阅读日记:computer organization and design——RISC-V——chapter4-3
4.3 Building a Datapath
A reasonable way to start a datapath design是检查执行每类RISC-V指令所需的主要组件。让我们从顶部开始,看看每条指令需要哪些数据路径元素,然后在抽象层中向下工作。当我们显示数据路径元素时,我们还将显示它们的控制信号。
数据路径元素:在处理器中操作或保存数据的单元。在RISC-V实现中,数据路径元素包括指令和数据存储器、寄存器堆、ALU和加法器。
图4.5:

图4.5a显示了我们需要的第一个元素:存储 程序指令 并 提供 给定地址的指令的内存单元。
图4.5b还显示了程序计数器(PC),正如我们在第2章中看到的,它是一个寄存器,保存当前指令的地址。
图4.5c最后,我们将需要一个加法器来增加PC到下一条指令的地址。(This adder, which is combinational, be built from the ALU ,simply by wiring the control lines so that the control always specifies an add operation. )
存储和访问指令需要两个状态元素(指令存储器和程序计数器),计算下一个指令地址需要一个加法器。
指令内存只需要提供读访问,因为数据路径不写指令。由于指令存储器只读取,所以我们将其视为组合逻辑:任何时候的输出都反映地址输入指定位置的内容,不需要读取控制信号。(加载程序时需要写入指令内存;这不难添加,为了简单起见,我们忽略它。)程序计数器是在每个时钟结束时写入的64位寄存器因此不需要写控制信号。加法器是一个ALU,它总是把它的两个64位相加输入并将总和放在其输出上。
图4.6:数据路径的一部分,用于获取指令和递增程序计数器。获取的指令由数据路径的其他部分使用。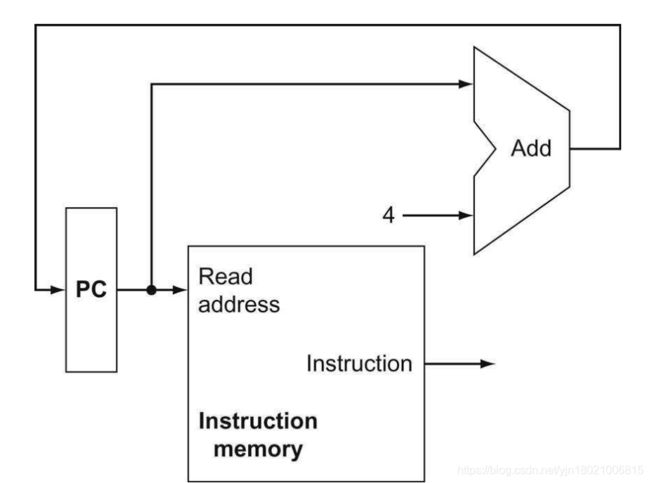
要执行任何指令,我们必须首先获取来自内存的指令。准备执行下一个指令,我们还必须增加程序计数器,使它指向下一条指令,4字节后。图4.6显示了如何将图4.5中的三个元素组合起来形成一个数据路径,该数据路径获取指令并递增PC以获得下一个顺序指令的地址
考虑R格式的指令(参见第120页的图2.19)。它们都读取两个寄存器,对寄存器的内容执行ALU操作,并将结果写入寄存器。我们称这些指令为R型指令或算术指令(因为它们执行算术或逻辑运算)。典型实例是add x1、x2、x3,它读取x2和x3并将和写入x1。
register file:一种状态元素,由一组可读取的寄存器组成并通过提供要访问的寄存器号来写入。
处理器的32个通用寄存器存储在寄存器堆,任何寄存器都可以通过指定文件中寄存器的编号来读取或写入。The register file contains the register state of the computer. 此外,我们需要一个ALU来操作从寄存器读取的值。
R格式指令有三个寄存器操作数,因此我们需要从寄存器文件中读取两个数据字,并为向寄存器文件中写入一个数据字。
读:需要两个输入,它指定要读取的寄存器号,然后得到一个寄存器文件的输出,它将携带从寄存器读取的值。
写:(一个数据字),需要两个输入:一个指定要写入的寄存器号,一个提供要写入寄存器的数据。然而,写操作是由写控制信号控制的,为了使写操作发生在时钟边缘。写信号 must be asserted for a write to occur at the clock edge.
图4.7:实现R格式ALU操作所需的两个元素是寄存器堆和ALU
需要三个输入(两个用于寄存器编号,一个用于数据)和两个输出(两个均用于输出数据)。
寄存器号输入为5位宽,用于指定32个寄存器(2^5)中的一个,而数据输入和两条数据输出总线的宽度均为64位。

