- 集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起(也就是说需要分别部署HDFS集群和YARN集群,但是这两个集群在一个机器上部署)
HDFS集群:
负责海量数据的存储,集群中的角色主要有 NameNode / DataNode
YARN集群:
负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
(那mapreduce是什么呢?它其实是一个应用程序开发包)
- 服务器准备
本案例使用虚拟机服务器来搭建HADOOP集群,所用软件及版本:
Vmware 11.0
Centos 6.5 64bit
- 网络环境准备
采用NAT方式联网
网关地址:192.168.33.1
3个服务器节点IP地址:192.168.33.130、192.168.33.131、192.168.33.132、192.168.23.133
子网掩码:255.255.255.0
- 服务器系统设置
添加HADOOP用户
为HADOOP用户分配sudoer权限
同步时间
设置主机名
mini1、mini2、mini3、mini4
- 配置内网域名映射:/etc/hosts
192.168.33.130 mini1
192.168.33.131 mini2
192.168.33.132 mini3
192.168.33.133 mini4
- 配置ssh免密登陆
- 关闭防火墙
service iptables stop
chkconfi iptables off
- HADOOP安装部署
注意:hadoop的安装文件我们需要从官网下载源码文件到linux进行编译,因为官网编译的版本不一定适合我们现在的环境,所以需要重新编译源码。【源码编译步骤比较多,可以参考一下一篇好的博文,我这里就不班门弄斧了】
源码编译参考https://www.cnblogs.com/duking1991/p/6104304.html
- 上传HADOOP安装包
- 规划安装目录 /home/hadoop/apps/hadoop-2.6.1
- 解压安装包
tar -zxvf cenos-6.5-hadoop-2.6.4.tar.gz -C apps/

- 修改配置文件
- 最简化配置如下:
解压缩之后,进入到/home/hadoop/apps/hadoop-2.6.4/etc/hadoop目录

这个目录下有很多配置文件,但是不需要每一个配置文件都需要去配置
配置hadoop-env.sh即可(只需要在这个配置文件中加入java的路径即可)
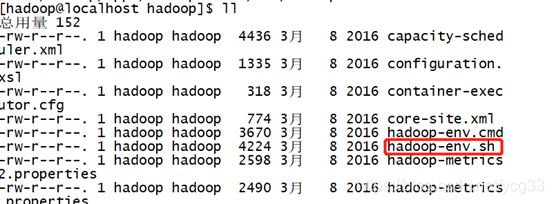
拿到当前机器的JAVA_HOME的路径
/usr/local/jdk7/jdk1.7.0_80

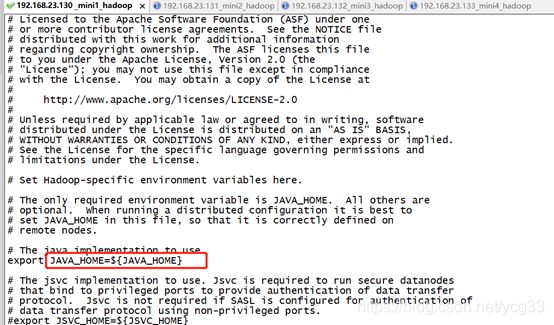
因为到时候启动的时候是通过一台机器ssh远程到其他机器上启动hadoop的,所以这个环境变量就不生效,需要我们首先配置好
vi hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/usr/local/jdk7/jdk1.7.0_80

如下四个配置文件是配置hadoop运行时的配置文件
核心配置文件core-site.xml
跟hdfs有关hdfs-site.xml
跟mapreduce有关mapred-site.xml.template -- 需要重命名为mapred-site.xml配置才能生效([hadoop@localhost hadoop]$ mv mapred-site.xml.template mapred-site.xml)
跟yran有关yarn-site.xml
其实这四个配置文件配置在哪一个配置文件里面都是可以的,但是为了方便管理分开配置;
公共配置在core-site.xml
fs.defaultFS
hdfs://192.168.23.130:9000
hadoop.tmp.dir
/home/HADOOP/apps/hadoop-2.6.1/tmp
vi hdfs-site.xml -- hdfs-site.xml有默认配置,我们可以不用配置,这里就简单配置一下
dfs.namenode.name.dir
/home/hadoop/data/name
dfs.datanode.data.dir
/home/hadoop/data/data
dfs.replication
2
dfs.secondary.http.address
192.168.23.130:50090
vi mapred-site.xml -- 这样配置之后,mapreduce就会交给yarn去跑,分布式的方式去跑。默认是local,在本地跑,不是分布式去跑。
mapreduce.framework.name
yarn
vi yarn-site.xml
yarn.resourcemanager.hostname
192.168.23.130
yarn.nodemanager.aux-services
mapreduce_shuffle
在mini1配置好上述的配置文件后,把整个解压后的hadoop安装到mini2,mini3,mini4
scp -r apps/ 192.168.23.131:/home/hadoop/
scp -r apps/ 192.168.23.132:/home/hadoop/
scp -r apps/ 192.168.23.133:/home/hadoop/
配置hadoop的环境变量 -- 配置之后就可以在机器的其他地方敲hadoop的命令
vim /etc/profile -- 要root用户操作
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.6.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

