并不是)的监听方式的呢?

大家按照上面这个调用链可以找到这么一段代码

通过上面的代码,我们可以发现最终会调用到TransactionalEventListenerFactory的createApplicationListener方法,通过这个方法创建一个事件监听器然后添加到容器中,createApplicationListener方法源码如下:
public ApplicationListener createApplicationListener(String beanName, Class type, Method method) {
return new ApplicationListenerMethodTransactionalAdapter(beanName, type, method);
}
就是创建了一个ApplicationListenerMethodTransactionalAdapter,这个类本身就是一个事件监听器(实现了ApplicationListener接口)。我们直接关注它的事件监听方法,也就是onApplicationEvent方法,其源码如下:
@Override
public void onApplicationEvent(ApplicationEvent event) {
// 激活了同步,并且真实存在事务
if (TransactionSynchronizationManager.isSynchronizationActive() &&
TransactionSynchronizationManager.isActualTransactionActive()) {
// 实际上是依赖事务的同步机制实现的事件监听
TransactionSynchronization transactionSynchronization = createTransactionSynchronization(event);
TransactionSynchronizationManager.registerSynchronization(transactionSynchronization);
}
// 在没有开启事务的情况下是否处理事件
else if (this.annotation.fallbackExecution()) {
// ....
// 如果注解中的fallbackExecution为true,意味着没有事务开启的话
// 也会执行监听逻辑
processEvent(event);
}
else {
// ....
}
}
到这一步逻辑已经清楚了,@TransactionalEventListener所标注的方法在容器启动时被解析成了一个ApplicationListenerMethodTransactionalAdapter,这个类本身就是一个事件监听器,当容器中的组件发布了一个事件后,如果事件匹配,会进入它的onApplicationEvent方法,这个方法并没有直接执行我们所定义的监听逻辑,而是给当前事务注册了一个同步的行为,当事务到达某一个阶段时,这个行为会被触发。通过这种方式,实现一种伪异步。实际上注册到事务的的同步就是TransactionSynchronizationEventAdapter,这个类的源码非常简单,这里就单独取它一个方法看下
// 这个方法会在事务提交前执行
public void beforeCommit(boolean readOnly) {
// 在执行时会先判断在@TransactionalEventListener注解中定义的phase是不是BEFORE_COMMIT
// 如果不是的话,什么事情都不做
if (this.phase == TransactionPhase.BEFORE_COMMIT) {
processEvent();
}
}
别看上面这么多内容,到目前为止我们还是只对ProxyTransactionManagementConfiguration的父类做了介绍,接下来我们就来看看ProxyTransactionManagementConfiguration自身做了什么事情。
源码分析
// proxyBeanMethods=false,意味着不对配置类生成代理对象
@Configuration(proxyBeanMethods = false)
@Role(BeanDefinition.ROLE_INFRASTRUCTURE)
public class ProxyTransactionManagementConfiguration extends AbstractTransactionManagementConfiguration {
// 注册了一个BeanFactoryTransactionAttributeSourceAdvisor
// advisor就是一个绑定了切点的通知
// 可以看到通知就是TransactionInterceptor
// 切点会通过TransactionAttributeSource去解析@Transacational注解
// 只会对有这个注解的方法进行拦截
@Bean(name = TransactionManagementConfigUtils.TRANSACTION_ADVISOR_BEAN_NAME)
// BeanDefinition的角色是一个基础设施类
@Role(BeanDefinition.ROLE_INFRASTRUCTURE)
public BeanFactoryTransactionAttributeSourceAdvisor transactionAdvisor(
TransactionAttributeSource transactionAttributeSource, TransactionInterceptor transactionInterceptor) {
BeanFactoryTransactionAttributeSourceAdvisor advisor = new BeanFactoryTransactionAttributeSourceAdvisor();
advisor.setTransactionAttributeSource(transactionAttributeSource);
advisor.setAdvice(transactionInterceptor);
if (this.enableTx != null) {
advisor.setOrder(this.enableTx.getNumber("order"));
}
return advisor;
}
// 注册一个AnnotationTransactionAttributeSource
// 这个类的主要作用是用来解析@Transacational注解
@Bean
@Role(BeanDefinition.ROLE_INFRASTRUCTURE)
public TransactionAttributeSource transactionAttributeSource() {
return new AnnotationTransactionAttributeSource();
}
// 事务是通过AOP实现的,AOP的核心就是拦截器
// 这里就是注册了实现事务需要的拦截器
@Bean
@Role(BeanDefinition.ROLE_INFRASTRUCTURE)
public TransactionInterceptor transactionInterceptor(TransactionAttributeSource transactionAttributeSource) {
TransactionInterceptor interceptor = new TransactionInterceptor();
interceptor.setTransactionAttributeSource(transactionAttributeSource);
if (this.txManager != null) {
interceptor.setTransactionManager(this.txManager);
}
return interceptor;
}
}
实现事务管理的核心就是SpringAOP,而完成SpringAOP的核心就是通知(Advice),通知的核心就是拦截器,关于SpringAOP、切点、通知在之前的文章中已经做过详细介绍了,所以对这一块本文就跳过了,我们直接定位到事务管理的核心TransactionInterceptor。
TransactionInterceptor分析
TransactionInterceptor实现了MethodInterceptor,核心方法就是invoke方法,我们直接定位到这个方法的具体实现逻辑
// invocation:代表了要进行事务管理的方法
public Object invoke(MethodInvocation invocation) throws Throwable {
Class targetClass = (invocation.getThis() != null ? AopUtils.getTargetClass(invocation.getThis()) : null);
// 核心方法就是invokeWithinTransaction
return invokeWithinTransaction(invocation.getMethod(), targetClass, invocation::proceed);
}
invokeWithinTransaction方法分析
这个方法很长,但是主要可以分为三段
- 响应式事务管理
- 标准事务管理
- 通过回调实现事务管理
这里我们只分析标准事务管理,下面的源码也只保留标准事务管理相关代码
protected Object invokeWithinTransaction(Method method, @Nullable Class targetClass,
final InvocationCallback invocation) throws Throwable {
// 之前在配置类中注册了一个AnnotationTransactionAttributeSource
// 这里就是直接返回了之前注册的那个Bean,通过它去获取事务属性
TransactionAttributeSource tas = getTransactionAttributeSource();
// 解析@Transactional注解获取事务属性
final TransactionAttribute txAttr = (tas != null ? tas.getTransactionAttribute(method, targetClass) : null);
// 获取对应的事务管理器
final TransactionManager tm = determineTransactionManager(txAttr);
// ...
// 忽略响应式的事务管理
// ...
// 做了个强转PlatformTransactionManager
PlatformTransactionManager ptm = asPlatformTransactionManager(tm);
// 切点名称(类名+方法名),会被作为事务的名称
final String joinpointIdentification = methodIdentification(method, targetClass, txAttr);
if (txAttr == null || !(ptm instanceof CallbackPreferringPlatformTransactionManager)) { // 创建事务
TransactionInfo txInfo = createTransactionIfNecessary(ptm, txAttr, joinpointIdentification);
Object retVal;
try {
// 这里执行真正的业务逻辑
retVal = invocation.proceedWithInvocation();
}
catch (Throwable ex) {
// 方法执行出现异常,在异常情况下完成事务
completeTransactionAfterThrowing(txInfo, ex);
throw ex;
}
finally {
// 清除线程中的事务信息
cleanupTransactionInfo(txInfo);
}
// ...
// 省略不重要代码
// ...
// 提交事务
commitTransactionAfterReturning(txInfo);
return retVal;
}
// ....