记住,写操作是边缘触发的,所以写入输入(即,要写入的值、寄存器号和写入控制信号)必须在时钟边缘有效。由于对寄存器文件的写入是边缘触发的,因此我们的设计可以在一个时钟周期内合法地读写同一个寄存器:读将获得在先前时钟周期中写入的值,而写入的值将在随后的时钟周期中可供读用。将寄存器号携带到寄存器文件的输入都是5位宽,而携带数据值的行是64位宽。
图4.7b显示了ALU,它接受两个64位输入并产生一个64位结果,如果结果为0,则显示一个1位信号。
接下来,考虑RISC-V加载寄存器和存储寄存器指令,这些指令的一般形式为ld x1,offset(x2)或sd x1,offset(x2)。
这些指令通过将基址寄存器x2添加到指令中包含的12位有符号偏移字段来计算内存地址。如果指令是一个存储(store),那么要存储的值也必须从它位于x1中的寄存器文件中读取。如果指令是加载(load),则从内存读取的值必须写入指定寄存器中的寄存器文件,即x1。因此,我们需要图4.7中的寄存器文件和ALU。
总结:加载(load)寄存器和存储(store)寄存器指令也需要寄存器堆和ALU,ALU计算内存地址,对store是读了寄存器堆中哪个寄存器的值,然后根据ALU结果写到哪个存储位置,对load是根据ALU结果从哪个存储位置读取然后写入哪个寄存器。
符号扩展:To increase the size of a data item by replicating the high-order sign bit of the original data item in the high-order bits of the larger, destination data item.
数据存储器:
分支目标地址
分支中指定的地址,如果分支被采纳,它将成为新的程序计数器(PC)。在RISC-V体系结构中,分支目标由指令的偏移量字段和分支地址之和给出。
此外,我们还需要一个符号单元将指令中的12位偏移量字段扩展到64位符号值,并需要一个数据存储单元来读取或写入。数据存储器必须写在存储指令上;因此,数据存储器具有读写控制信号、地址输入和an input for the data to be written into memory.
图4.8

The two units needed to implement loads and stores, 除了 the register file and ALU of Figure 4.7, 还有the data memory unit and the immediate generation unit.
The memory unit :2个输入the address and the write data,1个输出:the read result.
单独的读写控制,尽管在任何给定的时钟上只能有其中的一个是高。
The memory unit: 要一个读取信号,因为与寄存器文件不同,读取无效地址的值可能会导致问题,这个问题我们将在第5章中看到
the immediate generation unit:有一个32位指令作为输入,该指令选择一个12位字段进行加载、存储和分支(如果等于),该指令被符号扩展为出现在输出上的64位结果
beq指令有三个操作数,两个寄存器进行相等比较,a 12-bit offset used to compute the branch target address relative to the branch instruction address。它的形式是beq x1,x2,offset。要实现这条指令,我们必须通过将指令的signextended offset字段添加到PC来计算分支目标地址。分支指令的定义(见第2章)中有两个细节需要注意:指令集体系结构指定分支地址计算的基分支指令的地址。该体系结构还声明偏移字段左移1位,因此它是半字偏移;此偏移将偏移字段的有效范围增加一倍2。To deal with the latter complication, we will need to shift the offset field by 1. 除了计算分支目标地址外,我们还必须确定下一条指令是顺序跟随的指令还是分支目标地址处的指令。当条件为真(即两个操作数相等)时,分支目标地址成为新的PC,我们说分支是被采纳。如果操作数不为零,则递增的PC应替换当前的PC(就像任何其他正常指令一样);在这种情况下,我们说分支不被采纳。
总结:分支数据路径必须执行两个操作:计算分支目标地址和测试寄存器内容。((分支也会影响数据路径的指令获取部分,我们稍后将讨论这个问题。)
图4.9显示了处理分支的数据路径段的结构:分支的数据路径使用ALU计算分支条件,使用单独的加法器计算分支目标(PC和指令的符号扩展12位(分支位移)的总和,左移1位)

