优化算法 - 牛顿法 and 拟牛顿法
优化算法 - 牛顿法 and 拟牛顿法
- 预备知识
- 无约束优化问题
- Hesse 矩阵
- 泰勒展开式
- 牛顿法
- 形象化解释
- 公式化解释
- 算法过程
- 拟牛顿法
- 拟牛顿条件
- DFP (Davidon-Fletcher-Powell)
- 算法推导
- 算法过程
- BFGS (Broyden-Fletcher-Goldfarb-Shanno)
- 总结
预备知识
-
无约束优化问题
我们以前聊过约束优化方法,将带有约束的优化问题(例如 SVM 中间隔的间隔要大于 1)通过 拉格朗日乘子法转化为凸优化问题,再对各参数求偏导从而求的最优解。
那么对于无约束的优化问题呢?我们通常使用跟梯度有关的算法。例如 梯度下降法,在 Logistic回归 中以及神经网络中都有应用。而关于梯度的无约束优化算法还有牛顿法系列。
在介绍牛顿法前我们先来了解两个基础知识,Hesse 矩阵以及 泰勒展开式。
-
Hesse 矩阵
简单来说,Hesse 矩阵就是某一矩阵对于其中各元素的偏导(二阶)。
例如有矩阵: A = [ x 1 x 1 x 1 x 2 x 2 x 1 x 2 x 2 ] A=\begin{bmatrix} x_1x_1 & x_1x_2\\ x_2x_1 & x_2x_2\\ \end{bmatrix} A=[x1x1x2x1x1x2x2x2]
则, H ( x ) = [ ∂ 2 f ∂ x 1 2 ∂ 2 f ∂ x 1 ∂ x 2 ∂ 2 f ∂ x 2 ∂ x 1 ∂ 2 f ∂ x 2 2 ] H(x)=\begin{bmatrix} \frac{\partial^2 f}{\partial x_1^2} & \frac{\partial^2 f}{\partial x_1 \partial x_2} \\ \frac{\partial^2 f}{\partial x_2 \partial x_1} & \frac{\partial^2 f}{\partial x_2^2} \\ \end{bmatrix} H(x)=[∂x12∂2f∂x2∂x1∂2f∂x1∂x2∂2f∂x22∂2f]
Hesse矩阵的通用表达式为: H ( x ) = [ ∂ 2 f ∂ x i ∂ x j ] n ∗ n H(x)=[\frac{\partial^2 f}{\partial x_i \partial x_j}]_{n*n} H(x)=[∂xi∂xj∂2f]n∗n
-
泰勒展开式
高数中的经典公式,将一个函数,在某一点处,利用各阶导数计算原函数值。这里以二阶展开举例,省略高阶无穷小的余项。
将 f ( x ) f(x) f(x) 在 x0 处的二阶展开:
f ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) + 1 2 f ′ ′ ( x 0 ) ( x − x 0 ) 2 f(x)=f(x_0)+f'(x_0)(x-x_0)+\frac{1}{2}f''(x_0)(x-x_0)^2 f(x)=f(x0)+f′(x0)(x−x0)+21f′′(x0)(x−x0)2
对于 x 为矩阵来讲,令 g ( x ) g(x) g(x) 表示一阶导, H ( x ) H(x) H(x) 表示二阶导:
f ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) + 1 2 f ′ ′ ( x 0 ) ( x − x 0 ) 2 = f ( x 0 ) + g T ( x 0 ) ( x − x 0 ) + 1 2 ( x − x 0 ) T H ( x 0 ) ( x − x 0 ) \begin{aligned}f(x)=&f(x_0)+f'(x_0)(x-x_0)+\frac{1}{2}f''(x_0)(x-x_0)^2\\ =&f(x_0)+g^T(x_0)(x-x_0)+\frac{1}{2}(x-x_0)^TH(x_0)(x-x_0) \end{aligned} f(x)==f(x0)+f′(x0)(x−x0)+21f′′(x0)(x−x0)2f(x0)+gT(x0)(x−x0)+21(x−x0)TH(x0)(x−x0)
牛顿法
接下来进入正题,对于无约束优化问题来讲,无法直接求解,所以需要类似梯度下降一样一步一步的迭代。牛顿法也同样基于这个理念。
-
形象化解释
首先来看一个形象化的解释:
∙ \bullet ∙ 目标:求 f ( x ) = 0 f(x)=0 f(x)=0 的解 x ∗ x^* x∗
∙ \bullet ∙ 初始选择一个接近函数 f ( x ) f(x) f(x) 零点的 x 0 x_0 x0,计算相应的 f ( x 0 ) f(x_0) f(x0) 和切线斜率 f ′ ( x 0 ) f'(x_0) f′(x0)。
∙ \bullet ∙ 利用“两点式”计算经过点 ( x 0 , f ( x 0 ) ) (x_0, f(x_0)) (x0,f(x0)) 且斜率为 f ′ ( x 0 ) f'(x_0) f′(x0) 的直线,与 x x x 轴的交点 ( x 1 , 0 ) (x_1,0) (x1,0).
