数十万数据Excel数据不好处理怎么办?几行Python搞定
电商行业,每月有上百万条订单发货数据需要与仓库的数据进行核对计算,涉及到数据计算,筛选,匹配等步骤,用excel表超级卡,并且经常卡死。

这时如果你会Python,十几行代码就可以搞定。
这里需要两个Python库,一个是os库,一个是pandas库。
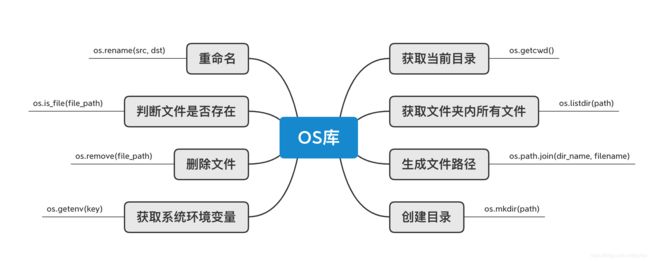
os库
os是Python内置库,不需要额外安装,只要用import导入就可以用了。os模块封装了常见的文件和目录操作,利用它可以轻松的对系统上的目录和文件进行各种操作,比如获取当前目录、列举当前文件夹中的所有文件和文件夹、判断文件或目录是否存在、删除文件等。
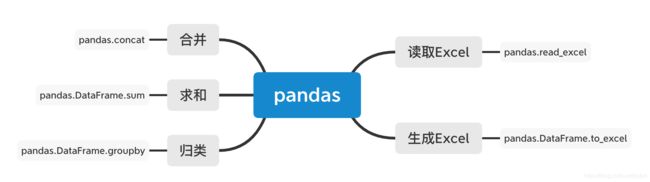
pandas库
pandas是第三方库,需要手动安装才能使用。pandas是专门用来做数据分析的强大类库,可以方便地从csv、Excel和其他文本文件以及数据库中读取数据,然后对数据进行加和、求平均值、求方差、计算最大值最小值等数据分析,支持生成Excel等格式文件或进行可视化操作。
其中读Excel需要依赖xlrd库,写Excel依赖openpyxl,pandas、xlrd和openpyxl安装命令如下:
$ pip install xlrd openpyxl pandas
下面开始进行数据处理…
这里假设数据是按日期命名的Excel文件并且放在一个Excel文件夹中,每个Excel文件包含用户ID、商品ID、商品属性列表、购买数量这几列信息。
文件夹中的所有文件如下:
ls excel_data
20120702.xlsx 20131018.xlsx 20150203.xlsx 20170416.xlsx 20180814.xlsx
20120703.xlsx 20131019.xlsx 20150204.xlsx 20170417.xlsx 20180815.xlsx
20120704.xlsx 20131020.xlsx 20150205.xlsx 20170418.xlsx 20180816.xlsx ...
实现的思路是利用os库获取所有的Excel文件,然后用pandas依次读取所有文件并合并到一起进行数据分析,计算出每个商品的总量以及销量前十的商品。
列举所有Excel文件
import os
files = os.listdir("excel_data")
用pandas读取所有数据并合并到一起
import pandas as pd
df_list = [pd.read_excel(os.path.join("excel_data", f)) for f in files]
data = pd.concat(df_list)
# 统计每个商品的数量
sum_of_product = data[["商品ID", "购买数量"]].groupby(["商品ID"]).sum()
sum_of_product
| 购买数量 | |
|---|---|
| 商品ID | |
| 1662 | 1 |
| 201826 | 17 |
| 203319 | 67 |
| 203320 | 494 |
| 203322 | 332 |
| ... | ... |
| 122680025 | 21 |
| 122680026 | 8 |
| 122690023 | 16 |
| 122692024 | 48 |
| 122696024 | 5 |
662 rows × 1 columns
# 获取销量前十的商品
sum_of_product.sort_values('购买数量', ascending=False).head(10)
| 购买数量 | |
|---|---|
| 商品ID | |
| 50018831 | 56632 |
| 50007016 | 8291 |
| 50011993 | 6351 |
| 50013636 | 6340 |
| 50003700 | 6325 |
| 211122 | 5823 |
| 50010558 | 5248 |
| 50016006 | 4948 |
| 50006602 | 4692 |
| 50002524 | 4123 |
完整代码如下:
import os
import pandas as pd
# 获取所有Excel文件并读取数据
files = os.listdir("excel_data")
df_list = [pd.read_excel(os.path.join("excel_data", f)) for f in files]
data = pd.concat(df_list)
# 统计每个商品的数量,并输出到Excel文件中
sum_of_product = data[["商品ID", "购买数量"]].groupby(["商品ID"]).sum()
sum_of_product.to_excel("各个商品数量统计.xlsx")
# 统计销量前十的商品
sum_of_product.sort_values('购买数量', ascending=False).head(10)
| 购买数量 | |
|---|---|
| 商品ID | |
| 50018831 | 56632 |
| 50007016 | 8291 |
| 50011993 | 6351 |
| 50013636 | 6340 |
| 50003700 | 6325 |
| 211122 | 5823 |
| 50010558 | 5248 |
| 50016006 | 4948 |
| 50006602 | 4692 |
| 50002524 | 4123 |
教程就到这里,不足之处欢迎交流指正。