什么?!NEON还要优化?
作者:十曰立
链接:https://www.jianshu.com/p/16d60ac56249
來源:简书
官网介绍:
- NEON宏观介绍
- NEON Programmer’s Guide Version: 1.0
直观认识
NEON整体描述
Arm NEON technology is an advanced SIMD (single instruction multiple data) architecture extension for the Arm Cortex-A series and Cortex-R52 processors.
NEON technology was introduced to the Armv7-A and Armv7-R profiles. It is also now an extension to the Armv8-A and Armv8-R profiles.
NEON technology is intended to improve the multimedia user experience by accelerating audio and video encoding/decoding, user interface, 2D/3D graphics or gaming. NEON can also accelerate signal processing algorithms and functions to speed up applications such as audio and video processing, voice and facial recognition, computer vision and deep learning.
其他具体的细节,在官网还有很多描述,自己去看吧!
持续优化
初识
NEON的初步认识
NEON是SIMD架构下的一个加速部分,其实本来是给多媒体做的,因为多媒体计算量大,而且计算的方式比较单一,因此那伙设计cpu的家伙可能就想,我能不能针对真快做个并行部分?
于是这玩意就出来了,嗯!就是这么来的(我瞎掰的)。
详细的教程如下系列:
安卓开发看这个入手:ARM NEON programming quick reference
Coding for NEON - Part 1: Load and Stores
Coding for NEON - Part 2: Dealing With Leftovers
Coding for NEON - Part 3: Matrix Multiplication
Coding for NEON - Part 4: Shifting Left and Right
Coding for NEON - Part 5: Rearranging Vectors
实例
ARM NEON技术在车位识别算法中的应用
这里面讲到了两个核心点:
- 循环的时候,可以把循环展开,从而稀释掉循环判断在占用时间中的比例,这个优化的是CPU的计算时间;
- 在数据运算的时候,比如乘法,我们可以把刚刚第一步展开的4个32bit一次性丢进Q寄存器,然后一次就计算完了,理论上是四倍计算加速啊!
总结:虽然讲到了加速,而且还讲了点编译器的相关优化,但是都还不够geek,不够彻底,不够爽!
你看看下面这一篇,就知道什么叫做严谨,什么叫做geek了!
从一个复数点积算法看NEON的汇编优化
这里面讲到了指令重排、微架构、流水线等很深的东西,不懂,先知道设计原则就好。
其中尤其关注的点是:指令流水排布
- 那指令流水排布跟啥有关?即主要需要注意不要引起CPU的Hazard。
- 介绍Hazard的连接在这:链接。
Hazard
简短说下:在CPU微架构里,当下一条指令无法在接下来的时钟周期内被执行,由此导致的指令流水线问题就叫做Hazard。
栗子?:你看哈,我现在是往Q0里面写数据,然后进入了流水线(假设是分取、算、存等步骤),下一条指令马上就是从Q0里面取出数据进行运算,那么很有可能我取的数据还是Q0原来的数据啊!因为由于流水线的原因,很有可能上面的Q0还没写回去,我就把数据给读出来了!
看下面的图(可治陈年老颈椎):

你看上面一条指令假设需要花很多个指令周期(NEON指令确实如此),那么就被推入了流水线,并分割为好多的小步骤,其中最后一个步骤就是把数据写回Q0,让当前这条指令的下一句就是先取Q0的值,然后做运算啥的,你从图上看,是不是很有可能上一条指令的Q0还没写进去,我下面的Q0就读出来啦!因此在微架构里面叫这玩意做:Hazard。
当然咯!这种情况肯定是不允许出现的,具体怎么解我不知道,我知道的是,肯定得等Q0写完才能读,因此势必流水线就会被破坏,势必就有资源会被作为牺牲品,因此这就是为什么不提倡上述这种操作方式,再下面的NEON优化部分,我会有更专业的操作来验证。
Ne10 Library Getting Started
讲了Ne10这个库的结构,并教你怎么编译啊、使用啊啥的,如文章名所示,就是一个入门文章。
Using Ne10 on Android and iOS
这个就是实例了,讲具体在安卓啊,苹果啊环境下是如何使用的。
什么!?你要还要优化NEON?