f ′ ( x 0 ) = f ( x 0 ) − f ( x 1 ) x 0 − x 1 = f ( x 0 ) x 0 − x 1 f'(x_0)=\frac{f(x_0)-f(x_1)}{x_0-x_1}=\frac{f(x_0)}{x_0-x_1} f′(x0)=x0−x1f(x0)−f(x1)=x0−x1f(x0)
x 1 = x 0 − f ( x 0 ) f ′ ( x 0 ) x_1=x_0-\frac{f(x_0)}{f'(x_0)} x1=x0−f′(x0)f(x0), x 1 x_1 x1 则为下一次迭代的点,
牛顿法又称为切线法,如图所示:
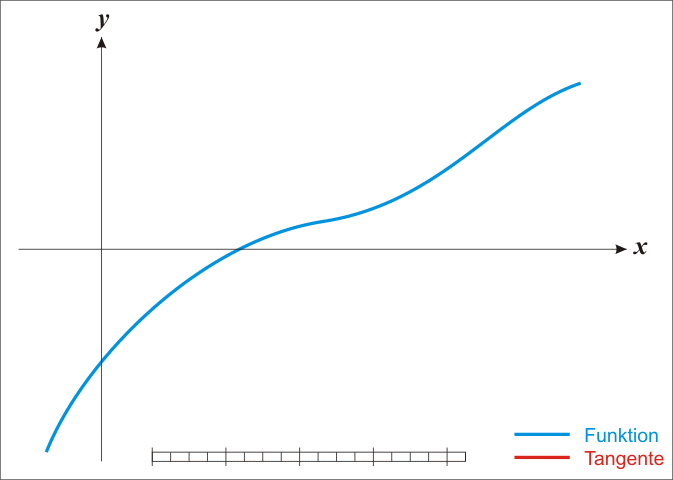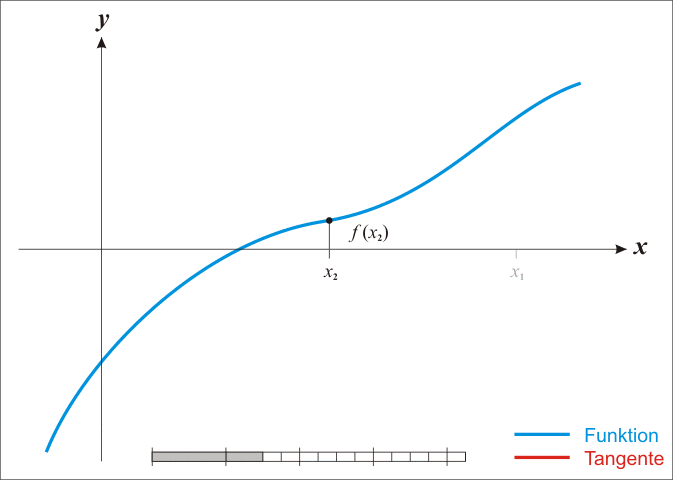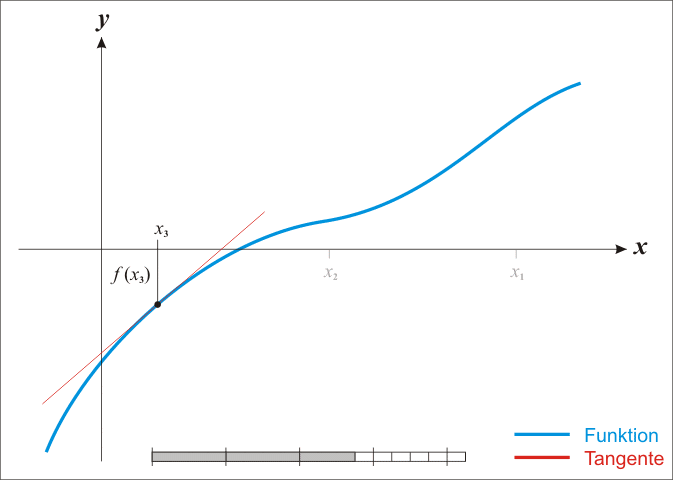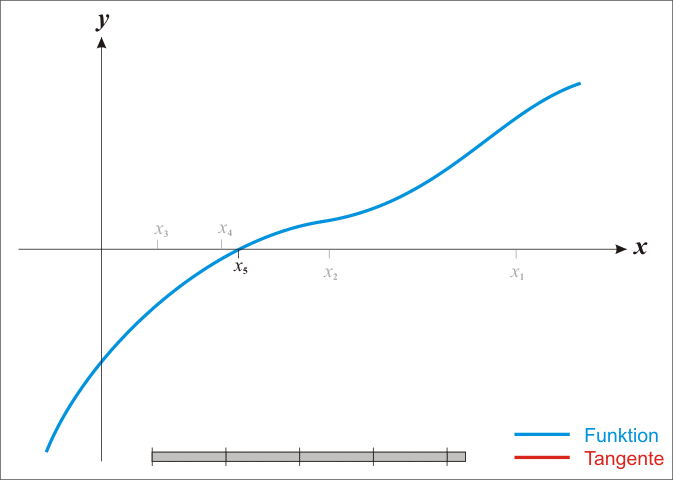
(图片来自 https://www.cnblogs.com/shixiangwan/p/7532830.html)以上步骤是求解能使 f ( x ) = 0 f(x)=0 f(x)=0 时的解 x ∗ x^* x∗,但我们现在要求的是能使 f ′ ( x ) = 0 f'(x)=0 f′(x)=0 的解,所以,我们的目标变为:
f ′ ′ ( x 0 ) = f ′ ( x 0 ) − f ′ ( x 1 ) x 0 − x 1 f''(x_0)=\frac{f'(x_0)-f'(x_1)}{x_0-x_1} f′′(x0)=x0−x1f′(x0)−f′(x1)
得到:
x 1 = x 0 − f ′ ( x 0 ) f ′ ′ ( x 0 ) ⟹ k x k + 1 = x k − f ′ ( x k ) f ′ ′ ( x k ) x_1=x_0-\frac{f'(x_0)}{f''(x_0)} \mathop{}_{\Longrightarrow}^{~~k}x_{k+1}=x_k-\frac{f'(x_k)}{f''(x_k)} x1=x0−f′′(x0)f′(x0)⟹ kxk+1=xk−f′′(xk)f′(xk)
这便是我们牛顿法的迭代更新过程。
-
公式化解释
对于函数 g ( x ) g(x) g(x),其导数 H ( x ) H(x) H(x),对 g ( x ) g(x) g(x) 在点 x k x_k xk 出使用泰勒二阶展开,得:
g ( x ) = g ( x k ) + H ( x k ) ( x − x k ) g(x)=g(x_k)+H(x_k)(x-x_k) g(x)=g(xk)+H(xk)(x−xk)
令 x = x k + 1 , g k = g ( x k ) , H k = H ( x k ) x=x_{k+1},g_k=g(x_k),H_k=H(x_k) x=xk+1,gk=g(xk),Hk=H(xk),则更新迭代公式为:
