听小董谝存储 十
目录
万年不变
背景
需求整理
第一版 完全内存
第二版 有序下刷
第三版 分层下刷
关于get与list
万年不变
我爱glt
另外本文实际上就是LevelDB的解析,大家可以看完我的博客,再找一些更深入的文章读一下。
背景
老鸟:咱们之前设计的存储系统,最近有了点新需求。
小菜:你说。
老鸟:之前省里王警官用咱们的存储系统,存储省里所有人的身份证信息,key是身份证,value是她们的具体信息,之前get、set、del用的很溜。具体的表格如下:
| Key(身份证号) |
Value |
| 610402196305211123 |
张三 |
| 610402197505212334 |
李四 |
| 610402194405214453 |
王二 |
| 610403196305213233 |
。。。。 |
| 610402196305213233 |
。。。。 |
| 610407196305219975 |
。。。。 |
| 610410196305212245 |
。。。。 |
但是最近中央检查,经常需要获取某个片区里所有同志信息,这些人都是一个片区的所以她们的身份证前缀都是一样的。现在这样就很操蛋了,只知道一堆前缀,怎么才能找到符合这个前缀的所以同志的信息呢。
小菜:明白需求了,一方面要知道相同前缀下的key都有哪些,其二还得把这些key的value都拿到。我想想,新的系统我还不知道怎么设计,但是之前设计的老系统肯定不行了。就算我能知道相同前缀下有1000个人,但是这1000个人是基于hash打散的,要全部获得数据,就得进行一千次get操作才能拿到数据。
老鸟:那能不能把所有的key按照字典顺序存储,然后一次读盘就能取到很多人的数据。
需求整理
老鸟:简单的说,我们需要设计一个新的存储系统,它要支持get,set,del操作。还有一个新加的list操作,语义就是根据相同的key前缀来获取键值对。
因为有list操作,一次读取多个key,那么建议把key按顺序存放,否则多次读盘性能太差。
同样的,系统要能扩展,之前举的例子只是要说明问题,全世界的人口才70亿。如果用咱们的系统存储淘宝系统上所有的图片信息,那它可能就得支持700亿的存储量甚至7000亿的。
第一版 完全内存
老鸟:来吧,设计吧。给你减轻点难度,之前存储系统涉及的接入层和元数据管理层都不用管了,你直接设计存储引擎层吧,就是之前咱们基于hash设计的particle。
小菜:好吧,第一版如下:

图一 所有数据都在内存
用户随机写入的数据,直接写到内存的一个个block里,每个block内部为了简单,就直接按照时间顺序存储。一个block存储满了,就启用下一个block。如上图,就是先写block1,然后写满了,然后是block2。。。。。。最后是block4。
老鸟:也难为你了。好吧,就按照你的思路,说说读写删流程吧。
小菜:写的时候直接写到内存就搞定。删除就写入key和一个特殊的标识。读的时候按照写入的顺序反向读,先遍历block4,找到就返回,如果没有找到就去遍历block3,如果一直遍历到block1都没有找到,那就返回没有找到。
老鸟:确实,第一版能做成这样也不错了,整理一下,缺点如下:
1 仍然没有看到list接口的思路
2 内存不够,会丢数据。
老鸟:如图二,我画出了每个block里面的存储的key(value就暂时省略)。Block1里面先后写入了abcd,fed,abcc,hsf这4个key。然后是block2,最后block4里面有pp,done,oj,abcc,hs这5个key。现在的核心问题是,怎么把这4个block里面的16个kv对变成有序的。

图二 显示每个block里面的数据
第二版 有序下刷
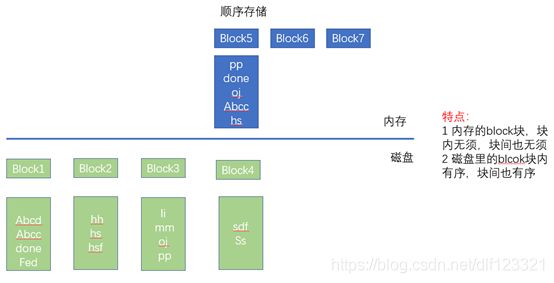
图三 内存的block被下刷到磁盘里
小菜:不知道怎么无序变有序。
老鸟:看图说话,就图三,你有什么想法。
小菜:当系统发现内存不够用的时候,就把内存里面的block进行进行整理下刷到磁盘里。具体的整理措施就是先把内存里的几个block里面的数据按照写入的时序反向都读出来,然后排序,再顺序写入磁盘,排列成磁盘里面的一个个block。(当然每个block都知道自己存储的多个key里面最小的前缀和最大的前缀,例如block3最小的key就是li最大的key就是pp)
老鸟:嗯说的基本在理。
小菜:但是我更糊涂了。这种下刷只能是一次性的,要求磁盘里没有数据。就像图三里,如果新的block5要下刷怎么办,它里面最小的是Abcc,最大的pp,那等于磁盘里面的block1,block2,block3都要动。而且,怎么动,我也没有想清楚。
老鸟:看图,如下图四,咱们把内存里要下刷的block5,和磁盘里与block有交叠的block1,block2,block3都整理一下。内存里的block5本身是无序的,那就要排好序,因为磁盘里的数据都是已经排好序的,磁盘里的所谓整理就是按照块间顺序全部读出来即可。