为了执行比较,我们需要使用图4.7a所示的寄存器文件来提供两个寄存器操作数(尽管我们不需要向reg写入)。此外,还可以进行等式比较使用我们在附录A中设计的ALU。为提供一个输出信号,指示结果是否为0,我们可以将两个寄存器操作数发送到ALU,并将控件设置为减去两个值。如果从ALU单元输出的零信号是高,我们知道寄存器值是相等的。尽管零输出总是在结果为0时发出信号,但我们将仅使用它来实现条件分支的相等测试。稍后,我们将展示如何连接ALU的控制信号,以便在数据路径中使用。
控制逻辑用于根据ALU的零输出来决定递增PC机或分支目标机是否应取代PC。
分支指令的操作是将PC机的12位指令左移1位。如第2章所述,只要将0连接到分支偏移量即可完成此移位。(不需要实际移位硬件,因为“移位”的量是恒定的。因为我们知道偏移量是从12位开始的符号扩展,所以移位只会丢弃“符号位”)
Creating a Single Datapath
现在我们已经检查了各个指令类所需的数据路径组件,我们可以将它们组合成单个数据路径并添加控件来完成实现。
这个最简单的数据路径将尝试在一个时钟周期内执行所有指令。
这种设计意味着每个指令不能使用多个数据路径资源,因此任何需要多次的元素都必须重复。
尽管有些功能单元需要复制,但许多元素可以由不同的指令流共享。
要在两个不同的指令类之间共享数据路径元素,我们可能需要允许多个连接到元素的输入,使用多路复用器和控制信号在多个输入之间进行选择。
ex:
算术逻辑(或R-type)指令和内存指令datapath的操作非常相似。主要区别如下:
源操作数::算术逻辑指令使用ALU,输入来自两个寄存器。内存指令也使用ALU进行地址计算,尽管第二个输入是指令的符号扩展12位偏移字段。
目的操作数:The value stored into a destination register comes from the ALU (for an R-type instruction) or the memory (for a load).
Show如何为LOAD和算术逻辑指令的操作部分构建数据路径,这些指令使用一个寄存器堆和单个ALU来处理这两种类型的指令,并添加任何必要的MUX。
answer:
要创建只有一个寄存器文件和一个ALU的数据路径。we must support two different sources for the second ALU input, as well as two different sources for the data stored into the register file.Thus, one multiplexor is placed at the ALU input and another at the data input to the register file.
Figure 4.10 shows the operational portion of the combined datapath.

现在:通过添加用于instruction fetch (Figure 4.6), the datapath from R-type and memory instructions (Figure 4.10), and the datapath for branches (Figure 4.9). 将所有部分组合起来,为核心RISC-V体系结构创建一个简单的数据路径。
图4.11显示了我们通过组合各个部分获得的数据路径。分支指令使用主ALU比较两个寄存器操作数是否相等,因此必须保持
图4.9中的加法器,用于计算分支目标地址。另一个MUX需要选择顺序跟随的指令地址(PC+4)或要写入PC的分支目标地址。
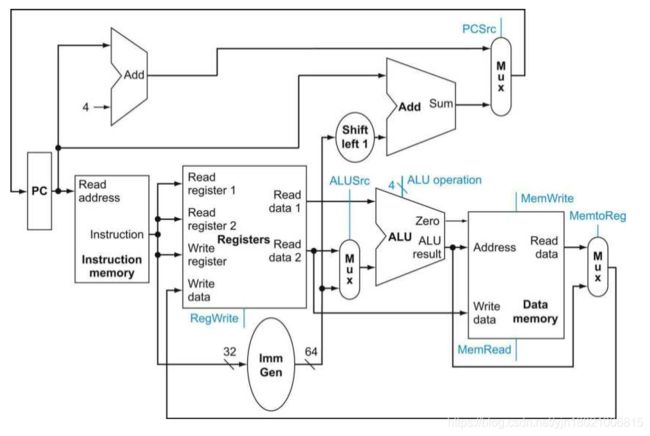
核心RISC-V架构的简单数据路径结合了不同指令类所需的元素。部件来自图4.6、4.9和4.10。
此数据路径可以在单个时钟周期内执行基本指令(加载存储寄存器、ALU操作和分支)。
控制单元
现在我们已经完成了这个简单的数据路径,我们可以添加控制单元:
控制单元必须能够接收输入并为每个状态元素生成写入信号,为每个多路复用器生成选择器控制,以及ALU控制。(The ALU control is different in a number of ways, and it will be useful to design it first before we design the rest of the control unit.)
略到517
Why a Single-Cycle Implementation is not Used Today
Although the single-cycle design will work correctly,但在这个单周期设计中,每个指令的时钟周期必须具有相同的长度。处理器中可能的最长路径决定了时钟周期。(This path is most likely a load instruction, which uses five functional units in series: the instruction memory, the register file, the ALU, the data memory, and the register file. )
尽管CPI是1(见第1章),但是单周期实现的总体性能太差,因为时钟周期太长了。
我们必须假设时钟周期等于所有指令的最坏情况延迟,尝试减少常见情况延迟但不提高最坏情况循环时间的实现技术是无用的。因此,单周期的实现违背了第一章中关于快速处理公共案例的伟大思想。
预告:在下一节中,我们将研究另一种实现技术,称为流水线,它使用与单周期数据路径非常相似的数据路径,但通过具有更高的吞吐量而更有效。流水线通过同时执行多个指令提高效率