// 省略回调实现事务管理相关代码
// ....
return result;
}
}
通过上面这段代码可以归纳出事务管理的流程如下:
- 获取事务属性------->
tas.getTransactionAttribute - 创建事务------------->
createTransactionIfNecessary - 执行业务逻辑------->
invocation.proceedWithInvocation - 异常时完成事务---->
completeTransactionAfterThrowing - 清除线程中绑定的事务信息----->
cleanupTransactionInfo - 提交事务------------->
commitTransactionAfterReturning
接下来我们一步步分析
1、获取事务属性
// 获取事务对应的属性,实际上返回一个AnnotationTransactionAttributeSource
// 之后再调用AnnotationTransactionAttributeSource的getTransactionAttribute
// getTransactionAttribute:先从拦截的方法上找@Transactional注解
// 如果方法上没有的话,再从方法所在的类上找,如果类上还没有的话尝试从接口或者父类上找
public TransactionAttribute getTransactionAttribute(Method method, @Nullable Class targetClass) {
if (method.getDeclaringClass() == Object.class) {
return null;
}
// 在缓存中查找
Object cacheKey = getCacheKey(method, targetClass);
TransactionAttribute cached = this.attributeCache.get(cacheKey);
if (cached != null) {
if (cached == NULL_TRANSACTION_ATTRIBUTE) {
return null;
}
else {
return cached;
}
}
else {
// 这里真正的去执行解析
TransactionAttribute txAttr = computeTransactionAttribute(method, targetClass);
// 缓存解析的结果,如果为事务属性为null,也放入一个标志
// 代表这个方法不需要进行事务管理
if (txAttr == null) {
this.attributeCache.put(cacheKey, NULL_TRANSACTION_ATTRIBUTE);
}
else {
String methodIdentification = ClassUtils.getQualifiedMethodName(method, targetClass);
if (txAttr instanceof DefaultTransactionAttribute) {
((DefaultTransactionAttribute) txAttr).setDescriptor(methodIdentification);
}
this.attributeCache.put(cacheKey, txAttr);
}
return txAttr;
}
}
真正解析注解时调用了computeTransactionAttribute方法,其代码如下:
protected TransactionAttribute computeTransactionAttribute(Method method, @Nullable Class targetClass) {
// 默认情况下allowPublicMethodsOnly为true
// 这意味着@Transactional如果放在非public方法上不会生效
if (allowPublicMethodsOnly() && !Modifier.isPublic(method.getModifiers())) {
return null;
}
// method是接口中的方法
// specificMethod是具体实现类的方法
Method specificMethod = AopUtils.getMostSpecificMethod(method, targetClass);
// 现在目标类方法上找
TransactionAttribute txAttr = findTransactionAttribute(specificMethod);
if (txAttr != null) {
return txAttr;
}
// 再在目标类上找
txAttr = findTransactionAttribute(specificMethod.getDeclaringClass());
if (txAttr != null && ClassUtils.isUserLevelMethod(method)) {
return txAttr;
}
// 降级到接口跟接口中的方法上找这个注解
if (specificMethod != method) {
txAttr = findTransactionAttribute(method);
if (txAttr != null) {
return txAttr;
}
txAttr = findTransactionAttribute(method.getDeclaringClass());
if (txAttr != null && ClassUtils.isUserLevelMethod(method)) {
return txAttr;
}
}
return null;
}
可以看到在computeTransactionAttribute方法中又进一步调用了findTransactionAttribute方法,我们一步步跟踪最终会进入到SpringTransactionAnnotationParser#parseTransactionAnnotation(AnnotationAttributes)这个方法中
整个调用链我这里也画出来了,感兴趣的大家可以跟一下
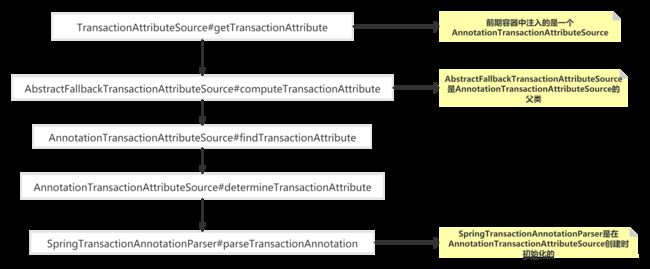
对于本文,我们直接定位到最后一步,对应源码如下:
protected TransactionAttribute parseTransactionAnnotation(AnnotationAttributes attributes) {
// 最终返回的是一个RuleBasedTransactionAttribute
// 在上篇文章分析过了,定义了在出现异常时如何回滚
RuleBasedTransactionAttribute rbta = new RuleBasedTransactionAttribute();
Propagation propagation = attributes.getEnum("propagation");
rbta.setPropagationBehavior(propagation.value());
Isolation isolation = attributes.getEnum("isolation");
rbta.setIsolationLevel(isolation.value());
rbta.setTimeout(attributes.getNumber("timeout").intValue());
rbta.setReadOnly(attributes.getBoolean("readOnly"));
rbta.setQualifier(attributes.getString("value"));
List rollbackRules = new ArrayList<>();
for (Class rbRule : attributes.getClassArray("rollbackFor")) {
rollbackRules.add(new RollbackRuleAttribute(rbRule));
}
for (String rbRule : attributes.getStringArray("rollbackForClassName")) {
rollbackRules.add(new RollbackRuleAttribute(rbRule));
}
for (Class rbRule : attributes.getClassArray("noRollbackFor")) {
rollbackRules.add(new NoRollbackRuleAttribute(rbRule));
}
for (String rbRule : attributes.getStringArray("noRollbackForClassName")) {
rollbackRules.add(new NoRollbackRuleAttribute(rbRule));
}
rbta.setRollbackRules(rollbackRules);
return rbta;
}
到这一步很明确了,解析了@Transactional注解,并将这个注解的属性封装到了一个RuleBasedTransactionAttribute对象中返回。
2、 创建事务
对应代码如下:
protected TransactionInfo createTransactionIfNecessary(@Nullable PlatformTransactionManager tm,
@Nullable TransactionAttribute txAttr, final String joinpointIdentification) {
// 如果没有为事务指定名称,使用切点作为事务名称
if (txAttr != null && txAttr.getName() == null) {
txAttr = new DelegatingTransactionAttribute(txAttr) {
@Override
public String getName() {
return joinpointIdentification;
}
};
}
TransactionStatus status = null;
if (txAttr != null) {
if (tm != null) {
// 调用事务管理器的方法,获取一个事务并返回事务的状态
status = tm.getTransaction(txAttr);
}
// ....省略日志
}
// 将事务相关信息封装到TransactionInfo对象中
// 并将TransactionInfo绑定到当前线程
return prepareTransactionInfo(tm, txAttr, joinpointIdentification, status);
}
