hadoop学习笔记2:eclipse开发MapReduce
hadoop学习笔记2:eclipse开发MapReduce
伪分布式搭建见:Hadoop学习笔记1:伪分布式环境搭建
环境:
虚拟机:Ubuntu16.0
jdk1.8.0_111,
eclipse4.6.0,
hadoop-2.7.3,
下载地址见:
http://blog.csdn.net/yhhyhhyhhyhh/article/details/53945810
hadoop-eclipse-plugin-2.7.3,
编译好的jar包下载地址:
http://download.csdn.net/download/yhhyhhyhhyhh/9726479
1.eclipse安装及快捷方式
1)解压并测试启动eclipse
sudo tar -zxvf ~/eclipse-jee-neon-1a-linux-gtk-x86_64.tar.gz -C/usr/local
cd /usr/local/eclipse
./eclipse2)eclipse快捷方式
创建eclipse.desktop
sudo vim /usr/share/applications/eclipse.desktop在eclipse.desktop添加以下内容
[Desktop Entry]
Version=1.0
Encoding=UTF-8
Name=Eclipse4.6.0
Exec=eclipse
TryExec=eclipse
Comment=Eclipse4.6.0,EclipseSDK
Exec=/usr/local/eclipse/eclipse
Icon=/usr/local/eclipse/icon.xpm
Terminal=false
Type=Application
Categories=Application;Development;创建启动器
sudo vim /usr/bin/eclipse在其中添加如下内容
#!/bin/sh
export MOZILLA_FIVE_HOME="/usr/lib/mozilla/"
export ECLIPSE_HOME="/usr/local/eclipse"
$ECLIPSE_HOME/eclipse $*添加可执行权限
sudo chmod +x /usr/bin/eclipse注意:如果提示找到不jdk环境:在eclipse下建立软连接

yhh@ubuntu:/usr/local/eclipse$ sudo ln -s /usr/local/jdk1.8.0_111/jre/ jreeclipse快捷方式创建成功如下:


2. hadoop-eclipse-plugin-2.7.3的安装
yhh@ubuntu:~$ cd /usr/local/eclipse/
yhh@ubuntu:/usr/local/eclipse$ sudo cp ~/hadoop-eclipse-plugin-2.7.3.jar ./plugins/
#复制到eclipse下的plugins 目录下
yhh@ubuntu:/usr/local/eclipse$ ./eclipse -clean # 添加插件后需要用这种方式使插件生效3. hadoop插件在eclipse中的配置
安装好Hadoop-Eclipse-Plugin插件,启动 Eclipse 后就可以在左侧的Project Explorer中看到 DFS Locations(若看到的是 welcome 界面,点击左上角的 x 关闭就可以看到了)。
注意:熟悉Java开发的,对eclipse视图切换应该很熟悉,不熟悉的话,如果DFS Locations或者Map/Reduce Locations面板没出现的话。只要配置了hadoop-eclispe插件,可以打开map/reduce视图,reset,见2)打开Map/Reduce视图,这里可以先配置,不影响。
1)配置hadoop安装目录
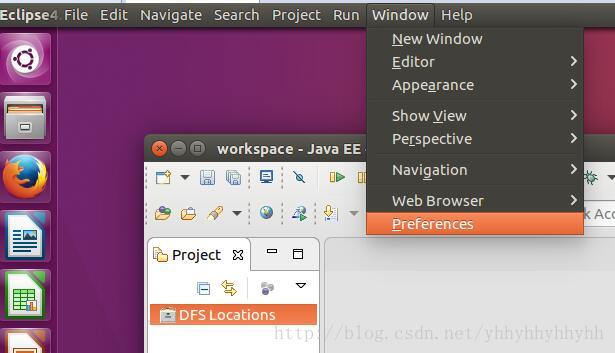

2)打开Map/Reduce视图


注意:熟悉Java开发的,对eclipse视图切换应该很熟悉,不熟悉的话,如果DFS Locations或者Map/Reduce Locations面板没出现的话。只要配置了hadoop-eclispe插件,可以打开map/reduce视图,reset,如下图。


