redis cluster的介绍及搭建
redis cluster算法演变
hash算法 -> 一致性hash算法(memcached) -> redis cluster,hash slot算法
用不同的算法,就决定了在多个master节点的时候,数据如何分布到这些节点上去,解决这个问题
1、redis cluster介绍
redis cluster
(1)自动将数据进行分片,每个master上放一部分数据
(2)提供内置的高可用支持,部分master不可用时,还是可以继续工作的
在redis cluster架构下,每个redis要放开两个端口号,比如一个是6379,另外一个就是加10000的端口号,比如16379
16379端口号是用来进行节点间通信的,也就是cluster bus的东西,集群总线。cluster bus的通信,用来进行故障检测,配置更新,故障转移授权
cluster bus用了另外一种二进制的协议,主要用于节点间进行高效的数据交换,占用更少的网络带宽和处理时间
2、最老土的hash算法和弊端(大量缓存重建)

3、一致性hash算法(自动缓存迁移)+虚拟节点(自动负载均衡)
一致性hash算法的讲解和优点

一致性hash算法的虚拟节点实现负载均衡

4、redis cluster的hash slot算法
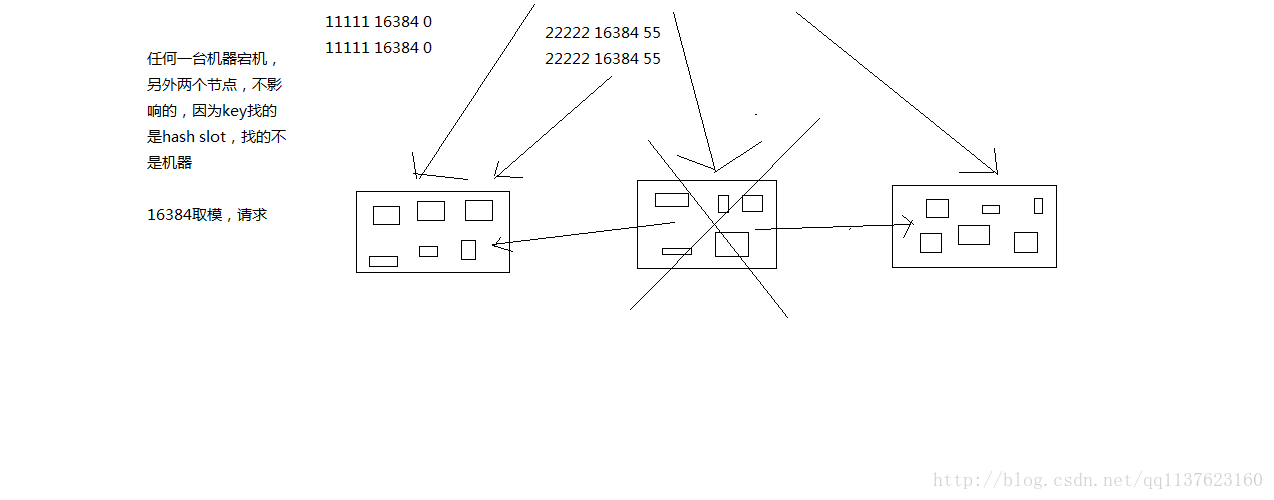
redis cluster有固定的16384个hash slot,对每个key计算CRC16值,然后对16384取模,可以获取key对应的hash slot
redis cluster中每个master都会持有部分slot,比如有3个master,那么可能每个master持有5000多个hash slot
hash slot让node的增加和移除很简单,增加一个master,就将其他master的hash slot移动部分过去,减少一个master,就将它的hash slot移动到其他master上去
移动hash slot的成本是非常低的
客户端的api,可以对指定的数据,让他们走同一个hash slot,通过hash tag来实现
5、redis cluster的重要配置
cluster-enabled
6、在三台机器上启动6个redis实例
(1)在eshop-cache03上部署目录
/etc/redis(存放redis的配置文件),/var/redis/6379(存放redis的持久化文件)
(2)编写配置文件
redis cluster集群,要求至少3个master,去组成一个高可用,健壮的分布式的集群,每个master都建议至少给一个slave,3个master,3个slave,最少的要求
正式环境下,建议都是说在6台机器上去搭建,至少3台机器
保证,每个master都跟自己的slave不在同一台机器上,如果是6台自然更好,一个master+一个slave就死了
3台机器去搭建6个redis实例的redis cluster
mkdir -p /etc/redis-cluster
mkdir -p /var/log/redis
mkdir -p /var/redis/7001
port 7001
cluster-enabled yes
cluster-config-file /etc/redis-cluster/node-7001.conf
cluster-node-timeout 15000
daemonize yes
pidfile /var/run/redis_7001.pid
dir /var/redis/7001
logfile /var/log/redis/7001.log
bind 192.168.31.187
appendonly yes
至少要用3个master节点启动,每个master加一个slave节点,先选择6个节点,启动6个实例
将上面的配置文件,在/etc/redis下放6个,分别为: 7001.conf,7002.conf,7003.conf,7004.conf,7005.conf,7006.conf
(3)准备生产环境的启动脚本
在/etc/init.d下,放6个启动脚本,分别为: redis_7001, redis_7002, redis_7003, redis_7004, redis_7005, redis_7006
每个启动脚本内,都修改对应的端口号
(4)分别在3台机器上,启动6个redis实例
将每个配置文件中的slaveof给删除
7、创建集群
注意:
也许你运行”gem install redis” 会报redis requires Ruby version >= 2.2.2
这是Centos默认支持ruby到2.0.0,可gem 安装redis需要最低是2.2.2
解决办法是 先安装rvm,再把ruby版本提升至2.3.3
具体解决方案:http://blog.csdn.net/qq1137623160/article/details/79178099
安装ruby
yum install -y ruby
yum install -y rubygems
gem install redis
cp /usr/local/redis-3.2.8/src/redis-trib.rb /usr/local/bin
redis-trib.rb create –replicas 1 192.168.0.118:7001 192.168.0.118:7002 192.168.0.119:7003 192.168.0.119:7004 192.168.0.120:7005 192.168.0.120:7006