从上面方法签名上我们可以看到,创建事务实际上就是创建了一个TransactionInfo。一个TransactionInfo对象包含了事务相关的所有信息,例如实现事务使用的事务管理器(PlatformTransactionManager),事务的属性(TransactionAttribute),事务的状态(transactionStatus)以及与当前创建的关联的上一个事务信息(oldTransactionInfo)。我们可以通过TransactionInfo对象的hasTransaction方法判断是否真正创建了一个事务。
上面的核心代码只有两句
tm.getTransaction,通过事务管理器创建事务prepareTransactionInfo,封装TransactionInfo并绑定到线程上
我们先来看看getTransaction干了啥,对应代码如下:
这个代码应该是整个Spring实现事务管理里面最难的了,因为牵涉到事务的传播机制,不同传播级别是如何进行处理的就是下面这段代码决定的,比较难,希望大家能耐心看完
public final TransactionStatus getTransaction(@Nullable TransactionDefinition definition)
throws TransactionException {
// 事务的属性(TransactionAttribute),通过解析@Transacational注解de'dao
TransactionDefinition def = (definition != null ? definition : TransactionDefinition.withDefaults());
// 获取一个数据库事务对象(DataSourceTransactionObject),
// 这个对象中封装了一个从当前线程上下文中获取到的连接
Object transaction = doGetTransaction();
boolean debugEnabled = logger.isDebugEnabled();
// 判断是否存在事务
// 如果之前获取到的连接不为空,并且连接上激活了事务,那么就为true
if (isExistingTransaction(transaction)) {
// 如果已经存在了事务,需要根据不同传播机制进行不同的处理
return handleExistingTransaction(def, transaction, debugEnabled);
}
// 校验事务的超时设置,默认为-1,代表不进行超时检查
if (def.getTimeout() < TransactionDefinition.TIMEOUT_DEFAULT) {
throw new InvalidTimeoutException("Invalid transaction timeout", def.getTimeout());
}
// 检查隔离级别是否为mandatory(强制性要求必须开启事务)
// 如果为mandatory,但是没有事务存在,那么抛出异常
if (def.getPropagationBehavior() == TransactionDefinition.PROPAGATION_MANDATORY) {
throw new IllegalTransactionStateException(
"No existing transaction found for transaction marked with propagation 'mandatory'");
}
// 目前为止没有事务,并且隔离级别不是mandatory
else if (def.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRED ||
def.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRES_NEW ||
def.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NESTED) {
// 当隔离级别为required,required_new,nested时均需要新建事务
// 如果存在同步,将注册的同步挂起
SuspendedResourcesHolder suspendedResources = suspend(null);
if (debugEnabled) {
logger.debug("Creating new transaction with name [" + def.getName() + "]: " + def);
}
try {
// 开启一个新事务
return startTransaction(def, transaction, debugEnabled, suspendedResources);
}
catch (RuntimeException | Error ex) {
resume(null, suspendedResources);
throw ex;
}
}
else {
// 创建一个空事务,没有实际的事务提交以及回滚机制
// 会激活同步:将数据库连接绑定到当前线程上
boolean newSynchronization = (getTransactionSynchronization() == SYNCHRONIZATION_ALWAYS);
return prepareTransactionStatus(def, null, true, newSynchronization, debugEnabled, null);
}
}
上面这段代码可以分为两种情况分析
-
应用程序直接调用了一个被事务管理的方法(直接调用)
-
在一个需要事务管理的方法中调用了另外一个需要事务管理的方法(嵌套调用)
用代码表示如下:
@Service
public class IndexService {
@Autowired
DmzService dmzService;
// 直接调用
@Transactional
public void directTransaction(){
// ......
}
// 嵌套调用
@Transactional
public void nestedTransaction(){
dmzService.directTransaction();
}
}
ps:我们暂且不考虑自调用的情况,因为自调用可能会出现事务失效,在下篇文章我们专门来聊一聊事务管理中的那些坑
直接调用
我们先来看看直接调用的情况下上述代码时如何执行的
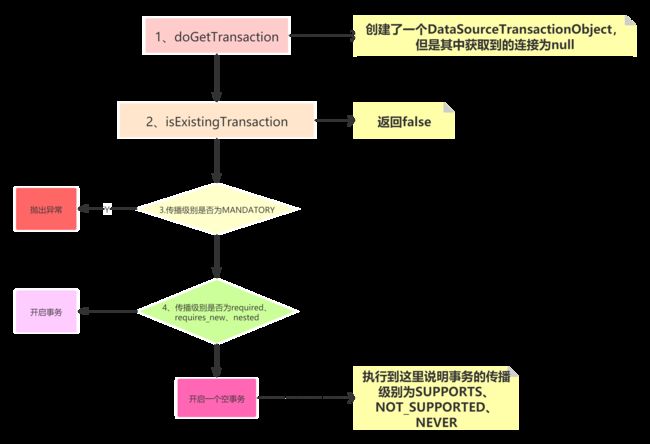
doGetTransaction源码分析
protected Object doGetTransaction() {
DataSourceTransactionObject txObject = new DataSourceTransactionObject();
// 在创建DataSourceTransactionManager将其设置为了true
// 标志是否允许
txObject.setSavepointAllowed(isNestedTransactionAllowed());
// 从线程上下文中获取到对应的这个连接池中的连接
// 获取对应数据源下的这个绑定的连接
// 当我们将数据库连接绑定到线程上时,实际上绑定到当前线程的是一个map
// 其中key是对应的数据源,value是通过这个数据源获取的一个连接
ConnectionHolder conHolder =(ConnectionHolder)TransactionSynchronizationManager
.getResource(obtainDataSource());
// 如果当前上下文中已经有这个连接了,那么将newConnectionHolder这个标志设置为false
// 代表复用了之前的连接(不是一个新连接)
txObject.setConnectionHolder(conHolder, false);
return txObject;
}
直接调用的情况下,获取到的连接肯定为空,所以这里返回的是一个没有持有数据库连接的DataSourceTransactionObject。
isExistingTransaction源码分析
protected boolean isExistingTransaction(Object transaction) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) transaction;
// 只有在存在连接并且连接上已经激活了事务才会返回true
return (txObject.hasConnectionHolder() && txObject.getConnectionHolder().isTransactionActive());
}
直接调用的情况下,这里肯定是返回fasle
- 从这里可以看出,如果直接调用了一个传播级别为
MANDATORY的方法将会抛出异常 - 传播级别为
required、requires_new、nested时,会真正开启事务,对应代码如下
else if (def.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRED ||
def.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRES_NEW ||
def.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NESTED) {
// 如果存在同步,将注册的同步挂起
SuspendedResourcesHolder suspendedResources = suspend(null);
if (debugEnabled) {
logger.debug("Creating new transaction with name [" + def.getName() + "]: " + def);
}
try {
// 开启一个新事务
return startTransaction(def, transaction, debugEnabled, suspendedResources);
}
catch (RuntimeException | Error ex) {
resume(null, suspendedResources);
throw ex;
}
}
我们先来看看它的挂起操作干了什么,对应代码如下:
// 直接调用时,传入的transaction为null
protected final SuspendedResourcesHolder suspend(@Nullable Object transaction) throws TransactionException {
// 在之前的代码中没有进行任何激活同步的操作,所以不会进入下面这个判断
if (TransactionSynchronizationManager.isSynchronizationActive()) {
// ...
}
// 传入的transaction为null,这个判断也不进
else if (transaction != null) {
// ...