x k + 1 = x k + H k − 1 ( g k + 1 − g k ) x_{k+1}=x_k+H_k^{-1}(g_{k+1}-g_k) xk+1=xk+Hk−1(gk+1−gk)
( g k + 1 = 0 时 则 与 之 前 所 推 等 价 g_{k+1}=0~时则与之前所推等价 gk+1=0 时则与之前所推等价)
-
算法过程
- 确 定 精 度 要 求 ε , 初 始 化 x 0 , 置 k = 0 确定精度要求 ε,初始化 x_0,置k=0 确定精度要求ε,初始化x0,置k=0
- 计 算 g k = g ( x k ) , 若 ∣ ∣ g ( x k ) ∣ ∣ ≤ ε 则 停 止 计 算 , 求 得 近 似 解 x ∗ = x k ; 否 则 转 第 3 步 计算 g_k=g(x_k),若||g(x_k)||\leε 则停止计算,求得近似解 x^*=x_k;否则转第~3~步 计算gk=g(xk),若∣∣g(xk)∣∣≤ε则停止计算,求得近似解x∗=xk;否则转第 3 步
- 计 算 H k = H ( x k ) , 以 及 其 逆 矩 阵 H k − 1 计算 H_k=H(x_k),以及其逆矩阵 H_k^{-1} 计算Hk=H(xk),以及其逆矩阵Hk−1
- 计 算 x k + 1 = x k − H k − 1 g k , 令 k = k + 1 , 转 第 2 步 计算 x_{k+1}=x_k-H_k^{-1}g_k,令k=k+1,转第~2~步 计算xk+1=xk−Hk−1gk,令k=k+1,转第 2 步
我们可以看到,在迭代过程中,需要求 H k 的 逆 矩 阵 H k − 1 H_k的逆矩阵 H_k^{-1} Hk的逆矩阵Hk−1,这个计算比较复杂,效率很低,所以就产生了拟牛顿法。
拟牛顿法
拟牛顿法的思想是与牛顿法一样的,但由于求逆矩阵复杂,多以拟牛顿法寻找一个矩阵用来近似替代 H k − 1 H_k^{-1} Hk−1
-
拟牛顿条件
想找替代矩阵可不是随便找的,需要满足一个条件(两点式),即:
x k + 1 − x k = H k − 1 ( g k + 1 − g k ) x_{k+1}-x_k=H_k^{-1}(g_{k+1}-g_k) xk+1−xk=Hk−1(gk+1−gk)
此条件被称为“拟牛顿条件”。
拟牛顿法则是使用 G k G_k Gk 作为 H k − 1 H_k^{-1} Hk−1 的近似,要求 G k G_k Gk 为正定矩阵,且满足拟牛顿条件。根据拟牛顿条件的不同,选取的正定矩阵也不一样:
如果选择 G k G_k Gk 作为 H k − 1 H_k^{-1} Hk−1 的近似,就成为 DFP 算法;
