背景
在业务系统开发的过程中,很多情况下会去识别图片中的相关信息,并且把信息录入到系统中。现在希望通过自动化的方式录入,就有了以下的工作。在对比了几个OCR软件在中文识别方面的准确率后,决定使用微软的OneNote开发相应的功能。
准备工作
- 安装OneNote 2010;(注:在 Microsoft Office 2003 中的工具组件中有一个“ Microsoft Office Document Imaging”的组件包,之后的Office版本将这个功能集成到OneNote中了)
- 查询网上相关OneNote的资料,真是少得可怜,即使找到现有的代码也是各种坑。
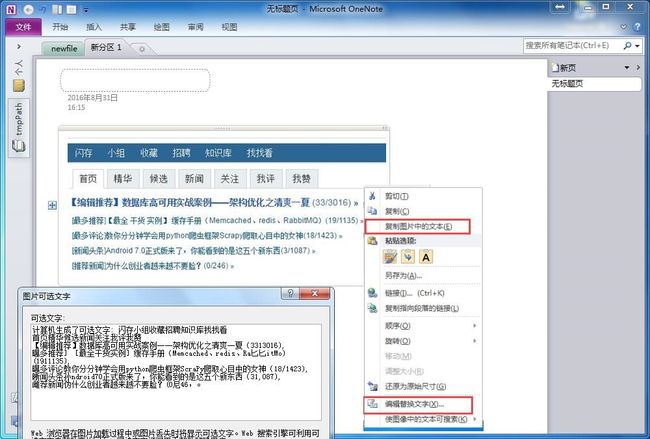
- 在OneNote中的图片识别功能如下图,把图片放到一个tab中,右键图片就会出现红框所标注的功能,这个是我需要在程序中来调用的:
代码实现的逻辑
- 获取图片的Base64编码;
- 开启OneNote程序,在一个空的newfile.one中,生成一个新的page;
- 此时,新的page页中,会有一个固定格式的xml,把图片的Base64编码,更新到对应的节点上;
- 更新节点后,会自动调用OCR的功能,把识别出来的文字,放入到固定节点上;
- 从识别出来的文字节点上,取出相应的文字就可以了;
- 彻底销毁当前的页面(如果不是彻底的话,这个newfile.one会越来越大);


1 public class OrcImage 2 { 3 private static readonly string tmpPath = AppDomain.CurrentDomain.BaseDirectory + "tmpPath/"; 4 private static readonly int waitTime = Convert.ToInt32(ConfigurationManager.AppSettings["WaitTime"]); 5 6 private Tuple<string, int, int> GetBase64(string strImgPath) 7 { 8 return GetBase64(new FileInfo(strImgPath)); 9 } 10 11 ///12 /// 获取图片的Base64编码 13 /// 14 /// 15 /// 16 private Tuple<string, int, int> GetBase64(FileInfo file) 17 { 18 using (MemoryStream ms = new MemoryStream()) 19 { 20 Bitmap bp = new Bitmap(file.FullName); 21 switch (file.Extension.ToLower()) 22 { 23 case ".jpg": 24 bp.Save(ms, ImageFormat.Jpeg); 25 break; 26 27 case ".jpeg": 28 bp.Save(ms, ImageFormat.Jpeg); 29 break; 30 31 case ".gif": 32 bp.Save(ms, ImageFormat.Gif); 33 break; 34 35 case ".bmp": 36 bp.Save(ms, ImageFormat.Bmp); 37 break; 38 39 case ".tiff": 40 bp.Save(ms, ImageFormat.Tiff); 41 break; 42 43 case ".png": 44 bp.Save(ms, ImageFormat.Png); 45 break; 46 47 case ".emf": 48 bp.Save(ms, ImageFormat.Emf); 49 break; 50 51 default: 52 return new Tuple<string, int, int>("不支持的图片格式。", 0, 0); 53 } 54 byte[] buffer = ms.GetBuffer(); 55 return new Tuple<string, int, int>(Convert.ToBase64String(buffer), bp.Width, bp.Height); 56 } 57 } 58 59 public string Orc_Img(FileInfo fi) 60 { 61 // 向Onenote2010中插入图片 62 var onenoteApp = new Microsoft.Office.Interop.OneNote.Application(); //onenote提供的API 63 /***************************************************************************************/ 64 string sectionID; 65 onenoteApp.OpenHierarchy(tmpPath + "newfile.one", null, out sectionID, CreateFileType.cftSection); 66 string pageID = "{A975EE72-19C3-4C80-9C0E-EDA576DAB5C6}{1}{B0}"; // 格式 {guid}{tab}{??} 67 onenoteApp.CreateNewPage(sectionID, out pageID, NewPageStyle.npsBlankPageNoTitle); 68 /********************************************************************************/ 69 string notebookXml; 70 onenoteApp.GetHierarchy(null, HierarchyScope.hsPages, out notebookXml); 71 var doc = XDocument.Parse(notebookXml); 72 var ns = doc.Root.Name.Namespace; 73 var pageNode = doc.Descendants(ns + "Page").FirstOrDefault(); 74 var existingPageId = pageNode.Attribute("ID").Value; 75 if (pageNode != null) 76 { 77 Tuple<string, int, int> imgInfo = this.GetBase64(fi); 78 var page = new XDocument(new XElement(ns + "Page", 79 new XElement(ns + "Outline", 80 new XElement(ns + "OEChildren", 81 new XElement(ns + "OE", 82 new XElement(ns + "Image", 83 new XAttribute("format", fi.Extension.Remove(0, 1)), new XAttribute("originalPageNumber", "0"), 84 new XElement(ns + "Position", 85 new XAttribute("x", "0"), new XAttribute("y", "0"), new