}
else {
return null;
}
}
从上面可以看出,这段代码其实啥都没干,OK,减负,直接跳过。
接着,就是真正的开启事务了,会调用一个startTransaction方法,对应代码如下:
private TransactionStatus startTransaction(TransactionDefinition definition, Object transaction,
boolean debugEnabled, @Nullable SuspendedResourcesHolder suspendedResources) {
// 默认情况下,getTransactionSynchronization方法会返回SYNCHRONIZATION_ALWAYS
// 所以这里是true
boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
// 根据之前的事务定义等相关信息构造一个事务状态对象
DefaultTransactionStatus status = newTransactionStatus(
definition, transaction, true, newSynchronization, debugEnabled, suspendedResources);
// 真正开启事务,会从数据源中获取连接并绑定到线程上
doBegin(transaction, definition);
// 在这里会激活同步
prepareSynchronization(status, definition);
return status;
}
newTransactionStatus实际上就是调用了DefaultTransactionStatus的构造函数,我们来看一看每个参数的含义以及实际传入的是什么。对应代码如下:
// definition:事务的定义,解析@Transactional注解得到的
// transaction:通过前面的doGetTransaction方法得到的,关联了一个数据库连接
// newTransaction:是否是一个新的事务
// debug:是否开启debug级别日志
// newSynchronization:是否需要一个新的同步
// suspendedResources:代表了执行当前事务时挂起的资源
protected DefaultTransactionStatus newTransactionStatus(
TransactionDefinition definition, @Nullable Object transaction, boolean newTransaction,
boolean newSynchronization, boolean debug, @Nullable Object suspendedResources) {
// 是否是一个真实的新的同步
// 除了传入的标志之外还需要判断当前线程上的同步是否激活
// 没有激活才算是一个真正的新的同步
boolean actualNewSynchronization = newSynchronization &&
!TransactionSynchronizationManager.isSynchronizationActive();
// 返回一个事务状态对象
// 包含了事务的定于、事务使用的连接、事务是否要开启一个新的同步、事务挂起的资源等
return new DefaultTransactionStatus(
transaction, newTransaction, actualNewSynchronization,
definition.isReadOnly(), debug, suspendedResources);
}
在完成事务状态对象的构造之后,就是真正的开启事务了,我们也不难猜出所谓开启事务其实就是从数据源中获取一个一个连接并设置autoCommit为false。对应代码如下:
protected void doBegin(Object transaction, TransactionDefinition definition) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) transaction;
Connection con = null;
try {
// 判断txObject中是否存在连接并且连接上已经激活了事务
// txObject是通过之前的doGetTransaction方法得到的
// 直接调用的情况下,这个判断肯定为true
if (!txObject.hasConnectionHolder() ||
txObject.getConnectionHolder().isSynchronizedWithTransaction()) {
// 从数据源中获取一个连接
Connection newCon = obtainDataSource().getConnection();
}
// 将连接放入到txObject中
// 第二个参数为true,标志这是一个新连接
txObject.setConnectionHolder(new ConnectionHolder(newCon), true);
}
// 标志连接资源跟事务同步
txObject.getConnectionHolder().setSynchronizedWithTransaction(true);
con = txObject.getConnectionHolder().getConnection();
// 应用事务定义中的read only跟隔离级别
// 实际就是调用了Connection的setReadOnly跟setTransactionIsolation方法
// 如果事务定义中的隔离级别跟数据库默认的隔离级别不一致会返回的是数据库默认的隔离级别
// 否则返回null
// 主要是为了在事务完成后能将连接状态恢复
Integer previousIsolationLevel = DataSourceUtils.prepareConnectionForTransaction(con, definition);
txObject.setPreviousIsolationLevel(previousIsolationLevel);
txObject.setReadOnly(definition.isReadOnly());
// 设置autoCommit为false,显示开启事务
if (con.getAutoCommit()) {
// 代表在事务完成后需要将连接重置为autoCommit=true
// 跟之前的previousIsolationLevel作用一样,都是为了恢复连接
txObject.setMustRestoreAutoCommit(true);
con.setAutoCommit(false);
}
// 是否通过显示的语句设置read only,默认是不需要的
prepareTransactionalConnection(con, definition);
txObject.getConnectionHolder().setTransactionActive(true);
// 设置超时时间
int timeout = determineTimeout(definition);
if (timeout != TransactionDefinition.TIMEOUT_DEFAULT) {
txObject.getConnectionHolder().setTimeoutInSeconds(timeout);
}
// 将连接绑定到当前线程上下文中,实际存入到线程上下文的是一个map
// 其中key为数据源,value为从该数据源中获取的一个连接
if (txObject.isNewConnectionHolder()) {
TransactionSynchronizationManager.bindResource(obtainDataSource(), txObject.getConnectionHolder());
}
}
catch (Throwable ex) {
// 出现异常的话,需要归还连接
if (txObject.isNewConnectionHolder()) {
DataSourceUtils.releaseConnection(con, obtainDataSource());
txObject.setConnectionHolder(null, false);
}
throw new CannotCreateTransactionException("Could not open JDBC Connection for transaction", ex);
}
}
归纳起来,doBegin做了这么几件事
- 从数据源中获取一个连接
- 将事务定义应用到这个连接上
- 通过这个连接对象显示开启事务
- 将这个连接绑定到线程上下文
在通过doBegin开启了事务后,接下来调用了prepareSynchronization,这个方法的主要目的就是为了准备这个事务需要的同步,对应源码如下:
protected void prepareSynchronization(DefaultTransactionStatus status, TransactionDefinition definition) {
if (status.isNewSynchronization()) {
// 到这里真正激活了事务
TransactionSynchronizationManager.setActualTransactionActive(status.hasTransaction());
// 隔离级别
// 只有在不是默认隔离级别的情况下才会绑定到线程上,否则绑定一个null
TransactionSynchronizationManager.setCurrentTransactionIsolationLevel(
definition.getIsolationLevel() != TransactionDefinition.ISOLATION_DEFAULT ?
definition.getIsolationLevel() : null);
// 是否只读
TransactionSynchronizationManager.setCurrentTransactionReadOnly(definition.isReadOnly());
TransactionSynchronizationManager.setCurrentTransactionName(definition.getName());
// 初始化同步行为
TransactionSynchronizationManager.initSynchronization();
}
}
主要对一些信息进行了同步,例如事务真正激活了事务,事务隔离级别,事务名称,是否只读。同时初始化了同步事务过程中要执行的一些回调(也就是一些同步的行为)
在前面我们已经介绍了在直接调用的情况下,如果传播级别为mandatory会直接抛出异常,传播级别为required、requires_new、nested时,会调用startTransaction真正开启一个事务,但是除了这几种传播级别之外还有supports、not_supported、never。这几种传播级别在直接调用时会做什么呢?前面那张图我其实已经画出来了,会开启一个空事务("empty" transaction),对应代码如下:
public final TransactionStatus getTransaction(@Nullable TransactionDefinition definition)
throws TransactionException {
// ......
// mandatory抛出异常
// required、requires_new、nested调用startTransaction开启事务
// supports、not_supported、never会进入下面这个判断
else {
// 默认同步级别就是always
boolean newSynchronization = (getTransactionSynchronization() == SYNCHRONIZATION_ALWAYS);
// 直接调用prepareTransactionStatus返回一个事务状态对象
return prepareTransactionStatus(def, null, true, newSynchronization, debugEnabled, null);
}
}
prepareTransactionStatus代码如下
// 传入的参数为:def, null, true, newSynchronization, debugEnabled, null
protected final DefaultTransactionStatus prepareTransactionStatus(
TransactionDefinition definition, @Nullable Object transaction, boolean newTransaction,
boolean newSynchronization, boolean debug, @Nullable Object suspendedResources) {
// 调用这个方法时
// definition:传入的是解析@Transactional注解得到的事务属性
// transaction:写死的传入为null,意味着没有真正的事务()
// newTransaction:写死的传入为true
// newSynchronization:默认同步级别为always,在没有真正事务的时候也进行同步
// suspendedResources:写死了,传入为null,不挂起任何资源
DefaultTransactionStatus status = newTransactionStatus(
definition, transaction, newTransaction, newSynchronization, debug, suspendedResources);
prepareSynchronization(status, definition);
return status;
}
可以看到这个方法跟之前介绍的startTransaction方法相比较下就有几点不同,最明显的是少了一个步骤,在prepareTransactionStatus方法中没有调用doBegin方法,这意味这个这个方法不会去获取数据库连接,更不会绑定数据库连接到上下文中,仅仅是做了一个同步的初始化。
其次,startTransaction方法在调用newTransactionStatus传入的第二个参数是从doGetTransaction方法中获取的,不可能为null,而调用prepareTransactionStatus方法时,写死的传入为null。这也代表了prepareTransactionStatus不会真正开启一个事务。
虽然不会真正开启一个事务,只是开启了一个“空事务”,但是当这个空事务完成时仍然会触发注册的回调。
嵌套调用

前面已经介绍了在直接调用下七种不同隔离级别在创建事务时的不同表现,代码看似很多,实际还是比较简单的,接下来我们要介绍的就是嵌套调用,也就是已经存在事务的情况下,调用了另外一个被事务管理的方法(并且事务管理是生效的)。我们需要关注的是下面这段代码
public final TransactionStatus getTransaction(@Nullable TransactionDefinition definition)
throws TransactionException {
// 事务的属性(TransactionAttribute)
TransactionDefinition def = (definition != null ? definition : TransactionDefinition.withDefaults());
// 从线程上下文中获取到一个连接,并封装到一个DataSourceTransactionObject对象中
Object transaction = doGetTransaction();
boolean debugEnabled = logger.isDebugEnabled();
// 判断之前获取到的事务上是否有连接,并且连接上激活了事务
if (isExistingTransaction(transaction))
// 嵌套调用处理在这里
return handleExistingTransaction(def, transaction, debugEnabled);
}
// ...