ARM NEON optimization
Introduction
如其名,就是Neon优化的,讲了一些实践技巧。hin重要啊!
Skill1:Remove data dependencies
在ARMv7-A平台(==注意,其他平台不一定是这个效果了,需要去精调的哈==)下,NEON指令通常比ARM标准指令集需要更多的指令周期。
(原文:On ARMv7-A platform, NEON instructions usually take more cycles than ARM instructions. To reduce instruction latency, it’s better to avoid using the destination register of current instruction as the source register of next instruction.)
因此,为了减少指令延时时间,避免使用当前指令的目地寄存器作为下一条指令的源寄存器。
这里我大胆猜测下:为什么当前指令的目的寄存器作为下一条指令的源寄存器会增加延时?我觉得是由于流水线的问题,你想啊,NEON指令要的周期数比ARM指令要多,也就是是说在指令流水线里面呆的时间越长,因此为了保证数据不会出现Hazard(见上面的wiki解释),于是我刚进流水线我就得把流水线给清了,这无疑是极大浪费资源跟效率的。本人拙见,请点评。
C语言实现版本:
就是两块内存中的数据求差分值,然后平方和,就是求均方差的函数,在求出差分(写入作为目的寄存器)后马上又要使用差分值平方(平方作为源寄存器)。
loat SumSquareError_C(const float* src_a, const float* src_b, int count)
{
float sse = 0u;
int i;
for (i = 0; i < count; ++i) {
float diff = src_a[i] - src_b[i];
sse += (float)(diff * diff);
}
return sse;
}
汇编实现版本1:
这里几乎是常规的写法,你看注释那里,可以看到q0是vsub的目的寄存器,马上又是下面vmla的源寄存器了,所以这里是会打断流水线的(粗略解释见上面Hazard部分)。
float SumSquareError_NEON1(const float* src_a, const float* src_b, int count)
{
float sse;
asm volatile (
// Clear q8, q9, q10, q11
"veor q8, q8, q8 \n"
"veor q9, q9, q9 \n"
"veor q10, q10, q10 \n"
"veor q11, q11, q11 \n"
"1: \n"
"vld1.32 {q0, q1}, [%[src_a]]! \n"
"vld1.32 {q2, q3}, [%[src_a]]! \n"
"vld1.32 {q12, q13}, [%[src_b]]! \n"
"vld1.32 {q14, q15}, [%[src_b]]! \n"
"subs %[count], %[count], #16 \n"
// q0, q1, q2, q3 are the destination of vsub.
// they are also the source of vmla.