如果选择 B k B_k Bk 作为 H k H_k Hk 的近似,就成为 BFGS 算法。按照拟牛顿条件,在每次迭代中可以选择更新替代矩阵,用以近似 H k − 1 或 H k H_k^{-1}或H_k Hk−1或Hk:
G k + 1 = G k + Δ G k G_{k+1}=G_k+ΔG_k Gk+1=Gk+ΔGk
为什么要求 G k 或 B k G_k或B_k Gk或Bk 为正定矩阵呢?那是因为只有它们为正定矩阵时,x 的搜索方向才是 f ( x ) f(x) f(x) 下降的方向。
具体的,根据迭代更新公式: x k + 1 = x k − H k − 1 g k x_{k+1}=x_k-H_k^{-1}g_k xk+1=xk−Hk−1gk,
引入步长因子 λ λ λ,定义 p k = − H k − 1 g k p_k=-H_k^{-1}g_k pk=−Hk−1gk
迭代更新公式变为: x k + 1 = x k − λ P k x_{k+1}=x_k-λP_k xk+1=xk−λPk
f ( x k + 1 ) f(x_{k+1}) f(xk+1) 在 x k x_k xk 处的泰勒一阶展开: f ( x k + 1 ) = f ( x k ) + g k T ( x k + 1 − x k ) f(x_{k+1})=f(x_k)+g_k^T(x_{k+1}-x_k) f(xk+1)=f(xk)+gkT(xk+1−xk)
将迭代更新公式代入,得:
f ( x k + 1 ) = f ( x k ) − λ g k T H k − 1 g k f(x_{k+1})=f(x_k)-λg_k^TH_k^{-1}g_k f(xk+1)=f(xk)−λgkTHk−1gk
因为 H k H_k Hk 是正定的( H k − 1 H_k^{-1} Hk−1 也是正定的),所以有 g k T H k − 1 g k > 0 g_k^TH_k^{-1}g_k>0 gkTHk−1gk>0,当 λ λ λ 为充分小的正数时,总有 f ( x k + 1 ) < f ( x k ) f(x_{k+1})<f(x_k) f(xk+1)<f(xk),就意味着 f ( x ) f(x) f(x) 在迭代中逐步逼近最小值,也就是说 p k p_k pk 的方向是函数下降方向。
(原牛顿法中没有步长因子 λ λ λ 的存在,当 G k 或 B k G_k或B_k Gk或Bk 为奇异矩阵时可能会出现数值问题,即出现 f ( x k + 1 ) > f ( x k ) f(x_{k+1})>f(x_k) f(xk+1)>f(xk) 的情况。此时目标函数值并没有稳定下降,而且有可能无法收敛。)
-
DFP (Davidon-Fletcher-Powell)
-
算法推导
DFP 算法选择 G k G_k Gk 作为 H k − 1 H_k^{-1} Hk−1 的近似,假设每一步迭代中矩阵 G k + 1 G_{k+1} Gk+1 是由 G k G_k Gk 加上两个附加矩阵构成的,即:
G k + 1 = G k + P k + Q k G_{k+1}=G_k+P_k+Q_k Gk+1=Gk+Pk+Qk,其中 P k , Q k P_k,Q_k Pk,Qk 为待定矩阵,令 y k = g k + 1 − g k y_k=g_{k+1}-g_k yk=gk+1−gk, δ k = x k + 1 − x k δ_k=x_{k+1}-x_k δk=xk+1−xk
这时 , G k + 1 y k = G k y k + P k + Q k y k G_{k+1}y_k=G_ky_k+P_k+Q_ky_k Gk+1yk=Gkyk+Pk+Qkyk
为使 G k + 1 G_{k+1} Gk+1 满足拟牛顿条件,可使 P k , Q k P_k,Q_k Pk,Qk 满足:
P k y k = δ k P_ky_k=δ_k Pkyk=δk,可以找到 P k = δ k δ k T δ k T y k P_k=\frac{δ_kδ_k^T}{δ_k^Ty_k} Pk=δkTykδkδkT
Q k y k = − G k y k Q_ky_k=-G_ky_k Qkyk=−Gkyk,可以找到 Q k = − G k y k y k T G k y k T G k y k Q_k=-\frac{G_ky_ky_k^TG_k}{y_k^TG_ky_k} Qk=−ykTGkykGkykykTGk
由以上得到矩阵 G k + 1 G_{k+1} Gk+1 的迭代公式:
G k + 1 = G k + δ k δ k T δ k T y k − G k y k y k T G k y k T G k y k G_{k+1}=G_k+\frac{δ_kδ_k^T}{δ_k^Ty_k}-\frac{G_ky_ky_k^TG_k}{y_k^TG_ky_k} Gk+1=Gk+δkTykδkδkT−ykTGkykGkykykTGk (公式 G)
可以证明,如果初始矩阵 G 0 G_0 G0 是正定的,则迭代过程中的每个矩阵 G k G_k Gk 都是正定的。
-
算法过程
- 确 定 精 度 要 求 ε , 初 始 化 x 0 、 G 0 为 正 定 对 称 矩 阵 , 置 k = 0 确定精度要求 ε,初始化 x_0、G_0为正定对称矩阵,置k=0 确定精度要求ε,初始化x0、G0为正定对称矩阵,置k=0
- 计 算 g k = g ( x k ) , 若 ∣ ∣ g ( x k ) ∣ ∣ ≤ ε 则 停 止 计 算 , 求 得 近 似 解 x ∗ = x k ; 否 则 转 第 3 步 计算 g_k=g(x_k),若||g(x_k)||\leε 则停止计算,求得近似解 x^*=x_k;否则转第~3~步 计算gk=g(xk),若∣∣g(xk)∣∣≤ε则停止计算,求得近似解x∗=xk;否则转第 3 步
- 计 算 p k = G k g k 计算 p_k=G_kg_k 计算pk=Gkgk