// 下面是直接调用的情况,前文已经分析过了
// 省略直接调用的相关代码
}
处理嵌套调用的核心代码其实就是handleExistingTransaction。但是进入这个方法前首先isExistingTransaction这个方法得返回true才行,所以我们先来看看isExistingTransaction这个方法做了什么,代码如下:
protected boolean isExistingTransaction(Object transaction) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) transaction;
// 首先判断txObject中是否已经绑定了连接
// 其次判断这个连接上是否已经激活了事务
return (txObject.hasConnectionHolder() && txObject.getConnectionHolder().isTransactionActive());
}
结合我们之前分析的直接调用的代码逻辑,可以看出,只有外围的事务的传播级别为required、requires_new、nested时,这个判断才会成立。因为只有在这些传播级别下才会真正的开启事务,才会将连接绑定到当前线程,doGetTransaction方法才能返回一个已经绑定了数据库连接的事务对象。
在满足了isExistingTransaction时,会进入嵌套调用的处理逻辑,也就是handleExistingTransaction方法,其代码如下:
代码很长,但是大家跟着我一步步梳理就可以了,其实逻辑也不算特别复杂
整个代码逻辑其实就是为了实现事务的传播,在不同的传播级别下做不同的事情
private TransactionStatus handleExistingTransaction(
TransactionDefinition definition, Object transaction, boolean debugEnabled)
throws TransactionException {
// 如果嵌套的事务的传播级别为never,那么直接抛出异常
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NEVER) {
throw new IllegalTransactionStateException(
"Existing transaction found for transaction marked with propagation 'never'");
}
// 如果嵌套的事务的传播级别为not_soupported,那么挂起外围事务
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NOT_SUPPORTED) {
if (debugEnabled) {
logger.debug("Suspending current transaction");
}
// 挂起外围事务
Object suspendedResources = suspend(transaction);
boolean newSynchronization = (getTransactionSynchronization() == SYNCHRONIZATION_ALWAYS);
// 开启一个新的空事务
return prepareTransactionStatus(
definition, null, false, newSynchronization, debugEnabled, suspendedResources);
}
// 如果嵌套的事务传播级别为requires_new,那么挂起外围事务,并且新建一个新的事务
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRES_NEW) {
SuspendedResourcesHolder suspendedResources = suspend(transaction);
try {
return startTransaction(definition, transaction, debugEnabled, suspendedResources);
}
catch (RuntimeException | Error beginEx) {
resumeAfterBeginException(transaction, suspendedResources, beginEx);
throw beginEx;
}
}
// 如果嵌套事务的传播级别为nested,会获取当前线程绑定的数据库连接
// 并通过数据库连接创建一个保存点(save point)
// 其实就是调用Connection的setSavepoint方法
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NESTED) {
// 默认是允许的,所以这个判断不会成立
if (!isNestedTransactionAllowed()) {
throw new NestedTransactionNotSupportedException(
"Transaction manager does not allow nested transactions by default - " +
"specify 'nestedTransactionAllowed' property with value 'true'");
}
// 默认是true
if (useSavepointForNestedTransaction()) {
DefaultTransactionStatus status =
prepareTransactionStatus(definition, transaction, false, false, debugEnabled, null);
status.createAndHoldSavepoint();
return status;
}
else {
// JTA进行事务管理才会进入这这里,我们不做考虑
return startTransaction(definition, transaction, debugEnabled, null);
}
}
if (debugEnabled) {
logger.debug("Participating in existing transaction");
}
// 嵌套事务传播级别为supports、required、mandatory时,是否需要校验嵌套事务的属性
// 主要校验的是个隔离级别跟只读属性
// 默认是不需要校验的
// 如果开启了校验,那么会判断如果外围事务的隔离级别跟嵌套事务的隔离级别是否一致
// 如果不一致,直接抛出异常
if (isValidateExistingTransaction()) {
if (definition.getIsolationLevel() != TransactionDefinition.ISOLATION_DEFAULT) {
Integer currentIsolationLevel = TransactionSynchronizationManager.getCurrentTransactionIsolationLevel();
if (currentIsolationLevel == null || currentIsolationLevel != definition.getIsolationLevel()) {
Constants isoConstants = DefaultTransactionDefinition.constants;
// 这里会抛出异常
}
}
// 嵌套事务的只读为false
if (!definition.isReadOnly()) {
// 但是外围事务的只读为true,那么直接抛出异常
if (TransactionSynchronizationManager.isCurrentTransactionReadOnly()) {
// 这里会抛出异常
}
}
}
boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
return prepareTransactionStatus(definition, transaction, false, newSynchronization, debugEnabled, null);
}
观察上面的代码我们可以发现,返回值只有两个情况(不考虑抛出异常)
- 调用了
startTransaction方法 - 调用了
prepareTransactionStatus方法
在前面我们已经介绍了这两个方法的区别,相比较于startTransaction方法,prepareTransactionStatus并不会再去数据源中获取连接。
另外我们还可以发现,只有传播级别为required_new的情况才会去调用startTransaction方法(不考虑JTA),也就是说,只有required_new才会真正的获取一个新的数据库连接,其余的情况如果支持事务的话都是复用了外围事务获取到的连接,也就是说它们其实是加入了外围的事务中,例如supports、required、mandatory、nested,其中nested又比较特殊,因为它不仅仅是单纯的加入了外围的事务,而且在加入前设置了一个保存点,如果仅仅是嵌套事务发生了异常,会回滚到之前设置的这个保存点上。另外需要注意的是,因为是直接复用了外部事务的连接,所以supports、required、mandatory、nested这几种传播级别下,嵌套的事务会随着外部事务的提交而提交,同时也会跟着外部事物的回滚而回滚。
接下来我们开始细节性的分析上边的代码,对于传播级别为never,没啥好说的,直接抛出异常,因为不支持在事务中运行嘛~
当传播级别为not_supported时会进入下面这段代码
// 如果嵌套的事务的传播级别为not_soupported,那么挂起外围事务
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NOT_SUPPORTED) {
if (debugEnabled) {
logger.debug("Suspending current transaction");
}
// 挂起外围事务
Object suspendedResources = suspend(transaction);
boolean newSynchronization = (getTransactionSynchronization() == SYNCHRONIZATION_ALWAYS);
// 开启一个新的空事务
return prepareTransactionStatus(
definition, null, false, newSynchronization, debugEnabled, suspendedResources);
}
主要就是两个动作,首先挂起外围事务。很多同学可能不是很理解挂起这个词的含义,挂起实际上做了什么呢?