–replicas: 每个master有几个slave
6台机器,3个master,3个slave,尽量自己让master和slave不在一台机器上
yes
redis-trib.rb check 192.168.31.187:7001
8、读写分离+高可用+多master
读写分离:每个master都有一个slave
高可用:master宕机,slave自动被切换过去
多master:横向扩容支持更大数据量
1、实验多master写入 -> 海量数据的分布式存储
你在redis cluster写入数据的时候,其实是你可以将请求发送到任意一个master上去执行
但是,每个master都会计算这个key对应的CRC16值,然后对16384个hashslot取模,找到key对应的hashslot,找到hashslot对应的master
如果对应的master就在自己本地的话,set mykey1 v1,mykey1这个key对应的hashslot就在自己本地,那么自己就处理掉了
但是如果计算出来的hashslot在其他master上,那么就会给客户端返回一个moved error,告诉你,你得到哪个master上去执行这条写入的命令
什么叫做多master的写入,就是每条数据只能存在于一个master上,不同的master负责存储不同的数据,分布式的数据存储
100w条数据,5个master,每个master就负责存储20w条数据,分布式数据存储
高并发、高性能、每日上亿流量,redis持久化 -> 灾难的时候,做数据恢复,复制 -> 读写分离,扩容slave,支撑更高的读吞吐,redis怎么支撑读QPS超过10万,几十万; 哨兵,在redis主从,一主多从,怎么保证99.99%可用性; redis cluster,海量数据
天下武功,都出自一脉,研究过各种大数据的系统,redis cluster讲解了很多原理,跟elasticsearch,很多底层的分布式原理,都是类似的
redis AOF,fsync
elasticsearch建立索引的时候,先写内存缓存,每秒钟把数据刷入os cache,接下来再每隔一定时间fsync到磁盘上去
redis cluster,写可以到任意master,任意master计算key的hashslot以后,告诉client,重定向,路由到其他mater去执行,分布式存储的一个经典的做法
elasticsearch,建立索引的时候,也会根据doc id/routing value,做路由,路由到某个其他节点,重定向到其他节点去执行
分布式的一些,hadoop,spark,storm里面很多核心的思想都是类似的
9、实验不同master各自的slave读取 -> 读写分离
在这个redis cluster中,如果你要在slave读取数据,那么需要带上readonly指令,get mykey1
redis-cli -c启动,就会自动进行各种底层的重定向的操作
实验redis cluster的读写分离的时候,会发现有一定的限制性,默认情况下,redis cluster的核心的理念,主要是用slave做高可用的,每个master挂一两个slave,主要是做数据的热备,还有master故障时的主备切换,实现高可用的
redis cluster默认是不支持slave节点读或者写的,跟我们手动基于replication搭建的主从架构不一样的
slave node,readonly,get,这个时候才能在slave node进行读取
redis cluster,主从架构是出来,读写分离,复杂了点,也可以做,jedis客户端,对redis cluster的读写分离支持不太好的
默认的话就是读和写都到master上去执行的
如果你要让最流行的jedis做redis cluster的读写分离的访问,那可能还得自己修改一点jedis的源码,成本比较高
要不然你就是自己基于jedis,封装一下,自己做一个redis cluster的读写分离的访问api
核心的思路,就是说,redis cluster的时候,就没有所谓的读写分离的概念了
读写分离,是为了什么,主要是因为要建立一主多从的架构,才能横向任意扩展slave node去支撑更大的读吞吐量
redis cluster的架构下,实际上本身master就是可以任意扩展的,你如果要支撑更大的读吞吐量,或者写吞吐量,或者数据量,都可以直接对master进行横向扩展就可以了
也可以实现支撑更高的读吞吐的效果
不会去跟大家直接讲解的,很多东西都要带着一些疑问,未知,实际经过一些实验和操作之后,让你体会的更加深刻一些
redis cluster,主从架构,读写分离,没说错,没有撒谎
redis cluster,不太好,server层面,jedis client层面,对master做扩容,所以说扩容master,跟之前扩容slave,效果是一样的
9、实验自动故障切换 -> 高可用性
redis-trib.rb check 192.168.31.187:7001
比如把master1,187:7001,杀掉,看看它对应的19:7004能不能自动切换成master,可以自动切换
切换成master后的19:7004,可以直接读取数据
再试着把187:7001给重新启动,恢复过来,自动作为slave挂载到了19:7004上面去
10、redis水平扩容
redis cluster模式下,不建议做物理的读写分离了
我们建议通过master的水平扩容,来横向扩展读写吞吐量,还有支撑更多的海量数据
redis单机,读吞吐是5w/s,写吞吐2w/s