"vsub.f32 q0, q0, q12 \n"
"vmla.f32 q8, q0, q0 \n"
"vsub.f32 q1, q1, q13 \n"
"vmla.f32 q9, q1, q1 \n"
"vsub.f32 q2, q2, q14 \n"
"vmla.f32 q10, q2, q2 \n"
"vsub.f32 q3, q3, q15 \n"
"vmla.f32 q11, q3, q3 \n"
"bgt 1b \n"
"vadd.f32 q8, q8, q9 \n"
"vadd.f32 q10, q10, q11 \n"
"vadd.f32 q11, q8, q10 \n"
"vpadd.f32 d2, d22, d23 \n"
"vpadd.f32 d0, d2, d2 \n"
"vmov.32 %3, d0[0] \n"
: "+r"(src_a),
"+r"(src_b),
"+r"(count),
"=r"(sse)
:
: "memory", "cc", "q0", "q1", "q2", "q3", "q8", "q9", "q10", "q11",
"q12", "q13","q14", "q15");
return sse;
}
汇编实现版本2:
你看这个操作就合理多了,把减法操作跟平方操作不连起来,在中间穿插其他的操作,从而保证Q0在被取的时候,流水线肯定把Q0的值写进去了,也就说留出足够的时间出来了。
float SumSquareError_NEON2(const float* src_a, const float* src_b, int count)
{
float sse;
asm volatile (
// Clear q8, q9, q10, q11
"veor q8, q8, q8 \n"
"veor q9, q9, q9 \n"
"veor q10, q10, q10 \n"
"veor q11, q11, q11 \n"
"1: \n"
"vld1.32 {q0, q1}, [%[src_a]]! \n"
"vld1.32 {q2, q3}, [%[src_a]]! \n"
"vld1.32 {q12, q13}, [%[src_b]]! \n"
"vld1.32 {q14, q15}, [%[src_b]]! \n"
"subs %[count], %[count], #16 \n"
"vsub.f32 q0, q0, q12 \n"
"vsub.f32 q1, q1, q13 \n"
"vsub.f32 q2, q2, q14 \n"
"vsub.f32 q3, q3, q15
\n"
"vmla.f32 q8, q0, q0 \n"
"vmla.f32 q9, q1, q1 \n"
"vmla.f32 q10, q2, q2 \n"
"vmla.f32 q11, q3, q3 \n"
"bgt 1b \n"
"vadd.f32 q8, q8, q9 \n"
"vadd.f32 q10, q10, q11 \n"
"vadd.f32 q11, q8, q10 \n"
"vpadd.f32 d2, d22, d23 \n"
"vpadd.f32 d0, d2, d2 \n"
"vmov.32 %3, d0[0] \n"
: "+r"(src_a),
"+r"(src_b),
"+r"(count),
"=r"(sse)
:
: "memory", "cc", "q0", "q1", "q2", "q3", "q8", "q9", "q10", "q11",
"q12", "q13","q14", "q15");
return sse;
}
结论: 在当前的ARMv7平台下测试效果是汇编版本2比版本1快了约30%,此外,intrinsics方式写的NEON指令可以通过编译器来进行精调。
Note: this test runs on Cortex-A9. The result may be different on other platforms.
Skill2:Reduce branches
在NEON的指令集里面是没有分支跳转指令的,如果你硬是要跳转的话那就得用ARM指令集的了;
在ARM处理器中分支预测技术被广泛应用,但是一旦分支预测失败了,那花费的代价尤其高啊!(为啥呢?我认为是....我怎么知道啊!我又不是设计ARM内核的,但是我们可以知道的是:你买股票预测错了,你肯定是会有所损失的,搞不好还会上天台的...)
因此避免使用跳转指令是个明智的选择,但是实际过程中总的要分支的吧,怎么整?唯有等效替换,比如用逻辑操作代替分支选择。
talk less, show me the code.(亮代码吧!兄嘚~)
C语言版本:
if( flag )
{
dst[x * 4] = a;
dst[x * 4 + 1] = a;
dst[x * 4 + 2] = a;
dst[x * 4 + 3] = a;
}
else
{
dst[x * 4] = b;
dst[x * 4 + 1] = b;
dst[x * 4 + 2] = b;
dst[x * 4 + 3] = b;
}
NEON版本:
//dst[x * 4] = (a&Eflag) | (b&~Eflag);
//dst[x * 4 + 1] = (a&Eflag) | (b&~Eflag);
//dst[x * 4 + 2] = (a&Eflag) | (b&~Eflag);
//dst[x * 4 + 3] = (a&Eflag) | (b&~Eflag);
VBSL qFlag, qA, qB
VBSL(按位选择):
- 如果目标的对应位为1,则该指令从第一个操作数中选择目标的每一位;
- 如果目标的对应位为 0,则从第二个操作数中选择目标的每一位。
ARM NEON 指令集提供以下指令来帮助用户实现上述的逻辑操作:
VCEQ, VCGE, VCGT, VCLE, VCLT……
VBIT, VBIF, VBSL……
小结:减少分支并不是仅仅对NEON有用,这是一个对所有代码(指令集)都有用的小trick啦~ 甚至连在c语言里面这都是一条很有效的准则:少用分支。
Skill3:Preload data-PLD
ARM处理器是加载/存储的系统(load/store system)。
除了加载/存储指令集,其他的操作都是对寄存器的,因此提高加载/存储的效率对优化应用具有很高的实际意义。
预加载指令允许处理器去通知内存系统,告诉他:hey!兄弟,我很有可能待会得来这个地址取个东西,先帮我准备好,ok?