- 清空外围事务绑定在线程上的同步
- 挂起是因为将来还要恢复,所以不能单纯的只是清空呀,还得将清空的信息保存到当前的事务上,这样当当前的事务完成后可以恢复到挂起时的状态,以便于外围的事务能够正确的运行下去
其中第一步对应的代码如下:
protected final SuspendedResourcesHolder suspend(@Nullable Object transaction) throws TransactionException {
// 嵌套调用下,同步是已经被激活了的
if (TransactionSynchronizationManager.isSynchronizationActive()) {
// 解绑线程上绑定的同步回调,并返回
List suspendedSynchronizations = doSuspendSynchronization();
try {
Object suspendedResources = null;
if (transaction != null) {
// 这里实际上就是解绑线程上绑定的数据库连接
// 同时返回这个连接
suspendedResources = doSuspend(transaction);
}
// 解绑线程上绑定的事务属性并返回
String name = TransactionSynchronizationManager.getCurrentTransactionName();
TransactionSynchronizationManager.setCurrentTransactionName(null);
boolean readOnly = TransactionSynchronizationManager.isCurrentTransactionReadOnly();
TransactionSynchronizationManager.setCurrentTransactionReadOnly(false);
Integer isolationLevel = TransactionSynchronizationManager.getCurrentTransactionIsolationLevel();
TransactionSynchronizationManager.setCurrentTransactionIsolationLevel(null);
boolean wasActive = TransactionSynchronizationManager.isActualTransactionActive();
TransactionSynchronizationManager.setActualTransactionActive(false);
// 最后集中封装为一个SuspendedResourcesHolder返回
return new SuspendedResourcesHolder(
suspendedResources, suspendedSynchronizations, name, readOnly, isolationLevel, wasActive);
}
catch (RuntimeException | Error ex) {
// 出现异常的话,恢复
doResumeSynchronization(suspendedSynchronizations);
throw ex;
}
}
else if (transaction != null) {
// 如果没有激活同步,那么也需要将连接挂起
Object suspendedResources = doSuspend(transaction);
return new SuspendedResourcesHolder(suspendedResources);
}
else {
// Neither transaction nor synchronization active.
return null;
}
}
在上面的代码我们要注意到一个操作,它会清空线程绑定的数据库连接,同时在后续操作中也不会再去获取一个数据库连接重新绑定到当前线程上,所以not_supported传播级别下每次执行SQL都可能使用的不是同一个数据库连接对象(依赖于业务中获取连接的方式)。这点大家要注意,跟后面的几种有很大的区别。
获取到需要挂起的资源后,调用了prepareTransactionStatus,这个方法我们之前分析过了,但是在这里传入的参数是不同的
// definition:非null,解析事务注解得来的
// transaction:null
// newTransaction:false
// newSynchronization:true
// suspendedResources:代表挂起的资源,包括连接以及同步
protected final DefaultTransactionStatus prepareTransactionStatus(
TransactionDefinition definition, @Nullable Object transaction, boolean newTransaction,
boolean newSynchronization, boolean debug, @Nullable Object suspendedResources) {
DefaultTransactionStatus status = newTransactionStatus(
definition, transaction, newTransaction, newSynchronization, debug, suspendedResources);
prepareSynchronization(status, definition);
return status;
}
最终会返回一个这样的事务状态对象,其中的transaction为null、newTransaction为false,这二者代表了不存在一个真正的事务。在后续的事务提交跟回滚时会根据事务状态对象中的这两个属性来判断是否需要真正执行回滚,如果不存在真正的事务,那么也就没有必要去回滚(当然,这只是针对内部的空事务而言,如果抛出的异常同时中断了外部事务,那么外部事务还是会回滚的)。除了这两个属性外,还有newSynchronization,因为在挂起同步时已经将之前的同步清空了,所以newSynchronization仍然为true,这个属性会影响后续的一些同步回调,只有为true的时候才会执行回调操作。最后就是suspendedResources,后续需要根据这个属性来恢复外部事务的状态。
当传播级别为requires_new时,会进入下面这段代码
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRES_NEW) {
// 第一步,也是挂起
SuspendedResourcesHolder suspendedResources = suspend(transaction);
try {
// 第二步,开启一个新事务,会绑定一个新的连接到当前线程上
return startTransaction(definition, transaction, debugEnabled, suspendedResources);
}
catch (RuntimeException | Error beginEx) {
// 出现异常,恢复外部事务状态
resumeAfterBeginException(transaction, suspendedResources, beginEx);
throw beginEx;
}
}
很简单吧,挂起事务,然后新开一个事务,并且新事务的连接跟外围事务的不一样。也就是说这两个事务互不影响。它也会返回一个事务状态对象,但是不同的是,transaction不为null、newTransaction为true。也就是说它有自己的提交跟回滚机制,也不难理解,毕竟是两个不同的数据库连接嘛~
当传播级别为nested进入下面这段代码
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NESTED) {
if (useSavepointForNestedTransaction()) {
DefaultTransactionStatus status =
prepareTransactionStatus(definition, transaction, false, false, debugEnabled, null);
status.createAndHoldSavepoint();
return status;
}
else {
// JTA相关,不考虑
return startTransaction(definition, transaction, debugEnabled, null);
}
}
前面其实已经介绍过了,也很简单。还是把重点放在返回的事务状态对象中的那几个关键属性上,transaction不为null,但是newTransaction为false,也就是说它也不是一个新事务,另外需要注意的是,它没有挂起任何事务相关的资源,仅仅是创建了一个保存点而已。这个事务在回滚时,只会回滚到指定的保存点。同时因为它跟外围事务共用一个连接,所以它会跟随外围事务的提交而提交,回滚而回滚。
剩下的supports、required、mandatory这几种传播级别都会进入下面这段代码
// 省略了校验相关代码,前面已经介绍过了,默认是关闭校验的
boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
return prepareTransactionStatus(definition, transaction, false, newSynchronization, debugEnabled, null);
我们会发现相比较于nested只是少了一个创建保存点的动作。最终返回的事务状态对象中的属性,transaction不为null,但是newTransaction为false,也就是说它也不是一个新事务。同时因为没有挂起外围事务的同步,所以它也不是一个新的同步(newSynchronization为false)。
对于每个隔离级别下返回的事务状态对象中的属性希望大家有一定了解,因为后续的回滚、提交等操作都依赖于这个事务状态对象。
到目前为止,我们就介绍完了事务的创建,紧接着就是真正的执行业务代码了,要保证业务代码能被事务管理,最重要的一点是保证在业务代码中执行SQL时仍然是使用我们在开启事务时绑定到线程上的数据库连接。那么是如何保证的呢?我们分为两种情况讨论
- 使用
JdbcTemplate访问数据库 - 使用
Mybatis访问数据库
对于第二种,可能需要你对Mybatis稍微有些了解
3、执行业务代码
JdbcTemplate
我们要讨论的只是
JdbcTemplate是如何获取到之前绑定在线程上的连接这个问题,不要想的太复杂
在事务专题的第一篇我就对JdbcTemplate做了一个简单的源码分析,它底层获取数据库连接实际上就是调用了DataSourceUtils#doGetConnection方法,代码如下:

关键代码我已经标出来了,实际上获取连接时也是从线程上下文中获取
Mybatis
Mybatis相对来说比较复杂,大家目前做为了解即可。当Spring整合Mybatis时,事务是交由Spring来管理的,那么Spring是如何接管Mybatis的事务的呢?核心代码位于SqlSessionFactoryBean#buildSqlSessionFactory方法中。其中有这么一段代码

在这里替换掉了Mybatis的事务工厂(Mybatis依赖事务工厂创建的事务对象来获取连接),使用了Spring自己实现的一个事务工厂SpringManagedTransactionFactory。通过它可以获取一个事务对象SpringManagedTransaction。我们会发现这个事务对象在获取连接时调用的也是DataSourceUtils的方法
private void openConnection() throws SQLException {