扩展redis更多master,那么如果有5台master,不就读吞吐可以达到总量25/s QPS,写可以达到10w/s QPS
redis单机,内存,6G,8G,fork类操作的时候很耗时,会导致请求延时的问题
扩容到5台master,能支撑的总的缓存数据量就是30G,40G -> 100台,600G,800G,甚至1T+,海量数据
redis是怎么扩容的
11、加入新master
mkdir -p /var/redis/7007
port 7007
cluster-enabled yes
cluster-config-file /etc/redis-cluster/node-7007.conf
cluster-node-timeout 15000
daemonize yes
pidfile /var/run/redis_7007.pid
dir /var/redis/7007
logfile /var/log/redis/7007.log
bind 192.168.31.227
appendonly yes
搞一个7007.conf,再搞一个redis_7007启动脚本
手动启动一个新的redis实例,在7007端口上
redis-trib.rb add-node 192.168.31.227:7007 192.168.31.187:7001
redis-trib.rb check 192.168.31.187:7001
连接到新的redis实例上,cluster nodes,确认自己是否加入了集群,作为了一个新的master
12、reshard一些数据过去
resharding的意思就是把一部分hash slot从一些node上迁移到另外一些node上
redis-trib.rb reshard 192.168.31.187:7001
要把之前3个master上,总共4096个hashslot迁移到新的第四个master上去
How many slots do you want to move (from 1 to 16384)?
1000
13、添加node作为slave
eshop-cache03
mkdir -p /var/redis/7008
port 7008
cluster-enabled yes
cluster-config-file /etc/redis-cluster/node-7008.conf
cluster-node-timeout 15000
daemonize yes
pidfile /var/run/redis_7008.pid
dir /var/redis/7008
logfile /var/log/redis/7008.log
bind 192.168.31.227
appendonly yes
redis-trib.rb add-node –slave –master-id 28927912ea0d59f6b790a50cf606602a5ee48108 192.168.31.227:7008 192.168.31.187:7001
14、删除node
先用resharding将数据都移除到其他节点,确保node为空之后,才能执行remove操作
redis-trib.rb del-node 192.168.31.187:7001 bd5a40a6ddccbd46a0f4a2208eb25d2453c2a8db
2个是1365,1个是1366
当你清空了一个master的hashslot时,redis cluster就会自动将其slave挂载到其他master上去
这个时候就只要删除掉master就可以了
15、slave的自动迁移
比如现在有10个master,每个有1个slave,然后新增了3个slave作为冗余,有的master就有2个slave了,有的master出现了salve冗余
如果某个master的slave挂了,那么redis cluster会自动迁移一个冗余的slave给那个master
只要多加一些冗余的slave就可以了
为了避免的场景,就是说,如果你每个master只有一个slave,万一说一个slave死了,然后很快,master也死了,那可用性还是降低了
但是如果你给整个集群挂载了一些冗余slave,那么某个master的slave死了,冗余的slave会被自动迁移过去,作为master的新slave,此时即使那个master也死了
还是有一个slave会切换成master的
之前有一个master是有冗余slave的,直接让其他master其中的一个slave死掉,然后看有冗余slave会不会自动挂载到那个master
16、节点间的内部通信机制
1、基础通信原理
(1)redis cluster节点间采取gossip协议进行通信
跟集中式不同,不是将集群元数据(节点信息,故障,等等)集中存储在某个节点上,而是互相之间不断通信,保持整个集群所有节点的数据是完整的
维护集群的元数据用得,集中式,一种叫做gossip
集中式:好处在于,元数据的更新和读取,时效性非常好,一旦元数据出现了变更,立即就更新到集中式的存储中,其他节点读取的时候立即就可以感知到; 不好在于,所有的元数据的跟新压力全部集中在一个地方,可能会导致元数据的存储有压力
集中式的集群元数据存储和维护

gossip协议维护集群元数据
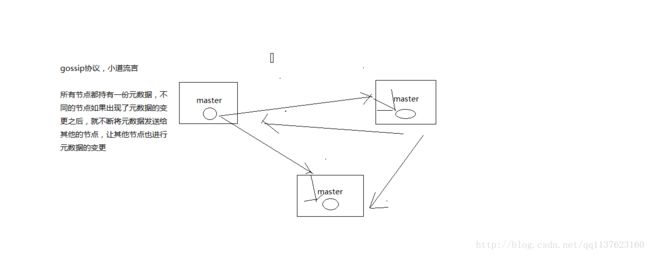
gossip:好处在于,元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续,打到所有节点上去更新,有一定的延时,降低了压力; 缺点,元数据更新有延时,可能导致集群的一些操作会有一些滞后