3)建立与hadoop集群的连接


注意:hadoop需要在终端中启动,这里才会链接上。
hadoop启动前:

hadoop启动后:

4.eclipse中建立hadoop工程
这里以hadoop自带的wordcount例子测试。
在Hadoop学习笔记1:伪分布式环境搭建中,伪分布式、分布式的Hadoop数据是在hdfs下的目录。所以需要预先将数据上传到hdfs下的目录中。
1)准备数据
在/usr/local/input创建三个txt文件,f1,f2的内容随便输入,f3输入以下:
127.0.0.1,-,-,[08/May/2014:13:42:40 +0800],GET / HTTP/1.1,200,11444
127.0.0.1,-,-,[08/May/2014:13:42:42 +0800],GET /jygl/jaxrs/teachingManage/ClassBatchPlanService/getCurrentClassPlanVO HTTP/1.1,204,-
127.0.0.1,-,-,[08/May/2014:13:42:42 +0800],GET /jygl/jaxrs/teachingManage/ClassBatchPlanService/getCurClassPlanVO HTTP/1.1,204,-
127.0.0.1,-,-,[08/May/2014:13:42:47 +0800],GET /jygl/jaxrs/right/isValidUserByType/1-admin-superadmin HTTP/1.1,200,20
127.0.0.1,-,-,[08/May/2014:13:42:47 +0800],GET /jygl/jaxrs/right/getUserByLoginName/admin HTTP/1.1,200,198
0:0:0:0:0:0:0:1,-,-,[08/May/2014:13:42:47 +0800],GET /jyglFront/right_login2home?loginName=admin&password=superadmin&type=1 HTTP/1.1,200,2525
0:0:0:0:0:0:0:1,-,-,[08/May/2014:13:42:47 +0800],GET /jyglFront/mainView/navigate/style/style.css HTTP/1.1,304,-
0:0:0:0:0:0:0:1,-,-,[08/May/2014:13:42:47 +0800],GET /jyglFront/mainView/navigate/js/tree.js HTTP/1.1,304,-
0:0:0:0:0:0:0:1,-,-,[08/May/2014:13:42:47 +0800],GET /jyglFront/mainView/navigate/js/jquery.js HTTP/1.1,304,-
0:0:0:0:0:0:0:1,-,-,[08/May/2014:13:42:47 +0800],GET /jyglFront/mainView/navigate/js/frame.js HTTP/1.1,304,-
0:0:0:0:0:0:0:1,-,-,[08/May/2014:13:42:47 +0800],GET /jyglFront/mainView/navigate/images/logo.png HTTP/1.1,304,-
0:0:0:0:0:0:0:1,-,-,[08/May/2014:13:42:47 +0800],GET /jyglFront/mainView/navigate/images/leftmenu_bg.gif HTTP/1.1,404,1105
0:0:0:0:0:0:0:1,-,-,[08/May/2014:13:42:47 +0800],GET /jyglFront/mainView/navigate/menuList.jsp HTTP/1.1,200,47603
0:0:0:0:0:0:0:1,-,-,[08/May/2014:13:42:47 +0800],GET /jyglFront/mainView/navigate/style/images/header_bg.jpg HTTP/1.1,304,-
0:0:0:0:0:0:0:1,-,-,[08/May/2014:13:42:47 +0800],GET /jyglFront/mainView/navigate/images/allmenu.gif HTTP/1.1,404,1093
0:0:0:0:0:0:0:1,-,-,[08/May/2014:13:42:47 +0800],GET /jyglFront/mainView/navigate/images/toggle_menu.gif HTTP/1.1,404,1105
127.0.0.1,-,-,[08/May/2014:13:42:48 +0800],GET /jygl/jaxrs/article/getArticleList/10-1 HTTP/1.1,200,20913
127.0.0.1,-,-,[08/May/2014:13:42:48 +0800],GET /jygl/jaxrs/article/getTotalArticleRecords HTTP/1.1,200,22
0:0:0:0:0:0:0:1,-,-,[08/May/2014:13:42:48 +0800],GET /jyglFront/baseInfo_articleList?flag=1 HTTP/1.1,200,8989