XAttribute("z", "0")), 86 new XElement(ns + "Size", 87 new XAttribute("width", imgInfo.Item2), new XAttribute("height", imgInfo.Item3)), 88 new XElement(ns + "Data", imgInfo.Item1))))))); 89 page.Root.SetAttributeValue("ID", existingPageId); 90 91 onenoteApp.UpdatePageContent(page.ToString(), DateTime.MinValue); 92 93 // 线程休眠时间,单位毫秒,若图片很大,则延长休眠时间,保证Onenote OCR完毕 94 int fileSize = Convert.ToInt32(fi.Length / 1024 / 1024); // 文件大小 单位M 95 System.Threading.Thread.Sleep(waitTime * (fileSize > 1 ? fileSize : 1)); // 小于1M的都默认1M 96 97 string pageXml; 98 onenoteApp.GetPageContent(existingPageId, out pageXml, PageInfo.piBinaryData); 99 100 /*********************************************************************************/ 101 102 XmlDocument xmlDoc = new XmlDocument(); 103 xmlDoc.LoadXml(pageXml); 104 XmlNamespaceManager nsmgr = new XmlNamespaceManager(xmlDoc.NameTable); 105 nsmgr.AddNamespace("one", ns.ToString()); 106 107 XmlNode xmlNode = xmlDoc.SelectSingleNode("//one:Image//one:OCRText", nsmgr); 108 string strRet = xmlNode.InnerText; 109 110 /**********************************************************************/ 111 112 onenoteApp.DeleteHierarchy(sectionID, DateTime.MinValue, true); // 摧毁原始页面 113 114 return strRet; 115 } 116 117 return "没有识别"; 118 } 119 }
XML的格式
1 /*Onenote 2010 中图片的XML格式 2 <one:Image format="" originalPageNumber="0" lastModifiedTime="" objectID=""> 3 <one:Position x="" y="" z=""/> 4 <one:Size width="" height=""/> 5 <one:Data>Base64one:Data> 6 7 //以下标签由Onenote 2010自动生成,不要在程序中处理,目标是获取OCRText中的内容。 8 <one:OCRData lang="en-US"> 9 <one:OCRText> 10 OCR后的文字 ]]> 11 one:OCRText> 12 <one:OCRToken startPos="0" region="0" line="0" x="4.251968383789062" y="3.685039281845092" width="31.18110275268555" height="7.370078563690185"/> 13 <one:OCRToken startPos="7" region="0" line="0" x="39.40157318115234" y="3.685039281845092" width="13.32283401489258" height="8.78740119934082"/> 14 <one:OCRToken startPos="12" region="0" line="1" x="4.251968383789062" y="17.85826683044434" width="23.52755928039551" height="6.803150177001953"/> 15 <one:OCRToken startPos="18" region="0" line="1" x="32.031494140625" y="17.85826683044434" width="41.10236358642578" height="6.803150177001953"/> 16 <one:OCRToken startPos="28" region="0" line="1" x="77.66928863525391" y="17.85826683044434" width="31.46456718444824" height="6.803150177001953"/> 17 ................ 18 one:Image> 19 */ 20 21 /*ObjectID格式 22 The representation of an object to be used for identification of objects on a page. Not unique through OneNote, but unique on the page and the hierarchy. 23 <xsd:simpleType name="ObjectID" "> 24 <xsd:restriction base="xsd:string"> 25 <xsd:pattern value="\{[a-fA-F0-9]{8}-[a-fA-F0-9]{4}-[a-fA-F0-9]{4}-[a-fA-F0-9]{4}-[a-fA-F0-9]{12}\}\{[0-9]+\}\{[A-Z][0-9]+\}" /> 26 xsd:restriction> 27 xsd:simpleType> 28 */
目前是桌面应用程序是实现了相关功能。预期期望是:任何一个系统通过webservice接口形式就能使用OCR功能。但是改成一个web程序遇到了问题,在网上找了仅有的一点点资料,也没有解决。我了解到,现在使用OneNote的OCR功能的程序也都是用WinForm程序,在程序运行的过程中,会在后台启动OneNote程序。所以我猜测可能是由于这个原因,导致它只能做成桌面程序。
检索 COM 类工厂中 CLSID 为 {D7FAC39E-7FF1-49AA-98CF-A1DDD316337E} 的组件失败,原因是出现以下错误: 80070005 拒绝访问。 (异常来自 HRESULT:0x80070005 (E_ACCESSDENIED))。
web中报这个错误,是权限的问题。依照配置Excel,Word这类COM来找,可是发现DCOM中,一直都找不到这个ID的组件。知道的朋友麻烦告知一下,谢谢。
程序效果图如下:识别效果还不错,剩下的就是根据所需要的信息,进行正则表达式的匹配就可以了。

源码 OCRTools