图四:整理磁盘和内存里面的block
小菜:然后呢?
老鸟:看图五,对照图四。说说你的看法。
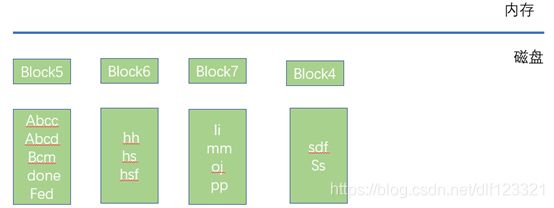
图五 整理后的磁盘数据
如图四,把内存里面一个block的数据读出来排序,然后和磁盘里面的相关数据进行归并排序,再写到磁盘里。如图四,磁盘里和内存里都有一个abcc,这个时候,就以内存里的abcc为主,磁盘里原来的block里面的abcc就直接抛弃。同样的假如内存里的abcc标识的是已经删除,那么同样的内存里的abcc略过,磁盘里面的abcc也略过。
如果磁盘里已经有1万个block里,我内存里的就新写了一个block,里面就两个key,一个aa,一个zz,那咋办?把之前下刷的1万个block里面的内容都读出来?
第三版 分层下刷
老鸟:刚才你说了,如果下刷某个block,发现下面关联了一万个block,那就得整理10001个block。这么整理,肯定是不行的。
又想起了那句话:
Any problem in computer science can be solved by anther layer of indirection.
计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决
之前只有两层,那么多加一层行不行?

图六 多层排序存储
如图六,来,小菜,说说你的看法。
小菜:写进程直接把数据写到Level0的block里。当Level0快写满的时候,就把Level0的一个block里面的数据读出来,排序,找到第一个key和最后一个key,然后再Level1里面找到和之前的block相交叠的block,再把这些block的数据顺序读出,然后再归并排序写入Level1(可能需要很多个新的block来存储数据)。因为有多层,每一层能容纳的block的数量大概是上一层容纳数量的10倍。这样一来单个block里面的数据和下一层重叠的block数量也就是10这个数量级左右,很少有概率出现合并一个blcok,需要读取10000个block的情况了。
另外就如上图六, Level1展示了4个block。他们只是逻辑上相邻都在Level1这一层,但是实际上,他们存储的内存块可能相隔十万八千里。
那么到底怎么读写呢?
关于get与list
老鸟:说说这个引擎关于get的流程吧。
小菜:那简单,就先遍历Level0里面的block,遍历的顺序反向于写入的顺序。如果找到了那就OK,找不到,那就去Level1里面找。因为level1里面的数据是块间有序,块内也有序,直接在那个key肯能存在的block里找,如果那个block里面没有就说明这一层肯定不存在这个数据。然后去Level2找,如果还找不到,就去Level3,level4。如果找到最后一层还没有找到,说明真的不存在这个数据(压根没写入,或者已经被删除了)。但是list,怎么操作我还没想明白。
老鸟:这么把,Level0的情况比较复杂,咱们先假定所有的数据都在Level1及以下,你说说吧怎么进行list。
小菜:。。。。
老鸟:多路归并排序懂不懂?
小菜:懂。
老鸟:可不可能同一个key既出现在Level2也出现在Level1?
小菜:这很正常。此时Level1的数据相比较来说更新一些,读取数据(包括get与list)的时候应该以Level1为准。
老鸟:那就是带有优先级的多路归并排序。
小菜:不懂
老鸟:举一隅不以三隅反,则不复也。
小菜:脸上笑眯眯~那Level0的数据咋办,块内也无序,没办法归并排序呀。
老鸟:先说块内无序,能不能变成块内有序?
小菜:咋变?每次查询的时候都排一次序么?
老鸟:笨呐。跳表。
小菜:有了跳表,块内有序,但是块间无序。这一层的数据怎么list?
老鸟:竖起来!
小菜:竖起来?
老鸟:小菜,看图七,看懂了么?
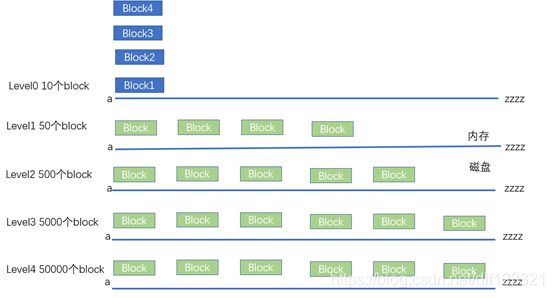
图七 整体排序
小菜:block4的数据新于block3,block2的数据新于block1。Level2的数据新于Level3。如果就以图七的逻辑图来说,list一个数据,其实就是带有优先级的八路归并排序。
老鸟:其实咱们的存储系统还有数据搬迁,分裂合并的问题,还有数据恢复的问题,下节课再说吧。