机器学习算法(二十):孤立森林 iForest (Isolation Forest)
目录
1 背景
2 算法
2.1 定义
2.2 算法介绍
2.3 示例
3 特点
1 背景
现有的异常检测方法主要是通过对正常样本的描述,给出一个正常样本在特征空间中的区域,对于不在这个区域中的样本,视为异常。这些方法的主要缺点是,异常检测器只会对正常样本的描述做优化,而不会对异常样本的描述做优化,这样就有可能造成大量的误报,或者只检测到少量的异常。
异常的两个特点:异常数据只占很少量、异常数据特征值和正常数据差别很大。
孤立森林,不再是描述正常的样本点,而是要孤立异常点,由周志华教授等人于2008年在第八届IEEE数据挖掘国际会议上提出,之后又于2012年提出了改进版本。
先了解一下该算法的动机。目前学术界对异常(anomaly detection)的定义有很多种,在孤立森林(iForest)中,异常被定义为“容易被孤立的离群点 (more likely to be separated)”,可以将其理解为分布稀疏且离密度高的群体较远的点。 在特征空间里,分布稀疏的区域表示事件发生在该区域的概率很低,因而可以认为落在这些区域里的数据是异常的。孤立森林是一种适用于连续数据(Continuous numerical data)的无监督异常检测方法,即不需要有标记的样本来训练,但特征需要是连续的。对于如何查找哪些点容易被孤立(isolated),iForest使用了一套非常高效的策略。在孤立森林中,递归地随机分割数据集,直到所有的样本点都是孤立的。在这种随机分割的策略下,异常点通常具有较短的路径。
具体来说,该算法利用一种名为孤立树![]() 的二叉搜索树结构来孤立样本。由于异常值的数量较少且与大部分样本的疏离性,因此,异常值会被更早的孤立出来,也即异常值会距离
的二叉搜索树结构来孤立样本。由于异常值的数量较少且与大部分样本的疏离性,因此,异常值会被更早的孤立出来,也即异常值会距离![]() 的根节点更近,而正常值则会距离根节点有更远的距离。此外,相较于LOF,K-means等传统算法,孤立森林算法对高纬数据有较好的鲁棒性。
的根节点更近,而正常值则会距离根节点有更远的距离。此外,相较于LOF,K-means等传统算法,孤立森林算法对高纬数据有较好的鲁棒性。
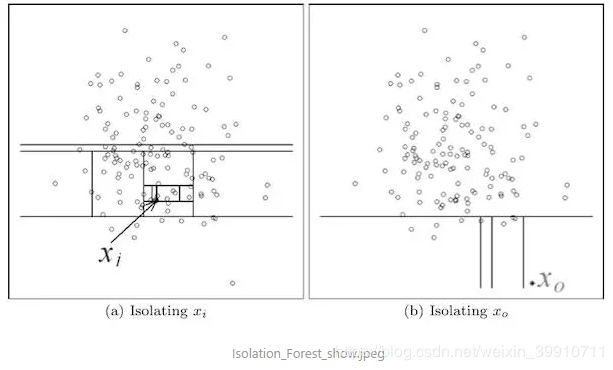
从下图我们可以直观的看到,相对更异常的![]() 只需要4次切割就从整体中被分离出来,而更加正常的点
只需要4次切割就从整体中被分离出来,而更加正常的点![]() 经过了11次分割才从整体中分离出来。这也体现了孤立森林算法的基本思想。
经过了11次分割才从整体中分离出来。这也体现了孤立森林算法的基本思想。
2 算法
2.1 定义
我们先给出孤立树(Isolation Tree)和样本点![]() 在孤立树中的路径长度
在孤立树中的路径长度![]() 的定义。
的定义。
孤立树:若为孤立树![]() 的一个节点,
的一个节点,![]() 存在两种情况:没有子节点的外部节点,有两个子节点
存在两种情况:没有子节点的外部节点,有两个子节点![]() 和一个test的内部节点。在
和一个test的内部节点。在![]() 的test由一个属性 q 和一个分割点 p 组成,
的test由一个属性 q 和一个分割点 p 组成,![]() 的点属于
的点属于![]() ,反之属于
,反之属于![]() 。
。
样本点![]() 在孤立树中的路径长度
在孤立树中的路径长度![]() :样本点
:样本点![]() 从
从![]() 的根节点到叶子节点经过的边的数量。
的根节点到叶子节点经过的边的数量。
2.2 算法介绍
下面,我们来详细介绍孤立森林算法。该算法大致可以分为两个阶段,第一个阶段我们需要训练出![]() 颗孤立树,组成孤立森林。随后我们将每个样本点带入森林中的每棵孤立树,计算平均高度,之后再计算每个样本点的异常值分数。
颗孤立树,组成孤立森林。随后我们将每个样本点带入森林中的每棵孤立树,计算平均高度,之后再计算每个样本点的异常值分数。
(1)第一阶段
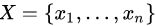 为给定数据集,
为给定数据集,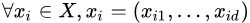 ,从