我们刚才做reshard,去做另外一个操作,会发现说,configuration error,达成一致
(2)10000端口
每个节点都有一个专门用于节点间通信的端口,就是自己提供服务的端口号+10000,比如7001,那么用于节点间通信的就是17001端口
每隔节点每隔一段时间都会往另外几个节点发送ping消息,同时其他几点接收到ping之后返回pong
(3)交换的信息
故障信息,节点的增加和移除,hash slot信息,等等
2、gossip协议
gossip协议包含多种消息,包括ping,pong,meet,fail,等等
meet: 某个节点发送meet给新加入的节点,让新节点加入集群中,然后新节点就会开始与其他节点进行通信
redis-trib.rb add-node
其实内部就是发送了一个gossip meet消息,给新加入的节点,通知那个节点去加入我们的集群
ping: 每个节点都会频繁给其他节点发送ping,其中包含自己的状态还有自己维护的集群元数据,互相通过ping交换元数据
每个节点每秒都会频繁发送ping给其他的集群,ping,频繁的互相之间交换数据,互相进行元数据的更新
pong: 返回ping和meet,包含自己的状态和其他信息,也可以用于信息广播和更新
fail: 某个节点判断另一个节点fail之后,就发送fail给其他节点,通知其他节点,指定的节点宕机了
3、ping消息深入
ping很频繁,而且要携带一些元数据,所以可能会加重网络负担
每个节点每秒会执行10次ping,每次会选择5个最久没有通信的其他节点
当然如果发现某个节点通信延时达到了cluster_node_timeout / 2,那么立即发送ping,避免数据交换延时过长,落后的时间太长了
比如说,两个节点之间都10分钟没有交换数据了,那么整个集群处于严重的元数据不一致的情况,就会有问题
所以cluster_node_timeout可以调节,如果调节比较大,那么会降低发送的频率
每次ping,一个是带上自己节点的信息,还有就是带上1/10其他节点的信息,发送出去,进行数据交换
至少包含3个其他节点的信息,最多包含总节点-2个其他节点的信息
17、redis在实际生产中出现的一些问题及处理方法
1、fork耗时导致高并发请求延时
RDB和AOF的时候,其实会有生成RDB快照,AOF rewrite,耗费磁盘IO的过程,主进程fork子进程
fork的时候,子进程是需要拷贝父进程的空间内存页表的,也是会耗费一定的时间的
一般来说,如果父进程内存有1个G的数据,那么fork可能会耗费在20ms左右,如果是10G~30G,那么就会耗费20 * 10,甚至20 * 30,也就是几百毫秒的时间
info stats中的latest_fork_usec,可以看到最近一次form的时长
redis单机QPS一般在几万,fork可能一下子就会拖慢几万条操作的请求时长,从几毫秒变成1秒
优化思路
fork耗时跟redis主进程的内存有关系,一般控制redis的内存在10GB以内,slave -> master,全量复制
2、AOF的阻塞问题
redis将数据写入AOF缓冲区,单独开一个现场做fsync操作,每秒一次
但是redis主线程会检查两次fsync的时间,如果距离上次fsync时间超过了2秒,那么写请求就会阻塞
everysec,最多丢失2秒的数据
一旦fsync超过2秒的延时,整个redis就被拖慢
优化思路
优化硬盘写入速度,建议采用SSD,不要用普通的机械硬盘,SSD,大幅度提升磁盘读写的速度
3、主从复制延迟问题
主从复制可能会超时严重,这个时候需要良好的监控和报警机制
在info replication中,可以看到master和slave复制的offset,做一个差值就可以看到对应的延迟量
如果延迟过多,那么就进行报警
4、主从复制风暴问题
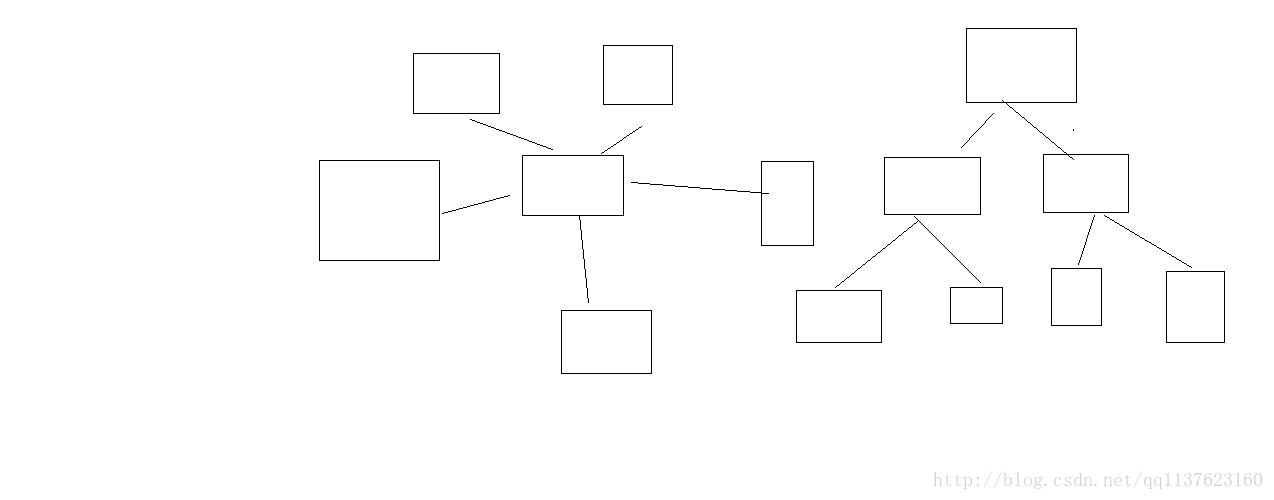
如果一下子让多个slave从master去执行全量复制,一份大的rdb同时发送到多个slave,会导致网络带宽被严重占用
如果一个master真的要挂载多个slave,那尽量用树状结构,不要用星型结构
避免复制风暴
5、vm.overcommit_memory
0: 检查有没有足够内存,没有的话申请内存失败
1: 允许使用内存直到用完为止
2: 内存地址空间不能超过swap + 50%
如果是0的话,可能导致类似fork等操作执行失败,申请不到足够的内存空间
cat /proc/sys/vm/overcommit_memory
echo “vm.overcommit_memory=1” >> /etc/sysctl.conf
sysctl vm.overcommit_memory=1
6、swapiness
cat /proc/version,查看linux内核版本
如果linux内核版本<3.5,那么swapiness设置为0,这样系统宁愿swap也不会oom killer(杀掉进程)
如果linux内核版本>=3.5,那么swapiness设置为1,这样系统宁愿swap也不会oom killer
保证redis不会被杀掉
echo 0 > /proc/sys/vm/swappiness
echo vm.swapiness=0 >> /etc/sysctl.conf
7、最大打开文件句柄
ulimit -n 10032 10032
自己去上网搜一下,不同的操作系统,版本,设置的方式都不太一样
8、tcp backlog