假如数据被正确预加载至cache了,于是cache 的hit rate将会极大提高,因此性能就极大提高了!
但是,预取也不是百试百灵的,在新的处理器里面预取非常难用,而且一个预取的不好就会降低性能的。
PLD syntax:
PLD{cond} [Rn {, #offset}]
PLD{cond} [Rn, +/-Rm {, shift}]
PLD{cond} label
Where:
Cond - is an optional condition code.
Rn - is the register on which the memory address is based.
Offset - is an immediate offset. If offset is omitted, the address is the value in Rn.
Rm - contains an offset value and must not be PC (or SP, in Thumb state).
Shift - is an optional shift.
Label - is a PC-relative expression.
PLD操作的一些特征:
- 独立于加载/存储的的指令运行(Independent of load and store instruction execution);
- 当处理器在持续执行其他指令的时候,预加载是在后台运行的;
- 偏移量指定为实际情况(The offset is specified to real cases)。
Skill4:Misc
在ARM NEON编程里面,不同的指令序列能实现同样的操作;但是更少的指令并不总是意味着更好的性能(也就是说指令数量跟性能不是绝对的线性对应关系)。
那指令数量跟性能的关系是基于什么呢?
基于特定情况下的benchmark and profiling result(基准和分析结果),如下就是一些特定情况下的实践分析。
Floating-point VMLA/VMLS instruction
注意咯:这里的数据仅对Cortex-A9平台有效,对于其他的平台结果就需要重新评估啦!
通常,VMUL+VADD/VMUL+VSUB指令能够被VMLA/VMLS指令替换,因为指令数量更少了,更精简了。
但是,对比于浮点VMUL操作,浮点VMLA/VMLS操作有更长的指令delay,假如在这段delay空隙中没有其他的指令能够插入的话,使用浮点VMUL+VADD/VMUL+VSUB操作将会表现出更好的性能。
问题:如何会更好?我认为还是一个流水线的问题罢!
举个实例:Ne10库中的浮点FIR函数,代码片段如下所述:
Implementation 1: VMLA
这里在VMLA之间只有一个VEXT指令,而VMLA则需要9个指令周期的延时(according to the table of NEON floating-point instructions timing)
Implementation 1: VMLA
VEXT qTemp1,qInp,qTemp,#1
VMLA qAcc0,qInp,dCoeff_0[0]
VEXT qTemp2,qInp,qTemp,#2
VMLA qAcc0,qTemp1,dCoeff_0[1]
VEXT qTemp3,qInp,qTemp,#3
VMLA qAcc0,qTemp2,dCoeff_1[0]
VMLA qAcc0,qTemp3,dCoeff_1[1]
Implementation 2: VMUL+VADD
这里仍然还有qAcc0的数据依赖缺(就是说流水线里面的Hazard,见前文的分析),但是 VADD/VMUL只需要5个指令周期哈!