this.connection = DataSourceUtils.getConnection(this.dataSource);
this.autoCommit = this.connection.getAutoCommit();
this.isConnectionTransactional = DataSourceUtils.isConnectionTransactional(this.connection, this.dataSource);
}
所以它也能保证使用的是开启事务时绑定在线程上的连接,从而保证事务的正确性。
4、执行出现异常
出现异常时其实分为两种情况,并不是一定会回滚
对应代码如下:
protected void completeTransactionAfterThrowing(@Nullable TransactionInfo txInfo, Throwable ex) {
if (txInfo != null && txInfo.getTransactionStatus() != null) {
// transactionAttribute是从@Transactional注解中解析得来的
if (txInfo.transactionAttribute != null && txInfo.transactionAttribute.rollbackOn(ex)) {
try {
// 回滚
txInfo.getTransactionManager().rollback(txInfo.getTransactionStatus());
}
// 省略异常处理
}
else {
try {
// 即使出现异常仍然提交事务
txInfo.getTransactionManager().commit(txInfo.getTransactionStatus());
}
// 省略异常处理
}
}
}
可以看到,只有在满足txInfo.transactionAttribute.rollbackOn(ex)这个条件时才会真正执行回滚,否则即使出现了异常也会先提交事务。这个条件取决于@Transactiona注解中的rollbackFor属性是如何配置的,如果不进行配置的话,默认只会对RuntimeException或者Error进行回滚。
在进行回滚时会调用事务管理器的rollback方法,对应代码如下:
public final void rollback(TransactionStatus status) throws TransactionException {
// 事务状态为已完成的时候调用回滚会抛出异常
if (status.isCompleted()) {
throw new IllegalTransactionStateException(
"Transaction is already completed - do not call commit or rollback more than once per transaction");
}
DefaultTransactionStatus defStatus = (DefaultTransactionStatus) status;
// 这里真正处理回滚
processRollback(defStatus, false);
}
private void processRollback(DefaultTransactionStatus status, boolean unexpected) {
try {
// 传入时写死的为false
boolean unexpectedRollback = unexpected;
try {
// 触发之前注册的同步回调
triggerBeforeCompletion(status);
// 存在保存点,根据我们之前的分析,说明这是一个嵌套调用的事务
// 并且内部事务的传播级别为nested
if (status.hasSavepoint()) {
// 这里会回滚到定义的保存点
status.rollbackToHeldSavepoint();
}
// 根据我们之前的分析有两种情况会满足下面这个判断
// 1.直接调用,传播级别为nested、required、requires_new
// 2.嵌套调用,并且内部事务的传播级别为requires_new
else if (status.isNewTransaction()) {
// 直接获取当前线程上绑定的数据库连接并调用其rollback方法
doRollback(status);
}
else {
// 到这里说明存在事务,但是不是一个新事务并且没有保存点
// 也就是嵌套调用并且内部事务的传播级别为supports、required、mandatory
if (status.hasTransaction()) {
// status.isLocalRollbackOnly,代表事务的结果只能为回滚
// 默认是false的,在整个流程中没有看到修改这个属性
// isGlobalRollbackOnParticipationFailure
// 这个属性的含义是在加入的事务失败时是否回滚整个事务,默认为true
if (status.isLocalRollbackOnly() || isGlobalRollbackOnParticipationFailure()) {
// 从这里可以看出,但内部的事务发生异常时会将整个大事务标记成回滚
doSetRollbackOnly(status);
}
else {
// 进入这个判断说明修改了全局配置isGlobalRollbackOnParticipationFailure
// 内部事务异常并不影响外部事务
}
}
else {
// 不存在事务,回滚不做任何操作
logger.debug("Should roll back transaction but cannot - no transaction available");
}
// isFailEarlyOnGlobalRollbackOnly这个参数默认为false
// unexpectedRollback的值一开始就被赋值成了false
if (!isFailEarlyOnGlobalRollbackOnly()) {
unexpectedRollback = false;
}
}
}
catch (RuntimeException | Error ex) {
triggerAfterCompletion(status, TransactionSynchronization.STATUS_UNKNOWN);
throw ex;
}
// 触发同步回调
triggerAfterCompletion(status, TransactionSynchronization.STATUS_ROLLED_BACK);
// unexpectedRollback是false
// 这个值如果为true,说明
if (unexpectedRollback) {
throw new UnexpectedRollbackException(
"Transaction rolled back because it has been marked as rollback-only");
}
}
finally {
// 在事务完成后需要执行一些清理动作
cleanupAfterCompletion(status);
}
}
上面的代码结合注释看起来应该都非常简单,我们最后关注一下cleanupAfterCompletion这个方法,对应代码如下
private void cleanupAfterCompletion(DefaultTransactionStatus status) {
// 将事务状态修改为已完成
status.setCompleted();
// 是否是新的同步
// 清理掉线程绑定的所有同步信息
// 直接调用时,在任意传播级别下这个条件都是满足的
// 嵌套调用时,只有传播级别为not_supported、requires_new才会满足
if (status.isNewSynchronization()) {
TransactionSynchronizationManager.clear();
}
// 是否是一个新的事务
// 直接调用下,required、requires_new、nested都是新开的一个事务
// 嵌套调用下,只有requires_new会新起一个事务
if (status.isNewTransaction()) {
// 真正执行清理
doCleanupAfterCompletion(status.getTransaction());
}
// 如果存在挂起的资源,将挂起的资源恢复
// 恢复的操作跟挂起的操作正好相反
// 就是将之前从线程解绑的资源(数据库连接等)已经同步回调重新绑定到线程上
if (status.getSuspendedResources() != null) {
if (status.isDebug()) {
logger.debug("Resuming suspended transaction after completion of inner transaction");
}
Object transaction = (status.hasTransaction() ? status.getTransaction() : null);
resume(transaction, (SuspendedResourcesHolder) status.getSuspendedResources());
}
}
再来看看doCleanupAfterCompletion到底做了什么,源码如下:
protected void doCleanupAfterCompletion(Object transaction) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) transaction;
// 先判断是否是一个新连接
// 直接调用,如果真正开启了一个事务必定是个连接
// 但是嵌套调用时,只有requires_new会新起一个连接,其余的都是复用外部事务的连接
// 这种情况下不能将连接从线程上下文中清除,因为外部事务还需要使用
if (txObject.isNewConnectionHolder()) {
TransactionSynchronizationManager.unbindResource(obtainDataSource());
}
// 恢复连接的状态
// 1.重新将连接设置为自动提交
// 2.恢复隔离级别
// 3.将read only重新设置为false
Connection con = txObject.getConnectionHolder().getConnection();
try {
if (txObject.isMustRestoreAutoCommit()) {
con.setAutoCommit(true);
}
DataSourceUtils.resetConnectionAfterTransaction(
con, txObject.getPreviousIsolationLevel(), txObject.isReadOnly());
}
catch (Throwable ex) {
logger.debug("Could not reset JDBC Connection after transaction", ex);
}
// 最后,因为事务已经完成了所以归还连接
if (txObject.isNewConnectionHolder()) {
DataSourceUtils.releaseConnection(con, this.dataSource);
}
// 将事务对象中绑定的连接相关信息也清空掉
txObject.getConnectionHolder().clear();
}
5、提交事务
提交事务有两种情况
- 正常执行完成,提交事务
- 出现异常,但是不满足回滚条件,仍然提交事务
但是不管哪种清空最终都会调用
AbstractPlatformTransactionManager#commit方法,所以我们就直接分析这个方法
