ElasticSearch初探之所有初次使用记录(三)复合查询及全文查询
-
- must,must_not,should
- 关于bool query:
- must
- filter
- should
- must_not
- 综合
- term与match的区别:
- match_all,match,match_phrase,match_phrase_prefix,multi_match,multi_mutch
- match_all
- match
- match_phrase
- match_phrase_prefix
- multi_mutch
- TODO
- 更正
- must,must_not,should
must,must_not,should
关于bool query:
- Bool查询对应Lucene中的BooleanQuery,它由一个或者多个子句组成,每个子句都有特定的类型。
| occurrence | 描述 |
|---|---|
| must | 返回的文档必须满足must子句的条件,并且参与计算分值 |
| filter | 【filter以前时单独的query DSL,现在归入bool query】;子句(查询)必须出现在匹配的文档中。然而,不同于must查询的是——它不参与分数计算。 Filter子句在过滤器上下文(filter context)中执行,这意味着score被忽略并且子句可缓存【所以filter可能更快】 |
| should | “权限”比must/filter低。如果没有must或者filter,有一个或者多个should子句,那么只要满足一个就可以返回。minimum_should_match参数定义了至少满足几个子句。 |
| must_not | 返回的文档必须不满足must_not定义的条件 |
must
bank数据中,找出年龄必须为22,且在Waverly城市的文档
# must
POST /bank/account/_search?pretty
{
"query": {
"bool": {
"must": [
{"match": {
"age": "22"
}},
{"match": {
"city": "Waverly"
}}
]
}
}
}filter
对多个字段filter时,range报错:
[range] query doesn’t support multiple fields, found [balance] and [age]”
非bool query的查询也是同样,不允许多字段
也不允许多个filter存在
因为我想查找多个range,所以terms不适用
但是kibana中试了下,是可以的

# filter
GET /bank/_search?pretty
{
"query": {
"bool": {
"must": { "match_all": {} },
"filter": {
"range": {
"balance": {
"gte": 20000,
"lte": 30000
}
}
}
}
}
}多range已经解决,见更正1
should
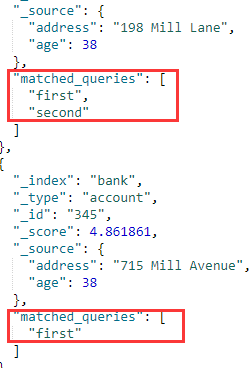
找出地址包含”mill”或者”lane”的文档
- “minimum_should_match” : 2
表示3个条件至少符合两个 - 如果想知道到底是bool里面哪个条件匹配,可以使用named查询【给每个查询取个名字,使用”_name”参数】
比如:”match”: { “address”:{ “query”:”mill”, “_name”:”first” } }
# should
GET /bank/_search?pretty
{
"query": {
"bool": {
"should": [
{ "match": { "address":{ "query":"mill", "_name":"first" } }},
{ "match": { "address":{"query":"lane","_name":"second" } }},
{ "term": { "age": "38" } }
],
"minimum_should_match" : 2
}
},
"_source": {
"includes" : [
"address",
"banalance",
"age"
]
}
}
参考
must_not
换汤不换药,略
综合
# 综合
POST chinese_data/poi/_search?pretty
{
"query": {
"bool": {
"must": [
{"match": {
"addr": "浦东新区"
}
},
{
"term": {
"name": {
"value": "临江队王家渡"
}
}
}
],
"filter": {
"term" : { "citycode" : "21" }
},
"must_not":
{
"match":{"name":"386号楼"}
}
}
}
}term与match的区别:
- term查询:只匹配指定的字段中包含指定的词的文档,terms可指定多个字段
- term是代表完全匹配,也就是精确查询,搜索前不会再对搜索词进行分词,所以我们的搜索词必须是文档分词集合中的一个
- match查询会先对搜索词进行分词,分词完毕后再逐个对分词结果进行匹配,因此相比于term的精确搜索,match是分词匹配搜索
更具体可参考这篇文章
match_all,match,match_phrase,match_phrase_prefix,multi_match,multi_mutch
match_all
能够匹配索引中的所有文件。
可以在查询中使用boost包含加权值,它将赋给所有跟它匹配的文档,计算score时用到。
# match_all
POST bank/account/_search
{"query": {
"match_all": {}
},
"sort":
{
"age": {
"order": "desc"
}
},
"from": 10,
"size": 20
}match
match查询相当于模糊匹配,只包含其中一部分关键词就行
“fields“参数已经不再使用
[match] query does not support [gte]
“stored_fields”参数适用于在mapping中明确标记为”store”的字段【不推荐,推荐使用_source】
# match
POST bank/account/_search
{
"_source": ["gender","age","employer"],
"query": {
"match": {
"age": "35"
}
},
"sort":
{
"age": {
"order": "desc"
}
},
"from": 10,
"size": 20
}match_phrase
match_phrase 短语匹配查询,要求必须全部精确匹配,且顺序必须与指定的短语相同。match_phrase查询首先解析查询字符串来产生一个词条列表。然后会搜索所有的词条,但只保留包含了所有搜索词条的文档。
slop参数:
- slop参数告诉match_phrase查询词条能够相隔多少个单次时将文档视为匹配。
- 尽管在使用了slop的短语匹配中,所有的单词都需要出现,但是单词的出现顺序可以不同。如果slop的值足够大,那么单词的顺序可以是任意的。
”match_phrase“与”slop“可参考这篇文章
# match_phrase
POST /bank/account/_search?pretty
{
"query":{
"match_phrase": {
"address": {
"query": "620 National Drive",
"slop": 2}
}
}
}620 National D不能匹配620 National Drive
match_phrase_prefix
# match_phrase_prefix
POST /chinese_data/poi/_search?pretty
{
"query":{
"match_phrase_prefix": {
"addr": {
"query": "上海市浦prefix1",
"slop": 0}
}
}
}- 与match_phrase不同之处在于,match_phrase_prefix中的短语,在最后一个词时,将其视为其他词的前缀,允许对其进行“扩展”,也就是说,620 National D**也许可以匹配**620 National Drive
演示区别

