深度学习经典案例解析:YOLO系列
https://www.toutiao.com/a6621051339352834564/
2018-11-07 17:40:45
Faster R-CNN的方法目前是主流的目标检测方法,但是速度上并不能满足实时的要求。YOLO一类的方法慢慢显现出其重要性,这类方法使用了回归的思想,利用整张图作为网络的输入,直接在图像的多个位置上回归出这个位置的目标边框,以及目标所属的类别。
我们直接看上面YOLO的目标检测的流程图:
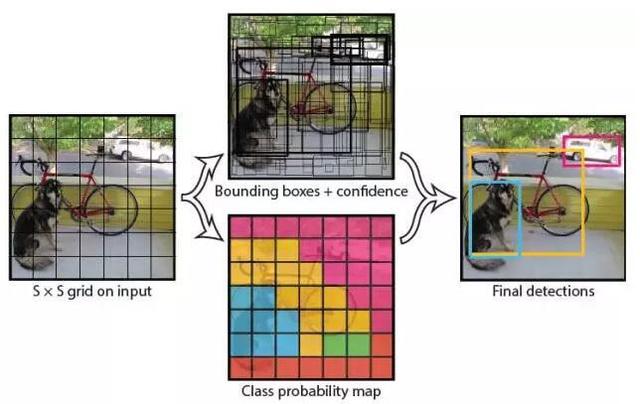
(1) 给个一个输入图像,首先将图像划分成7*7的网格
(2) 对于每个网格,我们都预测2个边框(包括每个边框是目标的置信度以及每个边框区域在多个类别上的概率)
(3) 根据上一步可以预测出7*7*2个目标窗口,然后根据阈值去除可能性比较低的目标窗口,最后非极大值抑制NMS去除冗余窗口即可。
可以看到整个过程非常简单,不再需要中间的Region Proposal找目标,直接回归便完成了位置和类别的判定。
小结:YOLO将目标检测任务转换成一个回归问题,大大加快了检测的速度,使得YOLO可以每秒处理45张图像。而且由于每个网络预测目标窗口时使用的是全图信息,使得false positive比例大幅降低(充分的上下文信息)。
7*7*30:5+5+20

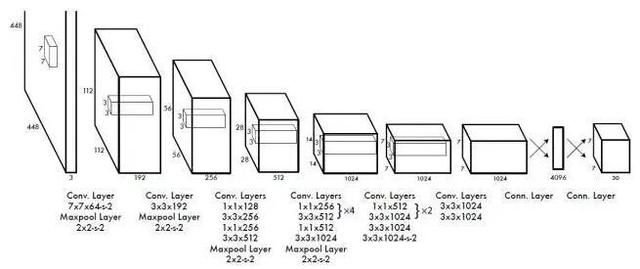
检测流程
1、网络结构设计,预训练 imagenet,图像resize,offset归一化,leaky relu ,网络输出,7*7*30张量 7*7*(2*5+20)=1470
2个bbox 的 一个(confidence)+4个坐标(x,y,w,h) +20个类的概率值---------》输出result class x ,y w,h ,predict
2、网络训练:每个bbox 的是否含有物体confidence值:
对于每个类的confidence (条件概率):
3、loss fuction :均方和误差, 分为三个 corrderror,iouerror,classerror ,对于三个的贡献值不同
c帽 w帽 h帽 p帽 真实标注值

修正3个贡献值不同:1 修正coorderror , 2 noobji=0.5 包含物体,不包含物体,若相同 不含的confidence=0 放大含的con值,对相等的误差,大物体的误差对检测的影响应小于物体小的误差对检测的影响
但是YOLO也存在问题:没有了Region Proposal机制,只使用7*7的网格回归会使得目标不能非常精准的定位,这也导致了YOLO的检测精度并不是很高。
代码难点解析:输出之后 7*7*30 张量后,github yolo tensorflow
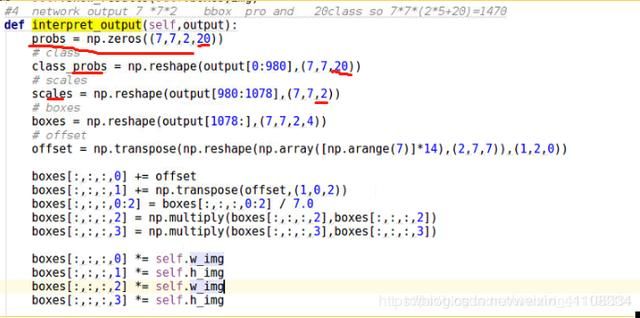
confident * predict 求出最大值。过滤掉0值。 遍历 再用过滤,非极大值抑制,求出检测结果
![]()
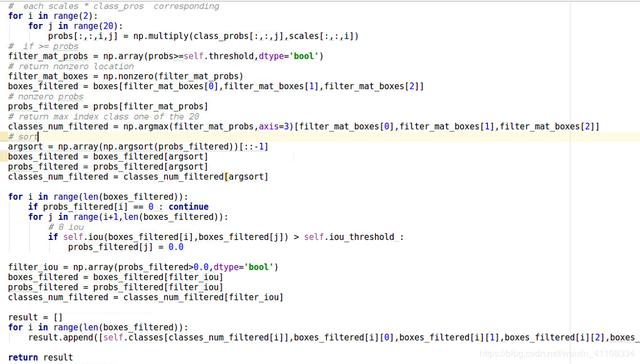
YOLO 缺陷:
1.YOLO对相互靠的很近的物体(挨在一起且中点都落在同一个格子上的情况),还有很小的群体 检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。
2.测试图像中,当同一类物体出现的不常见的长宽比和其他情况时泛化能力偏弱。
3.由于损失函数的问题,定位误差是影响检测效果的主要原因,尤其是大小 物体的处理上,还有待加强
二、yolo v2 YOLOv2的论文全名为YOLO9000: Better, Faster, Stronger,cvpr 2017