0:0:0:0:0:0:0:1,-,-,[08/May/2014:13:42:48 +0800],GET /jyglFront/mainView/studentView/style/images/nav_10.png HTTP/1.1,404,1117
127.0.0.1,-,-,[08/May/2014:13:43:21 +0800],GET /jygl/jaxrs/right/isValidUserByType/1-admin-superadmin HTTP/1.1,200,20
127.0.0.1,-,-,[08/May/2014:13:43:21 +0800],GET /jygl/jaxrs/right/getUserByLoginName/admin HTTP/1.1,200,198
0:0:0:0:0:0:0:1,-,-,[08/May/2014:13:43:21 +0800],GET /jyglFront/right_login2home?loginName=admin&password=superadmin&type=1 HTTP/1.1,200,2525
0:0:0:0:0:0:0:1,-,-,[08/May/2014:13:43:21 +0800],GET /jyglFront/mainView/navigate/js/tree.js HTTP/1.1,304,-
0:0:0:0:0:0:0:1,-,-,[08/May/2014:13:43:21 +0800],GET /jyglFront/mainView/navigate/js/jquery.js HTTP/1.1,304,-
0:0:0:0:0:0:0:1,-,-,[08/May/2014:13:43:21 +0800],GET /jyglFront/mainView/navigate/js/frame.js HTTP/1.1,304,-
0:0:0:0:0:0:0:1,-,-,[08/May/2014:13:43:21 +0800],GET /jyglFront/mainView/navigate/style/style.css HTTP/1.1,304,-
0:0:0:0:0:0:0:1,-,-,[08/May/2014:13:43:21 +0800],GET /jyglFront/mainView/navigate/menuList.jsp HTTP/1.1,200,47603
0:0:0:0:0:0:0:1,-,-,[08/May/2014:13:43:21 +0800],GET /jyglFront/mainView/navigate/images/logo.png HTTP/1.1,304,-
0:0:0:0:0:0:0:1,-,-,[08/May/2014:13:43:21 +0800],GET /jyglFront/mainView/navigate/images/leftmenu_bg.gif HTTP/1.1,404,1105
0:0:0:0:0:0:0:1,-,-,[08/May/2014:13:43:21 +0800],GET /jyglFront/mainView/navigate/images/toggle_menu.gif HTTP/1.1,404,1105
0:0:0:0:0:0:0:1,-,-,[08/May/2014:13:43:21 +0800],GET /jyglFront/mainView/navigate/style/images/header_bg.jpg HTTP/1.1,304,-
127.0.0.1,-,-,[08/May/2014:13:43:21 +0800],GET /jygl/jaxrs/article/getArticleList/10-1 HTTP/1.1,200,20913
命令:
yhh@ubuntu:/usr/local/hadoop$ cd ..
yhh@ubuntu:/usr/local$ sudo mkdir ./input
yhh@ubuntu:/usr/local$ cd ./input
yhh@ubuntu:/usr/local/input$ sudo vim f1.txt
yhh@ubuntu:/usr/local/input$ sudo vim f2.txt
yhh@ubuntu:/usr/local/input$ sudo vim f3.txt在hdfs下建立文件夹 /user/yhh/input(**为用户名我的是yhh)
命令:
yhh@ubuntu:/usr/local$ cd ./hadoop/
yhh@ubuntu:/usr/local/hadoop$ ./bin/hdfs dfs -ls /
#可以先查看下hdfs下的文件级文件夹
yhh@ubuntu:/usr/local/hadoop$ ./bin/hdfs dfs -mkdir /user
yhh@ubuntu:/usr/local/hadoop$ ./bin/hdfs dfs -mkdir /user/yhh
yhh@ubuntu:/usr/local/hadoop$ ./bin/hdfs dfs -mkdir /user/yhh/input
yhh@ubuntu:/usr/local/hadoop$ ./bin/hdfs dfs -put /usr/local/input/f*.txt /user/yhh/input
#将数据上传到hdfs下的/user/yhh/input(如果已存在会有提示)上传数据到hdfs后:

2)Eclipse建立hadoop工程测试(以WordCount为例)
在Eclipse中创建MapReduce项目和创建普通的java项目一样。

创建WordCount 项目后,添加类。
选择 New -> Class需要填写两个地方:
在 Package 处填写 org.apache.hadoop.examples;
在 Name 处填写 WordCount。
在WordCount.java:添加如下代码(可以将自动生成的删除)
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
@SuppressWarnings("unused")
public class WordCount {
public static class TokenizerMapper
extends Mapper{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//通过配置工程输入参数
//String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
//代码中直接输入参数,从hdfs输入(具体数据在hdfs://localhost:9000/user/yhh/input)
String[] otherArgs=new String[]{"input/f1.txt","output"}; //此处可以指定hdfs下具体的输入文件
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount " );
System.exit(2);
}
//每次运行时自动删除输出目录
Path outputPath = new Path(otherArgs[1]);
outputPath.getFileSystem(conf).delete(outputPath, true);
//1、设置job的基础属性
@SuppressWarnings("deprecation")
Job job = new Job(conf, "WordCount");
job.setJarByClass(WordCount.class);
//2、设置Map与Reudce的类
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
//3、设置map与reduce的输出键值类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//4、设置输入输出路径
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
//5、运行程序
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
} 注:如果需要通过配置工程输入参数::
//通过配置工程输入参数
//String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();

注意:新建工程运行所需hadoop配置文件:
在终端中通过命令复制到/workspace/WordCount/src下(具体自己的,在命令中修改)
cp /usr/local/hadoop/etc/hadoop/core-site.xml ~/workspace/WordCount/src
cp /usr/local/hadoop/etc/hadoop/hdfs-site.xml ~/workspace/WordCount/src
cp /usr/local/hadoop/etc/hadoop/log4j.properties ~/workspace/WordCount/src注意:1)数据上传到hdfs
2)终端执行复制配置文件
3)运行成功后,在eclipse查看输出文件
都需要Refresh或者重启eclipse工程,相关位置才会出现对应的文件
4)输入输出已经在代码中指定,并且设置了运行自动删除上次的输出目录。hadoop job的简单属性设置在代码中。
下图Refresh或者重启eclipse工程:


测试成功:

f3.txt的测试:屏蔽掉测试f1.txt的代码,复制如下代码
package org.apache.hadoop.examples;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class WordCount {
enum Counter{
LINESKIP,
}
public static class CountMap extends Mapper{
private static final IntWritable one = new IntWritable(1);
public void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException{
String line = value.toString();
try{
String[] lineSplit = line.split(",");
String requestUrl = lineSplit[4];
requestUrl = requestUrl.substring(requestUrl.indexOf(' ')+1, requestUrl.lastIndexOf(' '));
Text out = new Text(requestUrl);
context.write(out,one);
}catch(java.lang.ArrayIndexOutOfBoundsException e){
context.getCounter(Counter.LINESKIP).increment(1);
}
}
}
public static class CountReduce extends Reducer{
public void reduce(Text key, Iterable values,Context context)throws IOException{
int count = 0;
for(IntWritable v : values){
count = count + 1;
}
try {
context.write(key, new IntWritable(count));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args)throws Exception{
Configuration conf = new Configuration();
//通过配置工程输入参数
//String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
//代码中直接输入参数,从hdfs输入(具体数据在hdfs://localhost:9000/user/yhh/input)
String[] otherArgs=new String[]{"input/f3.txt","output"};
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount " );
System.exit(2);
}
//设置每次运行时自动删除输出目录
Path outputPath = new Path(otherArgs[1]);
outputPath.getFileSystem(conf).delete(outputPath, true);
Job job = new Job(conf, "WordCount");
//1、设置job的基础属性
job.setJarByClass(WordCount.class);
//2、设置Map与Reudce的类
job.setMapperClass(CountMap.class);
job.setReducerClass(CountReduce.class);
//3、设置map与reduce的输出键值类型
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//4、设置输入输出路径
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
//5、运行程序
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
测试成功:


参考:
大神的帖子:
http://www.powerxing.com/hadoop-build-project-using-eclipse/
https://my.oschina.net/132722/blog/168022
http://blog.csdn.net/jediael_lu/article/details/43416751
http://blog.csdn.net/liyong199012/article/details/25423221