在mini1机器上配置好之后,把/etc/profile配置文件分发到mini2,mini3,mini4
scp /etc/profile 192.168.23.131:/etc/
scp /etc/profile 192.168.23.132:/etc/
scp /etc/profile 192.168.23.133:/etc/
配置好之后还不能立即启动集群,还需要格式化namenode。
Hadoop namenode -format

这个路径是我们刚刚配置的初始化的路径
如果我们要启动namenode只能在mini1机器上,因为我们在配置文件上写死了mini1为namenode,下图就是启动namenode的命令
首先cd到/home/hadoop/apps/hadoop-2.6.4/sbin下(如果配置好了hadoop的环境变量就可以在任意一个目录执行)
hadoop-daemon.sh start namenode

启动了namenode之后,可以通过jps命令查看

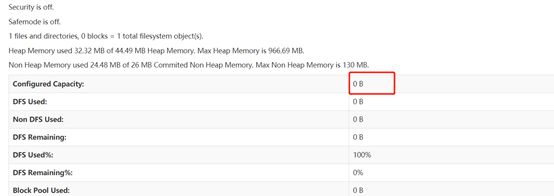
访问页面http://192.168.23.130:50070

因为是只启动的namenode,并没有启动datanode,所以文件系统的大小为0B
启动一个datanode节点,比如启动192.168.23.131
hadoop-daemon.sh start datanode

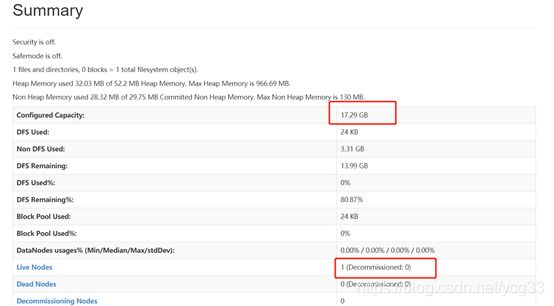
看容量已经扩大。那么问题来了,为什么我启动一台机器namenode就知道呢?因为我们刚才的配置文件是完全一样的,所以当他们启动的时候就知道namenode在哪里,所以namenode就知道容量变化了。
vi salves #配置集群的ip或者主机别名(注意是配置别名的时候要先在本地配置好/etc/hosts)
mini1
mini2
mini3
mini4
- 启动集群
方式一:手工一个机器一个机器去启动
hadoop-daemon.sh start namenode #启动namenode
hadoop-daemon.sh start datanode #启动datanode
yarn-daemon.sh start resourcemanager #启动resourcemanager
yarn-daemon.sh start nodemanager #启动nodemanager
方式二:通过脚本启动所有机器的dfs和yarn
前提:(1)需要配置从master到slave的ssh免密登录 (2)需要配置好/home/hadoop/apps/hadoop-2.6.4/etc/hadoop下的slaves配置文件,配置好所有的机器的别名

启动HDFS
sbin/start-dfs.sh
启动YARN
sbin/start-yarn.sh
-
测试
上传文件到HDFS
首先在hdfs上创建目录
[HADOOP@hdp-node-01 ~]$hadoop fs -mkdir -p /wordcount/input
[HADOOP@hdp-node-01 ~]$hadoop fs -put /home/hadoop/test20190226/20190226.txt /wordcount/input

从本地上传一个文件到hdfs
![]()
上传文件之后,启动一个hadoop客户端来查看文件系统中的文件

在管理平台上(http://192.168.23.130:50070)也可以看到已经上传的文件
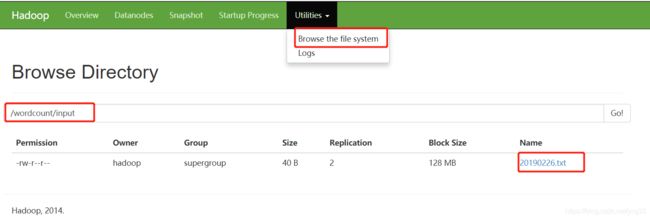
hadoop fs 表示启动hadoop的文件系统, -ls / 表示查看的是hadoop的文件系统的根目录,而不是linux机器的根目录

- 运行一个mapreduce程序
在HADOOP安装目录下,运行一个示例mr程序
首先需要创建目录/wordcount/input
![]()
命令如下:
[hadoop@mini1 mapreduce]$ hadoop fs -mkdir -p /wordcount/input
创建一个文件test.txt,内容this is a test mapreduce programming!
并上传到/wordcount/input


为了方便查看统计效果,指保留我们刚刚创建的一个文件,之前上传到这里的文件先删除

进入到cd /home/hadoop/apps/hadoop-2.6.4/share/hadoop/mapreduce
执行命令:
hadoop jar mapredcue-example-2.6.1.jar wordcount /wordcount/input /wordcount/output 
进入到mapreduce目录,看到下面有很多的jar包,这些jar都是一些例子,我们现在启动一个hadoop-mapreduce-examples-2.6.4.jar这个例子,命令: hadoop jar hadoop-mapreduce-examples-2.6.4.jar wordcount /wordcount/input /wordcount/output