cat /proc/sys/net/core/somaxconn
echo 511 > /proc/sys/net/core/somaxconn
来自龙果学院讲师:中华石杉
hash算法 -> 一致性hash算法(memcached) -> redis cluster,hash slot算法
用不同的算法,就决定了在多个master节点的时候,数据如何分布到这些节点上去,解决这个问题
1、redis cluster介绍
redis cluster
(1)自动将数据进行分片,每个master上放一部分数据
(2)提供内置的高可用支持,部分master不可用时,还是可以继续工作的
在redis cluster架构下,每个redis要放开两个端口号,比如一个是6379,另外一个就是加10000的端口号,比如16379
16379端口号是用来进行节点间通信的,也就是cluster bus的东西,集群总线。cluster bus的通信,用来进行故障检测,配置更新,故障转移授权
cluster bus用了另外一种二进制的协议,主要用于节点间进行高效的数据交换,占用更少的网络带宽和处理时间
2、最老土的hash算法和弊端(大量缓存重建)
3、一致性hash算法(自动缓存迁移)+虚拟节点(自动负载均衡)
一致性hash算法的讲解和优点
一致性hash算法的虚拟节点实现负载均衡
4、redis cluster的hash slot算法
redis cluster有固定的16384个hash slot,对每个key计算CRC16值,然后对16384取模,可以获取key对应的hash slot
redis cluster中每个master都会持有部分slot,比如有3个master,那么可能每个master持有5000多个hash slot
hash slot让node的增加和移除很简单,增加一个master,就将其他master的hash slot移动部分过去,减少一个master,就将它的hash slot移动到其他master上去
移动hash slot的成本是非常低的
客户端的api,可以对指定的数据,让他们走同一个hash slot,通过hash tag来实现
5、redis cluster的重要配置
cluster-enabled
6、在三台机器上启动6个redis实例
(1)在eshop-cache03上部署目录
/etc/redis(存放redis的配置文件),/var/redis/6379(存放redis的持久化文件)
(2)编写配置文件
redis cluster集群,要求至少3个master,去组成一个高可用,健壮的分布式的集群,每个master都建议至少给一个slave,3个master,3个slave,最少的要求
正式环境下,建议都是说在6台机器上去搭建,至少3台机器
保证,每个master都跟自己的slave不在同一台机器上,如果是6台自然更好,一个master+一个slave就死了
3台机器去搭建6个redis实例的redis cluster
mkdir -p /etc/redis-cluster
mkdir -p /var/log/redis
mkdir -p /var/redis/7001
port 7001
cluster-enabled yes
cluster-config-file /etc/redis-cluster/node-7001.conf
cluster-node-timeout 15000
daemonize yes
pidfile /var/run/redis_7001.pid
dir /var/redis/7001
logfile /var/log/redis/7001.log
bind 192.168.31.187
appendonly yes
至少要用3个master节点启动,每个master加一个slave节点,先选择6个节点,启动6个实例
将上面的配置文件,在/etc/redis下放6个,分别为: 7001.conf,7002.conf,7003.conf,7004.conf,7005.conf,7006.conf
(3)准备生产环境的启动脚本
在/etc/init.d下,放6个启动脚本,分别为: redis_7001, redis_7002, redis_7003, redis_7004, redis_7005, redis_7006
每个启动脚本内,都修改对应的端口号
(4)分别在3台机器上,启动6个redis实例
将每个配置文件中的slaveof给删除
7、创建集群
注意:
也许你运行”gem install redis” 会报redis requires Ruby version >= 2.2.2
这是Centos默认支持ruby到2.0.0,可gem 安装redis需要最低是2.2.2
解决办法是 先安装rvm,再把ruby版本提升至2.3.3
具体解决方案:http://blog.csdn.net/qq1137623160/article/details/79178099
安装ruby
yum install -y ruby
yum install -y rubygems
gem install redis
cp /usr/local/redis-3.2.8/src/redis-trib.rb /usr/local/bin
redis-trib.rb create –replicas 1 192.168.0.118:7001 192.168.0.118:7002 192.168.0.119:7003 192.168.0.119:7004 192.168.0.120:7005 192.168.0.120:7006