继续探索,先准备几条”精心设计“的数据
curl -XPOST "http://172.22.112.1:9200/chinese_data/poi/_bulk" -H 'Content-Type: application/json' -d'
{"index":{"_id":"11"}}
{"addr":"上海市占位3市区浦东 空格算不新区"}
{"index":{"_id":"12"}}
{"addr":"上海市占3个浦prefix123456789新区"}
{"index":{"_id":"13"}}
{"addr":"上海市123 45 3市区浦东"}
{"index":{"_id":"14"}}
{"addr":"上海市word123 123 wprd浦prefix123456789新区"}
{"index":{"_id":"15"}}
{"addr":"上海市,。! 123 word* *浦prefix123456789新区"}
{"index":{"_id":"18"}}
{"addr":"上海市,。! 1,23 word 浦prefix123456789新区"}
{"index":{"_id":"19"}}
{"addr":"上海市,。!,.! , . ! 浦prefix123456789新区"}
{"index":{"_id":"20"}}
{"addr":"上海市,。!,.! , . ! 浦123456789prefix新区"}
{"index":{"_id":"21"}}
{"addr":"上海市,66。! 123 word* *浦prefix123456789新区"}
'1 .slop为3时,可以检索出结果,为2时无结果
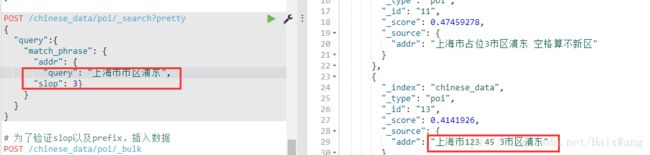
2 .空格是否计为一个词?
否,见上图。3 .查询词中的空格也不算作检索词,也就是说:
上海市 市区 与上海市市区意义时一样的4 .
*字符在文档中应该是有特殊意义,但是以下结果我还是想不明白

5 .*字符在检索词中也有特殊含义,但是不是通配符能解释的

6 .
能检索出这样的,懵,如何对待标点符号的?

7 .
多个来连续的标点符号,算作一个词;且不区分中英文符

标点符号不计数

对于slop的小小总结:
- 可对汉字计算个数
- 空格不计入(无论是结果中,还是检索词中)
- slop中的词,对于单次来说,空格隔开。单次数字连一起,视为一个单词。比如word123
- 空格肯定可以作为数字与数字间的间隔标志,但是其他字符未知
- *字符在文档中时,在查询时被”特殊处理“了
- 检索文档中,对于slop,标点符号不计数【但是在检索词中的标点,有时是有用的】
“slop”与”max_expansions”可一起使用
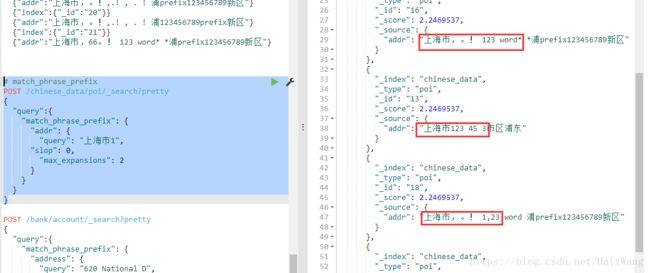
# match_phrase_prefix
POST /chinese_data/poi/_search?pretty
{
"query":{
"match_phrase_prefix": {
"addr": {
"query": "上海市1",
"slop": 0,
"max_expansions": 2
}
}
}
}
multi_mutch
multi_mutch可以进行跨字段查询,也就是说,对于”query“:“这是需要检索的”
可以在指定的多个字段中检索之,介于全文检索和单个字段检索字间
# multi_match
POST /chinese_data/poi/_search?pretty
{
"query":{
"multi_match": {
"query": "上海市",
"fields": ["addr","name"]
}
}
}- 还可以指定“权重”
- tie_breaker等很多的其他参数
- tie_breaker作用:除best_fields 指定的字段,其他字段的得分需要×tie_breaker的值。

TODO
- 一个查询中多range
已解决,见更正——1
match_phrase如何实现给定一个数值,间隔单次小于该值的就可以返回 也是match_phrase,其究竟如何处理检索词以及文档中的标点,“*”字符
更正
- 使用聚合api进行多range检索【语法是可以实现的,但是并没有返回“正确”结果】
# 多range
POST /bank/_search?pretty
{
"aggs": {
"tr_more_range": {
"range": {
"field": "balance",
"ranges": [
{"to": 1000},
{"from": 3000,"to":4000},
{"from": 5000}
]
}
}
}
}