在这篇文章中,作者首先在YOLOv1的基础上提出了改进的YOLOv2,然后提出了一种检测与分类联合训练方法,使用这种联合训练方法在COCO检测数据集和ImageNet分类数据集上训练出了YOLO9000模型,其可以检测超过9000多类物体。所以,这篇文章其实包含两个模型:YOLOv2和YOLO9000,不过后者是在前者基础上提出的,两者模型主体结构是一致的。YOLOv2相比YOLOv1做了很多方面的改进,这也使得YOLOv2的mAP有显著的提升,并且YOLOv2的速度依然很快,保持着自己作为one-stage方法的优势,YOLOv2和Faster R-CNN, SSD等模型的对比如图1所示。这里将首先介绍YOLOv2的改进策略,并给出YOLOv2的TensorFlow实现过程,然后介绍YOLO9000的训练方法。近期,YOLOv3也放出来了,YOLOv3也在YOLOv2的基础上做了一部分改进,我们在最后也会简单谈谈YOLOv3所做的改进工作。
图1:YOLOv2与其它模型在VOC 2007数据集上的效果对比
YOLOv2的改进策略
YOLOv1虽然检测速度很快,但是在检测精度上却不如R-CNN系检测方法,YOLOv1在物体定位方面(localization)不够准确,并且召回率(recall)较低。YOLOv2共提出了几种改进策略来提升YOLO模型的定位准确度和召回率,从而提高mAP,YOLOv2在改进中遵循一个原则:保持检测速度,这也是YOLO模型的一大优势。YOLOv2的改进策略如图2所示,可以看出,大部分的改进方法都可以比较显著提升模型的mAP。下面详细介绍各个改进策略。
图2:YOLOv2相比YOLOv1的改进策略
Batch Normalization
Batch Normalization可以提升模型收敛速度,而且可以起到一定正则化效果,降低模型的过拟合。在YOLOv2中,每个卷积层后面都添加了Batch Normalization层,并且不再使用droput。使用Batch Normalization后,YOLOv2的mAP提升了2.4%。
High Resolution Classifier
imagenet上的预训练,在微调,图像大小。
目前大部分的检测模型都会在先在ImageNet分类数据集上预训练模型的主体部分(CNN特征提取器),由于历史原因,ImageNet分类模型基本采用大小为 的图片作为输入,分辨率相对较低,不利于检测模型。所以YOLOv1在采用 分类模型预训练后,将分辨率增加至 ,并使用这个高分辨率在检测数据集上finetune。但是直接切换分辨率,检测模型可能难以快速适应高分辨率。所以YOLOv2增加了在ImageNet数据集上使用 输入来finetune分类网络这一中间过程(10 epochs),这可以使得模型在检测数据集上finetune之前已经适用高分辨率输入。使用高分辨率分类器后,YOLOv2的mAP提升了约4%。
Convolutional With Anchor Boxes
在YOLOv1中,输入图片最终被划分为 网格,每个单元格预测2个边界框。YOLOv1最后采用的是全连接层直接对边界框进行预测,其中边界框的宽与高是相对整张图片大小的,而由于各个图片中存在不同尺度和长宽比(scales and ratios)的物体,YOLOv1在训练过程中学习适应不同物体的形状是比较困难的,这也导致YOLOv1在精确定位方面表现较差。YOLOv2借鉴了Faster R-CNN中RPN网络的先验框(anchor boxes,prior boxes,SSD也采用了先验框)策略。