–replicas: 每个master有几个slave
6台机器,3个master,3个slave,尽量自己让master和slave不在一台机器上
yes
redis-trib.rb check 192.168.31.187:7001
8、读写分离+高可用+多master
读写分离:每个master都有一个slave
高可用:master宕机,slave自动被切换过去
多master:横向扩容支持更大数据量
1、实验多master写入 -> 海量数据的分布式存储
你在redis cluster写入数据的时候,其实是你可以将请求发送到任意一个master上去执行
但是,每个master都会计算这个key对应的CRC16值,然后对16384个hashslot取模,找到key对应的hashslot,找到hashslot对应的master
如果对应的master就在自己本地的话,set mykey1 v1,mykey1这个key对应的hashslot就在自己本地,那么自己就处理掉了
但是如果计算出来的hashslot在其他master上,那么就会给客户端返回一个moved error,告诉你,你得到哪个master上去执行这条写入的命令
什么叫做多master的写入,就是每条数据只能存在于一个master上,不同的master负责存储不同的数据,分布式的数据存储
100w条数据,5个master,每个master就负责存储20w条数据,分布式数据存储
高并发、高性能、每日上亿流量,redis持久化 -> 灾难的时候,做数据恢复,复制 -> 读写分离,扩容slave,支撑更高的读吞吐,redis怎么支撑读QPS超过10万,几十万; 哨兵,在redis主从,一主多从,怎么保证99.99%可用性; redis cluster,海量数据
天下武功,都出自一脉,研究过各种大数据的系统,redis cluster讲解了很多原理,跟elasticsearch,很多底层的分布式原理,都是类似的
redis AOF,fsync
elasticsearch建立索引的时候,先写内存缓存,每秒钟把数据刷入os cache,接下来再每隔一定时间fsync到磁盘上去
redis cluster,写可以到任意master,任意master计算key的hashslot以后,告诉client,重定向,路由到其他mater去执行,分布式存储的一个经典的做法
elasticsearch,建立索引的时候,也会根据doc id/routing value,做路由,路由到某个其他节点,重定向到其他节点去执行
分布式的一些,hadoop,spark,storm里面很多核心的思想都是类似的
9、实验不同master各自的slave读取 -> 读写分离
在这个redis cluster中,如果你要在slave读取数据,那么需要带上readonly指令,get mykey1
redis-cli -c启动,就会自动进行各种底层的重定向的操作
实验redis cluster的读写分离的时候,会发现有一定的限制性,默认情况下,redis cluster的核心的理念,主要是用slave做高可用的,每个master挂一两个slave,主要是做数据的热备,还有master故障时的主备切换,实现高可用的
redis cluster默认是不支持slave节点读或者写的,跟我们手动基于replication搭建的主从架构不一样的
slave node,readonly,get,这个时候才能在slave node进行读取
redis cluster,主从架构是出来,读写分离,复杂了点,也可以做,jedis客户端,对redis cluster的读写分离支持不太好的
默认的话就是读和写都到master上去执行的
如果你要让最流行的jedis做redis cluster的读写分离的访问,那可能还得自己修改一点jedis的源码,成本比较高
要不然你就是自己基于jedis,封装一下,自己做一个redis cluster的读写分离的访问api
核心的思路,就是说,redis cluster的时候,就没有所谓的读写分离的概念了
读写分离,是为了什么,主要是因为要建立一主多从的架构,才能横向任意扩展slave node去支撑更大的读吞吐量
redis cluster的架构下,实际上本身master就是可以任意扩展的,你如果要支撑更大的读吞吐量,或者写吞吐量,或者数据量,都可以直接对master进行横向扩展就可以了
也可以实现支撑更高的读吞吐的效果
不会去跟大家直接讲解的,很多东西都要带着一些疑问,未知,实际经过一些实验和操作之后,让你体会的更加深刻一些
redis cluster,主从架构,读写分离,没说错,没有撒谎
redis cluster,不太好,server层面,jedis client层面,对master做扩容,所以说扩容master,跟之前扩容slave,效果是一样的
9、实验自动故障切换 -> 高可用性
redis-trib.rb check 192.168.31.187:7001
比如把master1,187:7001,杀掉,看看它对应的19:7004能不能自动切换成master,可以自动切换
切换成master后的19:7004,可以直接读取数据
再试着把187:7001给重新启动,恢复过来,自动作为slave挂载到了19:7004上面去
10、redis水平扩容
redis cluster模式下,不建议做物理的读写分离了
我们建议通过master的水平扩容,来横向扩展读写吞吐量,还有支撑更多的海量数据
redis单机,读吞吐是5w/s,写吞吐2w/s