,从 中随机抽取
中随机抽取 个样本点构成的子集
个样本点构成的子集 放入根节点。
放入根节点。- 从 d 个维度中随机指定一个维度 q,在当前数据中随机产生一个切割点 p,
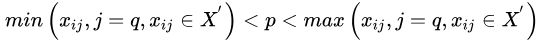 。
。 - 此切割点 p 生成了一个超平面,将当前数据空间划分为两个子空间:指定维度小于 p 的样本点放入左子节点,大于或等于 p 的放入右子节点。
- 递归Step2和Step3,直至所有的叶子节点都只有一个样本点或者孤立树
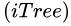 已经达到指定的高度。
已经达到指定的高度。 - 循环Step1至Step4,直至生成个孤立树
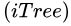 。
。
(2)第二阶段
Step1: 对于每一个数据点 ![]() ,令其遍历每一颗孤立树
,令其遍历每一颗孤立树![]() ,计算点
,计算点![]() 在森林中的平均高度
在森林中的平均高度 ![]() ,对所有点的平均高度做归一化处理。异常值分数的计算公式如下所示:
,对所有点的平均高度做归一化处理。异常值分数的计算公式如下所示:
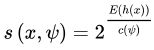
其中,
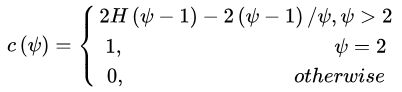
4个测试样本遍历一棵iTree的例子如下:
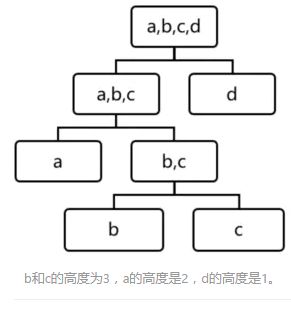
可以看到d最有可能是异常,因为其最早就被孤立(isolated)了。
2.3 示例
from sklearn.ensemble import IsolationForest
from scipy import stats
rng = np.random.RandomState(42)
X_train = data[:10000,:]
X_test = data
clf = IsolationForest(max_samples=256,random_state=rng)
clf.fit(X_train)
y_pred_test = clf.predict(X_test)3 特点
1. iForest具有线性时间复杂度。因为是ensemble的方法,所以可以用在含有海量数据的数据集上面。通常树的数量越多,算法越稳定。由于每棵树都是互相独立生成的,因此可以部署在大规模分布式系统上来加速运算。
2. iForest不适用于特别高维的数据。由于每次切数据空间都是随机选取一个维度,建完树后仍然有大量的维度信息没有被使用,导致算法可靠性降低。高维空间还可能存在大量噪音维度或无关维度(irrelevant attributes),影响树的构建。对这类数据,建议使用子空间异常检测(Subspace Anomaly Detection)技术。此外,切割平面默认是axis-parallel的,也可以随机生成各种角度的切割平面,详见“On Detecting Clustered Anomalies Using SCiForest”。
3. iForest仅对Global Anomaly 敏感,即全局稀疏点敏感,不擅长处理局部的相对稀疏点 (Local Anomaly)。目前已有改进方法发表于PAKDD,详见“Improving iForest with Relative Mass”。
4. iForest推动了重心估计(Mass Estimation)理论发展,目前在分类聚类和异常检测中都取得显著效果,发表于各大顶级数据挖掘会议和期刊(如SIGKDD,ICDM,ECML)。
iForest (Isolation Forest)孤立森林 异常检测 入门篇:https://www.jianshu.com/p/5af3c66e0410
异常检测概览——孤立森林 效果是最好的:https://www.cnblogs.com/bonelee/p/7776711.html
孤立森林(Isolation Forest):https://blog.csdn.net/extremebingo/article/details/80108247