代码如下:
public final void commit(TransactionStatus status) throws TransactionException {
// 跟处理回滚时是一样的,都会先校验事务的状态
// 如果事务已经完成了,那么直接抛出异常
if (status.isCompleted()) {
throw new IllegalTransactionStateException(
"Transaction is already completed - do not call commit or rollback more than once per transaction");
}
// 这里会检查事务的状态是否被设置成了只能回滚
// 这里检查的是事务状态对象中的rollbackOnly属性
DefaultTransactionStatus defStatus = (DefaultTransactionStatus) status;
if (defStatus.isLocalRollbackOnly()) {
processRollback(defStatus, false);
return;
}
// 这里会检查事务对象本身是否被设置成了rollbackOnly
// 之前我们在分析回滚的代码时知道,当内部的事务发生回滚时(supports、required)
// 默认情况下会将整个事务对象标记为回滚,实际上在外部事务提交时就会进入这个判断
// shouldCommitOnGlobalRollbackOnly:在全局被标记成回滚时是否还要提交,默认为false
if (!shouldCommitOnGlobalRollbackOnly() && defStatus.isGlobalRollbackOnly()) {
processRollback(defStatus, true);
return;
}
// 真正处理提交
processCommit(defStatus);
}
可以看到,即使进入了提交事务的逻辑还是可能回滚。
- 事务状态对象(TransactionStatus)中的状态被设置成了
rollbackOnly - 事务对象本身(DataSourceTransactionObject)被设置成了
rollbackOnly
二者在回滚时都是调用了processRollback方法,但是稍有区别,通过事务状态对象造成的回滚最终在回滚后并不会抛出异常,但是事务对象本身会抛出异常给调用者。
真正处理提交的逻辑在processCommit方法中,代码如下:
private void processCommit(DefaultTransactionStatus status) throws TransactionException {
try {
boolean beforeCompletionInvoked = false;
try {
boolean unexpectedRollback = false;
// 留给子类复写的一个方法,没有做实质性的事情
prepareForCommit(status);
// 触发同步回调
triggerBeforeCommit(status);
triggerBeforeCompletion(status);
beforeCompletionInvoked = true;
// 存在保存点,将事务中的保存点清理掉
if (status.hasSavepoint()) {
if (status.isDebug()) {
logger.debug("Releasing transaction savepoint");
}
unexpectedRollback = status.isGlobalRollbackOnly();
status.releaseHeldSavepoint();
}
// 直接调用,传播级别为required、nested、requires_new
// 嵌套调用,且传播级别为requires_new
else if (status.isNewTransaction()) {
if (status.isDebug()) {
logger.debug("Initiating transaction commit");
}
// 虽然前面已经检查过rollbackOnly了,在shouldCommitOnGlobalRollbackOnly为true时
// 仍然需要提交事务,将unexpectedRollback设置为true,意味着提交事务后仍要抛出异常
unexpectedRollback = status.isGlobalRollbackOnly();
// 提交的逻辑很简单,调用了connection的commit方法
doCommit(status);
}
else if (isFailEarlyOnGlobalRollbackOnly()) {
unexpectedRollback = status.isGlobalRollbackOnly();
}
if (unexpectedRollback) {
throw new UnexpectedRollbackException(
"Transaction silently rolled back because it has been marked as rollback-only");
}
}
catch (UnexpectedRollbackException ex) {
// unexpectedRollback为true时,进入这个catch块
// 触发同步回调
triggerAfterCompletion(status, TransactionSynchronization.STATUS_ROLLED_BACK);
throw ex;
}
catch (TransactionException ex) {
// connection的doCommit方法抛出SqlException时进入这里
if (isRollbackOnCommitFailure()) {
// 在doCommit方法失败后是否进行回滚,默认为false
doRollbackOnCommitException(status, ex);
}
else {
// 触发同步回调
triggerAfterCompletion(status, TransactionSynchronization.STATUS_UNKNOWN);
}
throw ex;
}
catch (RuntimeException | Error ex) {
// 剩余其它异常进入这个catch块
if (!beforeCompletionInvoked) {
triggerBeforeCompletion(status);
}
doRollbackOnCommitException(status, ex);
throw ex;
}
// 触发同步回调
try {
triggerAfterCommit(status);
}
finally {
triggerAfterCompletion(status, TransactionSynchronization.STATUS_COMMITTED);
}
}
finally {
// 跟回滚时一样,做一些清理动作
cleanupAfterCompletion(status);
}
}
整个逻辑还是比较简单的,最核心的步骤就是调用了数据库连接对象(Connection)的commit方法。
总结
本文主要分析了Spring中事务的实现机制,从事务实现的入口---->EnableTransactionManagement注解,到事务实现的核心TransactionInterceptor都做了详细的分析。其中最复杂的一块在于事务的创建,也就是createTransactionIfNecessary,既要考虑直接调用的情况,也要考虑嵌套调用的情况,并且还需要针对不同的传播级别做不同的处理。对于整个事务管理,我们需要分清楚下面这几个对象的含义
- TransactionDefinition
- TransactionStatus
- DataSourceTransactionObject
- TransactionInfo
TransactionDefinition代表的是我们通过@Transactional注解指定的事务的属性,包括是否只读、超时、回滚等。
TransactionStatus代表的是事务的状态,这个状态分为很多方面,比如事务的运行状态(是否完成、是否被标记为rollbakOnly),事务的同步状态(这个事务是否开启了一个新的同步),还有事务是否设置了保存点。更准确的来说,TransactionStatus代表的是被@Transactional注解修饰的方法的状态,只要被@Transactional注解修饰了,在执行通知逻辑时就会生成一个TransactionStatus对象,即使这个方法没有真正的开启一个数据库事务
DataSourceTransactionObject代表的是一个数据库事务对象,实际上保存的就是一个数据库连接以及这个连接的状态。
TransactionInfo代表的是事务相关的所有信息,组合了事务管理器,事务状态,事务定义并持有一个旧的TransactionInfo引用,这个对象在事务管理的流程中其实没有实际的作用,主要的目的是为了让我们在事务的运行过程中获取到事务的相关信息,我们可以直接调用TransactionAspectSupport的currentTransactionInfo方法获取到当前线程绑定的TransactionInfo对象。
另外,看完本文希望大家对于事务的传播机制能有更深一点的认知,而不是停留在概念上,要讲清楚事务的传播机制我们先做以下定。
-
凡是在执行代理方法的过程中从数据源重新获取了连接并调用了其
setAtuoCommit(false)方法,而且还将这个连接绑定到了线程上下文中,我们就认为它新建了一个事务。注意了,有三个要素-
连接是从数据源中获取到的
-
调用了连接的
setAtuoCommit(false)方法 -
这个连接被绑定到了线程上下文中
-
-
凡是在执行代理方法的过程中,挂起了外部事务,并且没有新建事务,那么我们认为这个这个方法是以非事务的方式运行的。
-
凡是在执行代理方法的过程中,没有挂起外部事务,但是也没有新建事务,那么我们认为这个方法加入了外部的事务
挂起事务的表现在于清空了线程上下文中绑定的连接!
同时我们分为两种情况讨论来分析传播机制
- 直接调用
- 间接调用
直接调用不存在加入外部事务这么一说,要么就是新建事务,要么就是以非事务的方式运行,当然,也可能抛出异常。
| 传播级别 | 运行方式 |
|---|---|
| requires_new | 新建事务 |
| nested | 新建事务 |
| required | 新建事务 |
| supports | 非事务的方式运行 |
| not_supported | 非事务的方式运行 |
| never | 非事务的方式运行 |
| mandatory | 抛出异常 |
间接调用时我们要分两种情况讨论
- 外部的方法新建了事务
- 外部的方法本身就是非事务的方式运行的
在外部方法新建事务的情况下时(说明外部事务的传播级别为requires_new,nested或者required),当前方法的运行方式如下表所示
| 传播级别 | 运行方式 |
|---|---|
| requires_new | 新建事务 |
| nested | |
| required | 直接加入到外部事务 |
| supports | 直接加入到外部事务 |
| not_supported | 挂起外部事务,以非事务的方式运行 |
| never | 抛出异常 |
| mandatory | 直接加入到外部事务 |
当外部方法没有新建事务时,其实它的运行方式跟直接调用是一样的,这里就不赘述了。
本文到这里就结束了,文章很长,希望你可以耐心看完哈~
码到手酸,求个三连啊!啊!啊!
如果本文对你由帮助的话,记得点个赞吧!也欢迎关注我的公众号,微信搜索:程序员DMZ,或者扫描下方二维码,跟着我一起认认真真学Java,踏踏实实做一个coder。

我叫DMZ,一个在学习路上匍匐前行的小菜鸟!