Implementation 2: VMUL+VADD
VEXT qTemp1,qInp,qTemp,#1
VMLA qAcc0,qInp,dCoeff_0[0] ]
VMUL qAcc1,qTemp1,dCoeff_0[1]
VEXT qTemp2,qInp,qTemp,#2
VMUL qAcc2,qTemp2,dCoeff_1[0]
VADD qAcc0, qAcc0, qAcc1
VEXT qTemp3,qInp,qTemp,#3
VMUL qAcc3,qTemp3,dCoeff_1[1]
VADD qAcc0, qAcc0, qAcc2
VADD qAcc0, qAcc0, qAcc3
小结:实测第二个版本有更好的性能。
上述仅是代码的一部分,想要详细的代码请看这:Github上Ne10库的源码
具体实现代码位置在:modules/dsp/NE10_fir.neon.s:line 195
下面是上面提到的,指令周期对照表:
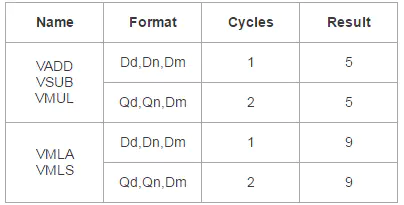
NEON floating-point instructions timing
总结:优化手段总结如下
- 尽可能地利用指令之间的延时空隙;
- 避免使用分支;
- 关注cache hit;
NEON assembly and intrinsics
NEON汇编方式跟intrinsics方式对比如下:
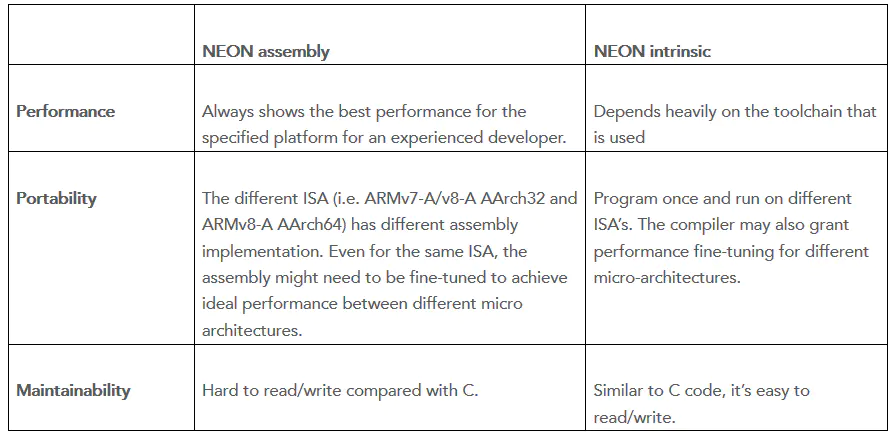
我们可以看到是分三个方面进行对比的:
性能:
- assembly: 对有经验的开发者来说,针对特定平台的汇编代码总是有最佳的性能表现,
- intrinsics: 然而intrinsics方式则严重依赖于使用的工具链;
可移植性:
- assembly: 不同的指令集架构(ISA: Instruction Set Architecture)有不同的汇编实现;甚至是在同样的指令集架构下,不同微架构的汇编代码都可能需要精调来实现理想的性能;
- intrinsics: 编程一次,即可适用于所有的指令集架构,编译器甚至会考虑到不同的微架构来进行性能精调;
操作性:
- assembly: 对比于C来说是很难读写的咯!
- intrinsics: 跟C语言类似,读写容易;
小结:但是现实情况是远比这复杂的,尤其当碰到ARMv7-A/v8-A 跨平台问题时,因此接下来我们针对这给出些栗子来进行分析。
编写代码
对于NEON的初学者,内联函数的方式是比汇编更容易的,但是有经验的开发者(比如我....雾)可能对NEON汇编编程更为熟悉,毕竟我们需要时间去适应内联函数的编码方式啊!!!!