RPN对CNN特征提取器得到的特征图(feature map)进行卷积来预测每个位置的边界框以及置信度(是否含有物体),并且各个位置设置不同尺度和比例的先验框,所以RPN预测的是边界框相对于先验框的offsets值(其实是transform值,详细见Faster R_CNN论文),采用先验框使得模型更容易学习。所以YOLOv2移除了YOLOv1中的全连接层而采用了卷积和anchor boxes来预测边界框。为了使检测所用的特征图分辨率更高,移除其中的一个pool层。在检测模型中,YOLOv2不是采用 图片作为输入,而是采用 大小。因为YOLOv2模型下采样的总步长为 ,对于 大小的图片,最终得到的特征图大小为 ,维度是奇数,这样特征图恰好只有一个中心位置。对于一些大物体,它们中心点往往落入图片中心位置,此时使用特征图的一个中心点去预测这些物体的边界框相对容易些。所以在YOLOv2设计中要保证最终的特征图有奇数个位置。对于YOLOv1,每个cell都预测2个boxes,每个boxes包含5个值: ,前4个值是边界框位置与大小,最后一个值是置信度(confidence scores,包含两部分:含有物体的概率以及预测框与ground truth的IOU)。但是每个cell只预测一套分类概率值(class predictions,其实是置信度下的条件概率值),供2个boxes共享。YOLOv2使用了anchor boxes之后,每个位置的各个anchor box都单独预测一套分类概率值,这和SSD比较类似(但SSD没有预测置信度,而是把background作为一个类别来处理)。
使用anchor boxes之后,YOLOv2的mAP有稍微下降(这里下降的原因,我猜想是YOLOv2虽然使用了anchor boxes,但是依然采用YOLOv1的训练方法)。YOLOv1只能预测98个边界框( ),而YOLOv2使用anchor boxes之后可以预测上千个边界框( )。所以使用anchor boxes之后,YOLOv2的召回率大大提升,由原来的81%升至88%。
Dimension Clusters
在Faster R-CNN和SSD中,先验框的维度(长和宽)都是手动设定的,带有一定的主观性。如果选取的先验框维度比较合适,那么模型更容易学习,从而做出更好的预测。因此,YOLOv2采用k-means聚类方法对训练集中的边界框做了聚类分析。因为设置先验框的主要目的是为了使得预测框与ground truth的IOU更好,所以聚类分析时选用box与聚类中心box之间的IOU值作为距离指标:
图3为在VOC和COCO数据集上的聚类分析结果,随着聚类中心数目的增加,平均IOU值(各个边界框与聚类中心的IOU的平均值)是增加的,但是综合考虑模型复杂度和召回率,作者最终选取5个聚类中心作为先验框,其相对于图片的大小如右边图所示。对于两个数据集,5个先验框的width和height如下所示(来源:YOLO源码的cfg文件):
COCO: (0.57273, 0.677385), (1.87446, 2.06253), (3.33843, 5.47434), (7.88282, 3.52778), (9.77052, 9.16828)
VOC: (1.3221, 1.73145), (3.19275, 4.00944), (5.05587, 8.09892), (9.47112, 4.84053), (11.2364, 10.0071)
但是这里先验框的大小具体指什么作者并没有说明,但肯定不是像素点,从代码实现上看,应该是相对于预测的特征图大小( )。对比两个数据集,也可以看到COCO数据集上的物体相对小点。这个策略作者并没有单独做实验,但是作者对比了采用聚类分析得到的先验框与手动设置的先验框在平均IOU上的差异,发现前者的平均IOU值更高,因此模型更容易训练学习。