- 一 维 搜 索 : λ k = λ ≥ 0 a r g m i n f ( x k + λ p k ) 一维搜索:λ_k=\mathop{}_{~~~λ\ge0}^{argmin}f(x_k+λp_k) 一维搜索:λk= λ≥0argminf(xk+λpk)
- 计 算 x k + 1 = x k + λ k p k 计算 x_{k+1}=x_k+λ_kp_k 计算xk+1=xk+λkpk
- 计 算 g k + 1 = g ( x k + 1 ) , 若 ∣ ∣ g ( x k ) ∣ ∣ ≤ ε 则 停 止 计 算 , 求 得 近 似 解 x ∗ = x k ; 否 则 , 按 ( 公 式 G ) 计 算 G k + 1 , 置 k = k + 1 计算g_{k+1}=g(x_{k+1}),若||g(x_k)||\leε 则停止计算,求得近似解 x^*=x_k;否则,按(公式G)计算 G_{k+1},置 k=k+1 计算gk+1=g(xk+1),若∣∣g(xk)∣∣≤ε则停止计算,求得近似解x∗=xk;否则,按(公式G)计算Gk+1,置k=k+1
-
-
BFGS (Broyden-Fletcher-Goldfarb-Shanno)
BFGS 与 DFP 类似,不同的是选取的替代矩阵不同:
B k + 1 = B k + y k δ y T y k T δ k − B k δ k δ k T B k δ k T B k δ k B_{k+1}=B_k+\frac{y_kδ_y^T}{y_k^Tδ_k}-\frac{B_kδ_kδ_k^TB_k}{δ_k^TB_kδ_k} Bk+1=Bk+ykTδkykδyT−δkTBkδkBkδkδkTBk
总结
对于牛顿法与拟牛顿法的计算过程的区别:
-
牛顿法:
通过泰勒展开式近似原函数,每次迭代以计算 Hesse 的逆矩阵为核心,从而逼近 原函数的最小值。
-
拟牛顿法:
通过初始化 ( G 0 或 B 0 ) (G_0或B_0) (G0或B0) ,一维搜索 λ k λ_k λk,以及替代矩阵 ( G k + 1 或 B k + 1 ) (G_{k+1}或B_{k+1}) (Gk+1或Bk+1)的迭代计算,代替了 Hesse 逆矩阵的计算。
从本质上去看,牛顿法是二阶收敛,梯度下降是一阶收敛,所以牛顿法的收敛速度更快。更通俗地说,如果想找一条最短的路径走到一个山的最底部,梯度下降法每次只从当前所处位置选一个坡度最大的方向走一步,而牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑在走了一步之后,坡度是否会变得更大。所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部。(牛顿法目光更加长远,所以少走弯路;相对而言,梯度下降法只考虑了局部的最优,没有全局思想。)