一些在真实开发过程中可能会出现的问,现描述如下:

Flexibility of instruction
使用汇编的方式可能会更灵活,主要体现在数据的load/store。
当然这个不足,可以在将来的编译器升级过程中进行解决。
有时候,编译器是有能力将两条内联函数指令优化为一条汇编指令的,比如:
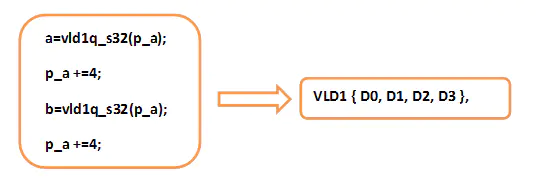
因此,伴随着ARMv8工具连的升级,有望使得内联函数方式有跟汇编一样的灵活度;
Register allocation:
当使用NEON汇编编程时,寄存器必须由用户分配,因此你必须清楚地知道哪个寄存器被占用了;
使用内联函数方式的好处之一是,你只管定义变量,不用管它的安全性,因为编译器会自动分配寄存器的,这是一个优点,但是有时候也是缺点;
实践证明:在内联函数编程模式下同时使用太多的NEON寄存器会使得gcc编译器产生寄存器分配异常。当这种情况发生时,许多的数据都被推进栈区(为啥?你心里没点B数么?NEON寄存器总共就这么多,提这么多的要求,消化不下啦,只能放到郊区的内存里面去啦,郊区那么远,你说浪费时间不!!!),这将会极大地降低程序的性能。
因此当使用内联函数编程时,得好好考虑这个问题,当出现性能异常的时候,比如C的性能居然比NEON的还要好,这个时候你首先要做的就是反汇编,来确认是不是出现寄存器分配问题了!
对于ARMv8-A AArch64,有更多的NEON寄存器(32个 128bit NEON寄存器),因此对于寄存器分配问题的影响就较低了!
Performance and compiler
在一个特定的平台下,NEON汇编的的性能表现仅仅取决于其实现代码,与编译器鸟关系都没有的啊!好处就是你能预测并估计你手调代码的性能表现,这很正常嘛!
相反的,内联函数的性能严重依赖于使用的编译器。不同的编译器会带来不同的性能,通常是老编译器性能会有最差的性能,同时使用老编译器时你要注意你内联函数的兼容性啊!
精调代码的时候,你不能预测和控制性能,但是偶尔也会有惊喜哟!,有时候内联函数的性能反而超过汇编方式,这不是不会出现,但是可以说是“罕见”。
编译器将会在NEON优化的过程中产生影响,下面这张图描述了NEON实现和优化的通常过程:
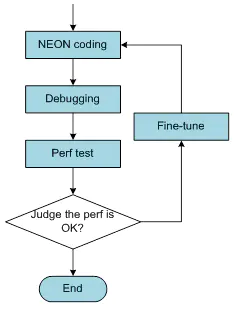
NEON汇编和内联方式有同样的实现过程,编码-调试-性能测试,但是他们却有不同的优化步骤:
汇编精调的方法如下:
- 改变实现方式,比如改变指令、调节并行度;
- 调整指令序列来减少数据依赖性(上面已经分析过了,就是怕流水线断掉);
- 试试我前面提到的那些skills
当精调汇编代码的时候,一个经验之谈(复杂的、富有经验的)是:
- 明确知道使用指令的数量;
- 使用PMU(
Performance Monitoring Unit)来获取执行周期; - 基于已使用指令的时间消耗来调整指令的序列,并尽你所能地最小化指令延时(延时间隙插入指令);
这种方式的的缺点是优化仅仅是针对于某个micro-architecture的,移植性不好啊!同时对于相对较小的收益来说,这也是非常耗时的,也就是性价比不是很高啊!
NEON intrinsics 精调的方法更难哟!:
- 使用汇编优化里面的那一套方法,整一遍试一下!
- 反汇编看数据依赖跟寄存器使用情况;
- 检查性能是否满足期望,如果没有,那就换个编译器再来一遍,知道性能满足期望了!