扩展redis更多master,那么如果有5台master,不就读吞吐可以达到总量25/s QPS,写可以达到10w/s QPS
redis单机,内存,6G,8G,fork类操作的时候很耗时,会导致请求延时的问题
扩容到5台master,能支撑的总的缓存数据量就是30G,40G -> 100台,600G,800G,甚至1T+,海量数据
redis是怎么扩容的
11、加入新master
mkdir -p /var/redis/7007
port 7007
cluster-enabled yes
cluster-config-file /etc/redis-cluster/node-7007.conf
cluster-node-timeout 15000
daemonize yes
pidfile /var/run/redis_7007.pid
dir /var/redis/7007
logfile /var/log/redis/7007.log
bind 192.168.31.227
appendonly yes
搞一个7007.conf,再搞一个redis_7007启动脚本
手动启动一个新的redis实例,在7007端口上
redis-trib.rb add-node 192.168.31.227:7007 192.168.31.187:7001
redis-trib.rb check 192.168.31.187:7001
连接到新的redis实例上,cluster nodes,确认自己是否加入了集群,作为了一个新的master
12、reshard一些数据过去
resharding的意思就是把一部分hash slot从一些node上迁移到另外一些node上
redis-trib.rb reshard 192.168.31.187:7001
要把之前3个master上,总共4096个hashslot迁移到新的第四个master上去
How many slots do you want to move (from 1 to 16384)?
1000
13、添加node作为slave
eshop-cache03
mkdir -p /var/redis/7008
port 7008
cluster-enabled yes
cluster-config-file /etc/redis-cluster/node-7008.conf
cluster-node-timeout 15000
daemonize yes
pidfile /var/run/redis_7008.pid
dir /var/redis/7008
logfile /var/log/redis/7008.log
bind 192.168.31.227
appendonly yes
redis-trib.rb add-node –slave –master-id 28927912ea0d59f6b790a50cf606602a5ee48108 192.168.31.227:7008 192.168.31.187:7001
14、删除node
先用resharding将数据都移除到其他节点,确保node为空之后,才能执行remove操作
redis-trib.rb del-node 192.168.31.187:7001 bd5a40a6ddccbd46a0f4a2208eb25d2453c2a8db
2个是1365,1个是1366
当你清空了一个master的hashslot时,redis cluster就会自动将其slave挂载到其他master上去
这个时候就只要删除掉master就可以了
15、slave的自动迁移
比如现在有10个master,每个有1个slave,然后新增了3个slave作为冗余,有的master就有2个slave了,有的master出现了salve冗余
如果某个master的slave挂了,那么redis cluster会自动迁移一个冗余的slave给那个master
只要多加一些冗余的slave就可以了
为了避免的场景,就是说,如果你每个master只有一个slave,万一说一个slave死了,然后很快,master也死了,那可用性还是降低了
但是如果你给整个集群挂载了一些冗余slave,那么某个master的slave死了,冗余的slave会被自动迁移过去,作为master的新slave,此时即使那个master也死了
还是有一个slave会切换成master的
之前有一个master是有冗余slave的,直接让其他master其中的一个slave死掉,然后看有冗余slave会不会自动挂载到那个master
16、节点间的内部通信机制
1、基础通信原理
(1)redis cluster节点间采取gossip协议进行通信
跟集中式不同,不是将集群元数据(节点信息,故障,等等)集中存储在某个节点上,而是互相之间不断通信,保持整个集群所有节点的数据是完整的
维护集群的元数据用得,集中式,一种叫做gossip
集中式:好处在于,元数据的更新和读取,时效性非常好,一旦元数据出现了变更,立即就更新到集中式的存储中,其他节点读取的时候立即就可以感知到; 不好在于,所有的元数据的跟新压力全部集中在一个地方,可能会导致元数据的存储有压力
集中式的集群元数据存储和维护
gossip协议维护集群元数据
gossip:好处在于,元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续,打到所有节点上去更新,有一定的延时,降低了压力; 缺点,元数据更新有延时,可能导致集群的一些操作会有一些滞后
