-01-RGB彩色图像转换为灰度图像【ARM NEON加速】
1. NEON简介
NEON官方的简介网址:NEON
NEON的主要特点就是single instruction, multiple data(SIMD),拥有专用的ALU和寄存器(d0-d32,q0-q16),基于这种结构很容易实现数据的并行计算,尤其是数学中的向量计算、音频中双声道数据处理、图像中RGB或RGBA彩色图像处理。
SIMD的运行方式如下图:
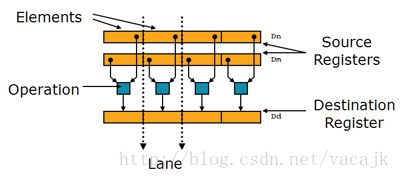
2. NEON加速实例,RGB2GRAY
参考文档:
1. ARM NEON Optimization. An Example
2. Android平台-彩色RGB图像灰度化-neon优化实例解析
从摄像头或图片中读取到的图像通常为彩色的,在进行处理之前需要将其转换为灰度图像。也就是Matlab,OpenCV中常用到的rgb2gray函数。
在计算机显示中彩色图像一般由RGB三色组成,若要将其转换为灰度图像,各通道颜色因为人眼的原因,权值有所不同,公式为:
Gray = R*0.299 + G*0.587 + B*0.114
而在计算机中为了加快运算速度,可以将上面的公式转化为整数运算,公式为:
Gray = (R * 77 + G * 151 + B * 28 ) / 256
用C语言来实现灰度转换的代码如下:
void reference_convert (uint8_t * __restrict dest, uint8_t * __restrict src, int n)
{
int i;
for (i=0; iint r = *src++; // load red
int g = *src++; // load green
int b = *src++; // load blue
// build weighted average:
int y = (r*77)+(g*151)+(b*28);
// undo the scale by 256 and write to memory:
*dest++ = (y>>8);
}
} 接下来就参照参考文档1里面的设计对这个函数进NEON代码的编写。大家可以自己去看一遍。
参考文档首先参照C代码的方式,使用编译器内联函数(compiler intrinsics)在C语言中调用了NEON指令,实现了运算加速。接着又参考了编译器生成的汇编代码,直接编写了NEON代码。最终,彩色转灰度运算实现了NEON加速,运算周期是直接使用C语言生成的7.5倍。下面是三种方式分别实现后,每个像素需要处理的指令周期。
C-version: 15.1 cycles per pixel.
NEON-version: 9.9 cycles per pixel.
Assembler: 2.0 cycles per pixel.该例子中NEON的加速是还没有针对A8处理器中的dual-issue特性进行特别的优化、没有使用数据预加载指令的效果,可见NEON的并行运算加速功能还是很强的。例子最后的汇编代码如下:
convert_asm_neon:
# r0: Ptr to destination data
# r1: Ptr to source data
# r2: Iteration count:
push {r4-r5,lr}
lsr r2, r2, #3
# build the three constants:
mov r3, #77
mov r4, #151
mov r5, #28
vdup.8 d3, r3
vdup.8 d4, r4
vdup.8 d5, r5
.loop:
# load 8 pixels:
vld3.8 {d0-d2}, [r1]!
# do the weight average:
vmull.u8 q3, d0, d3
vmlal.u8 q3, d1, d4
vmlal.u8 q3, d2, d5
# shift and store:
vshrn.u16 d6, q3, #8
vst1.8 {d6}, [r0]!
subs r2, r2, #1
bne .loop
pop { r4-r5, pc }与C语言中一次处理一个像素的方式不同,汇编代码中是一次进行8个像素点的灰度计算的。汇编代码中的循环,一次性从内存中读取8个像素点的RGB值共24个字节(vld3.8),进行了1次乘法运算(vmull)、2次乘加运算(vmlal)以及1次移位运算(vshrn)得到8个像素点的灰度值,并最终存储到连续的8字节内存当中(vst1.8)。
这中间的乘法、乘加、移位运算都是以向量方式并行运算的,一次能处理8个像素的数据。这也就是NEON能够实现程序加速的关键所在。
在前面也提到例子中的汇编代码还是有可以优化的空间的,主要包含两个方面:dual-issue和预加载。
ARM汇编指南文档中包含了所有的NEON汇编指令格式及用法。
dual-issue在neon_tutorial 这个ppt里面有说明,优化的基本原理就是连续两条NEON汇编指令中,第一条指令目的操作数得到结果的指令周期与第二条指令的源操作数的准备周期相近或相同,就能够提高指令、数据处理的并行性。每个NEON汇编指令具体的指令周期需要查看文档(针对A9芯片) DDI0409G_cortex_a9_neon_mpe_r3p0_trm](http://101.96.8.165/infocenter.arm.com/help/topic/com.arm.doc.ddi0409g/DDI0409G_cortex_a9_neon_mpe_r3p0_trm.pdf)。
如PPT中的标记出了VEXT和VMLA的指令延时,VEXT得目的操作数结果延时为2,VMLA的源操作数准备延时为2,所以这两个指令可以配对使用形成dual-issue。

当然,你的汇编代码中需要同时包含这两个指令才能形成配对,而且在指令调整顺序时不能够影响计算结果才行。pld预加载。前一篇转载的文档也正是由于用到了PLD指令,在运算循环中提前加载了下一次循环中需要用到的数据到缓存,才实现了很大程度上的数据处理加速。因此,在汇编循环代码中的合适位置增加PLD指令,能够大大提高缓存命中率,提高程序代码的处理速度的。
3. RGB2GRAY的NEON加速优化
虽然前面说到了dual-issue的优化可能性,但是在RGB2GRAY代码中,循环中的处理的指令仅仅有乘、乘加、移位几条指令,并不能够达成dual-issue优化的目的,所以在此不进行优化。
而PLD指令的预加载可以针对r1寄存器进行提前加载,提高缓存命中率。
汇编指令格式为:
pld [r1, #24]
pld [r1, #48]至于具体的预加载偏移,我还没有详细测试。但是可以肯定的一点是加入PLD指令后,每像素的灰度化指令周期一定会更低。