当移植ARMv7-A的汇编代码到ARMv7-A/v8-A进行兼容时,汇编代码的性能可以作为一个参考,因此我们很容易就知道何时算优化结束。
然而,当内联函数方式来优化ARMv8-A的代码时,是没有性能参考点的,因此很难确定当前的性能是否是最优值;
基于ARMv7-A的经验,可能有这样的疑问:是不是汇编就一定有更好的性能呢?我认为随着 ARMv8-A 环境的成熟化,内联函数将会有更好的性能。
Cross-platform and portability
许多现已存的NEON汇编代码,仅能在ARMv7-A/ARMv8-A平台下的AArch32模式下运行,假如你想让这些代码在ARMv8-A AArch64模式下运行,你必须重写这些代码,这需要花费很多的功夫啊!
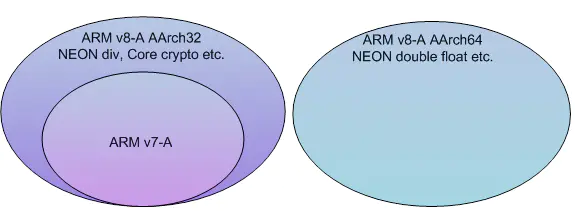
在这样的情形下,假如代码是用内联函数方式实现的,它们能够在ARMv8-A AArch64 模式下直接运行。
跨平台是一个明显的优势,同时,不同平台你仅仅需要保持一份代码,这大大减少了维护工作。
然而,由于ARMv7-A/ARMv8-A平台不同的硬件资源(Q寄存器数量的差异),有时候即使是使用内联函数,但还是需要两套代码的。
下面以Ne10工程下的FFT实现为例子:
// radix 4 butterfly with twiddles
scratch[0].r = scratch_in[0].r;
scratch[0].i = scratch_in[0].i;
scratch[1].r = scratch_in[1].r * scratch_tw[0].r - scratch_in[1].i * scratch_tw[0].i;
scratch[1].i = scratch_in[1].i * scratch_tw[0].r + scratch_in[1].r * scratch_tw[0].i;
scratch[2].r = scratch_in[2].r * scratch_tw[1].r - scratch_in[2].i * scratch_tw[1].i;
scratch[2].i = scratch_in[2].i * scratch_tw[1].r + scratch_in[2].r * scratch_tw[1].i;
scratch[3].r = scratch_in[3].r * scratch_tw[2].r - scratch_in[3].i * scratch_tw[2].i;
scratch[3].i = scratch_in[3].i * scratch_tw[2].r + scratch_in[3].r * scratch_tw[2].i;
以上的代码片段列出了FFT的基本操作单元-radix4 butterfly,从代码里面我们能推出如下信息:
- 假如2个
radix4 butterflies在1个循环里面执行,则需要20个64-bit NEON寄存器; - 假如4个
radix4 butterflies在1个循环里面执行,则需要20个128-bit NEON寄存器
而且, ARMv7-A/v8-A AArch32 and v8-A AArch64资源如下:
ARMv7-A/v8-A AArch32有:32 64-bit or 16 128-bit NEON registers.ARMv8-A AArch64 有:32 128-bit NEON registers.
考虑到上述因素,Ne10库的FFT实现代码里面,最终是有添加个汇编版本的:
- 汇编版本是用于
ARMv7-A/v8-A AAch32,里面是一个循环内执行2 radix4 butterflies; - 内联函数版本用于
ARMv8-A AArch64,里面是一个循环内执行4 radix4 butterflies;
上述实例表明:当维护一份跨平台(ARMv7-A/v8-A)的代码时,你需要关注一些例外情况。
总结
内联函数优化的越来越好了,甚至在ARMv8 平台下有优于汇编的性能,同时兼容性方面又比汇编好,因此使用内联函数是上上之选。
毕竟,NEON肯定会更新的,到时一更新你的底层汇编得全部跟着更新,但是使用内联函数的话就不要考虑这些了,反正编译器都帮我们做了嘛!
最后关于内联函数告诉后辈们几点人生经验:
- 使用的寄存器数量要考虑周全;
- 编译器注意好啊!
- 一定要看看产生的汇编代码啊!