我们刚才做reshard,去做另外一个操作,会发现说,configuration error,达成一致
(2)10000端口
每个节点都有一个专门用于节点间通信的端口,就是自己提供服务的端口号+10000,比如7001,那么用于节点间通信的就是17001端口
每隔节点每隔一段时间都会往另外几个节点发送ping消息,同时其他几点接收到ping之后返回pong
(3)交换的信息
故障信息,节点的增加和移除,hash slot信息,等等
2、gossip协议
gossip协议包含多种消息,包括ping,pong,meet,fail,等等
meet: 某个节点发送meet给新加入的节点,让新节点加入集群中,然后新节点就会开始与其他节点进行通信
redis-trib.rb add-node
其实内部就是发送了一个gossip meet消息,给新加入的节点,通知那个节点去加入我们的集群
ping: 每个节点都会频繁给其他节点发送ping,其中包含自己的状态还有自己维护的集群元数据,互相通过ping交换元数据
每个节点每秒都会频繁发送ping给其他的集群,ping,频繁的互相之间交换数据,互相进行元数据的更新
pong: 返回ping和meet,包含自己的状态和其他信息,也可以用于信息广播和更新
fail: 某个节点判断另一个节点fail之后,就发送fail给其他节点,通知其他节点,指定的节点宕机了
3、ping消息深入
ping很频繁,而且要携带一些元数据,所以可能会加重网络负担
每个节点每秒会执行10次ping,每次会选择5个最久没有通信的其他节点
当然如果发现某个节点通信延时达到了cluster_node_timeout / 2,那么立即发送ping,避免数据交换延时过长,落后的时间太长了
比如说,两个节点之间都10分钟没有交换数据了,那么整个集群处于严重的元数据不一致的情况,就会有问题
所以cluster_node_timeout可以调节,如果调节比较大,那么会降低发送的频率
每次ping,一个是带上自己节点的信息,还有就是带上1/10其他节点的信息,发送出去,进行数据交换
至少包含3个其他节点的信息,最多包含总节点-2个其他节点的信息
17、redis在实际生产中出现的一些问题及处理方法
1、fork耗时导致高并发请求延时
RDB和AOF的时候,其实会有生成RDB快照,AOF rewrite,耗费磁盘IO的过程,主进程fork子进程
fork的时候,子进程是需要拷贝父进程的空间内存页表的,也是会耗费一定的时间的
一般来说,如果父进程内存有1个G的数据,那么fork可能会耗费在20ms左右,如果是10G~30G,那么就会耗费20 * 10,甚至20 * 30,也就是几百毫秒的时间
info stats中的latest_fork_usec,可以看到最近一次form的时长
redis单机QPS一般在几万,fork可能一下子就会拖慢几万条操作的请求时长,从几毫秒变成1秒
优化思路
fork耗时跟redis主进程的内存有关系,一般控制redis的内存在10GB以内,slave -> master,全量复制
2、AOF的阻塞问题
redis将数据写入AOF缓冲区,单独开一个现场做fsync操作,每秒一次
但是redis主线程会检查两次fsync的时间,如果距离上次fsync时间超过了2秒,那么写请求就会阻塞
everysec,最多丢失2秒的数据
一旦fsync超过2秒的延时,整个redis就被拖慢
优化思路
优化硬盘写入速度,建议采用SSD,不要用普通的机械硬盘,SSD,大幅度提升磁盘读写的速度
3、主从复制延迟问题
主从复制可能会超时严重,这个时候需要良好的监控和报警机制
在info replication中,可以看到master和slave复制的offset,做一个差值就可以看到对应的延迟量
如果延迟过多,那么就进行报警
4、主从复制风暴问题
如果一下子让多个slave从master去执行全量复制,一份大的rdb同时发送到多个slave,会导致网络带宽被严重占用
如果一个master真的要挂载多个slave,那尽量用树状结构,不要用星型结构
避免复制风暴
5、vm.overcommit_memory
0: 检查有没有足够内存,没有的话申请内存失败
1: 允许使用内存直到用完为止
2: 内存地址空间不能超过swap + 50%
如果是0的话,可能导致类似fork等操作执行失败,申请不到足够的内存空间
cat /proc/sys/vm/overcommit_memory
echo “vm.overcommit_memory=1” >> /etc/sysctl.conf
sysctl vm.overcommit_memory=1
6、swapiness
cat /proc/version,查看linux内核版本
如果linux内核版本<3.5,那么swapiness设置为0,这样系统宁愿swap也不会oom killer(杀掉进程)
如果linux内核版本>=3.5,那么swapiness设置为1,这样系统宁愿swap也不会oom killer
保证redis不会被杀掉
echo 0 > /proc/sys/vm/swappiness
echo vm.swapiness=0 >> /etc/sysctl.conf
7、最大打开文件句柄
ulimit -n 10032 10032
自己去上网搜一下,不同的操作系统,版本,设置的方式都不太一样
8、tcp backlog
cat /proc/sys/net/core/somaxconn
echo 511 > /proc/sys/net/core/somaxconn
来自龙果学院讲师:中华石杉