【转】推荐系统算法总结(三)——FM与DNN DeepFM
来源:https://blog.csdn.net/qq_23269761/article/details/81366939,如有不妥,请随时联系沟通,谢谢~
0.疯狂安利一个博客
FM的前世今生:
https://tracholar.github.io/machine-learning/2017/03/10/factorization-machine.html#%E7%BB%BC%E8%BF%B0
1.FM 与 DNN和embedding的关系
先来复习一下FM 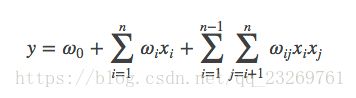

对FM模型进行求解后,对于每一个特征xi都能够得到对应的隐向量vi,那么这个vi到底是什么呢?
想一想Google提出的word2vec,word2vec是word embedding方法的一种,word embedding的意思就是,给出一个文档,文档就是一个单词序列,比如 “A B A C B F G”, 希望对文档中每个不同的单词都得到一个对应的向量(往往是低维向量)表示。比如,对于这样的“A B A C B F G”的一个序列,也许我们最后能得到:A对应的向量为[0.1 0.6 -0.5],B对应的向量为[-0.2 0.9 0.7] 。
所以结论就是:
FM算法是一个特征组合以及降维的工具,它能够将原本因为one-hot编码产生的稀疏特征,进行两两组合后还能做一个降维!!降到多少维呢?就是FM中隐因子的个数k
2.FNN
利用FM做预训练实现embedding,再通过DNN进行训练 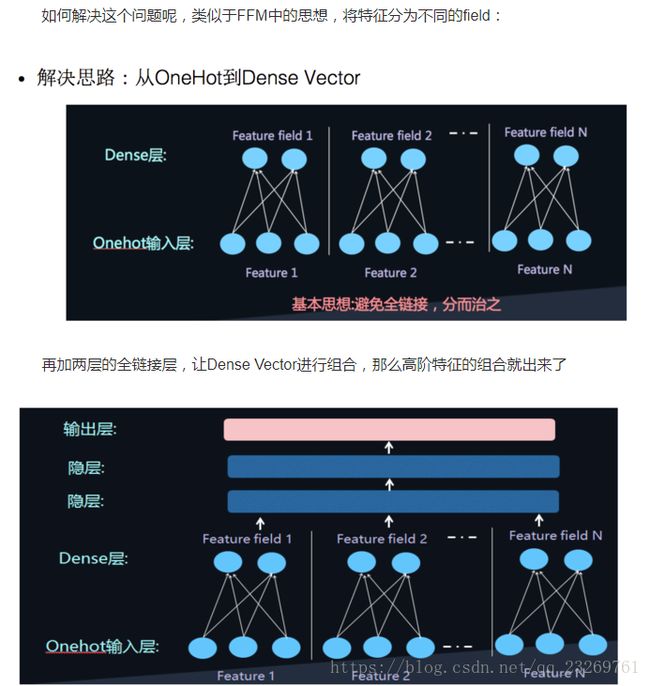
这样的模型则是考虑了高阶特征,而在最后sigmoid输出时忽略了低阶特征本身。
3.DeepFM
鉴于上述理论,目前新出的很多基于深度学习的CTR模型都从wide、deep(即低阶、高阶)两方面同时进行考虑,进一步提高模型的泛化能力,比如DeepFM。
参考博客:https://blog.csdn.net/zynash2/article/details/79348540 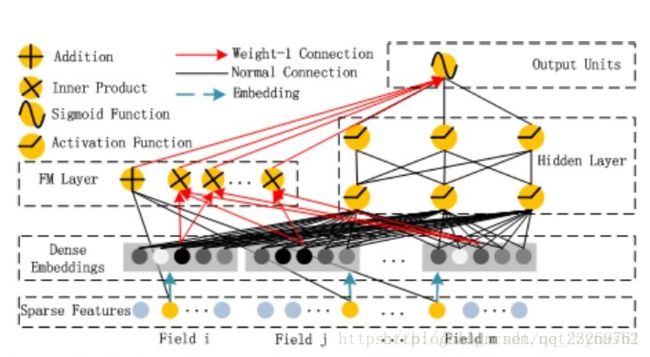
可以看到,整个模型大体分为两部分:FM和DNN。简单叙述一下模型的流程:借助FNN的思想,利用FM进行embedding,之后的wide和deep模型共享embedding之后的结果。DNN的输入完全和FNN相同(这里不用预训练,直接把embedding层看作一层的NN),而通过一定方式组合后,模型在wide上完全模拟出了FM的效果(至于为什么,论文中没有详细推导,本文会稍后给出推导过程),最后将DNN和FM的结果组合后激活输出。
需要着重强调理解的时模型中关于FM的部分,究竟时如何搭建网络计算2阶特征的
**划重点:**embedding层对于DNN来说时在提取特征,对于FM来说就是他的2阶特征啊!!!!只不过FM和DNN共享embedding层而已。
4.DeepFM代码解读
先放代码链接:
https://github.com/ChenglongChen/tensorflow-DeepFM
数据下载地址:
https://www.kaggle.com/c/porto-seguro-safe-driver-prediction
4.0 项目目录
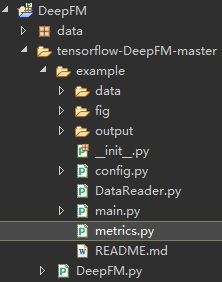
data:存储训练数据与测试数据
output/fig:用来存放输出结果和训练曲线
config:数据获取和特征工程中一些参数的设置
DataReader:特征工程,获得真正用于训练的特征集合
main:主程序入口
mertics:定义了gini指标作为评价指标
DeepFM:模型定义
4.1 整体过程
推荐一篇此数据集的EDA分析,看过可以对数据集的全貌有所了解:
https://blog.csdn.net/qq_37195507/article/details/78553581
- 1._load_data()
def _load_data():
dfTrain = pd.read_csv(config.TRAIN_FILE)
dfTest = pd.read_csv(config.TEST_FILE)
def preprocess(df):
cols = [c for c in df.columns if c not in ["id", "target"]]
df["missing_feat"] = np.sum((df[cols] == -1).values, axis=1)
df["ps_car_13_x_ps_reg_03"] = df["ps_car_13"] * df["ps_reg_03"]
return df
dfTrain = preprocess(dfTrain)
dfTest = preprocess(dfTest)
cols = [c for c in dfTrain.columns if c not in ["id", "target"]]
cols = [c for c in cols if (not c in config.IGNORE_COLS)]
X_train = dfTrain[cols].values
y_train = dfTrain["target"].values
X_test = dfTest[cols].values
ids_test = dfTest["id"].values
cat_features_indices = [i for i,c in enumerate(cols) if c in config.CATEGORICAL_COLS]
return dfTrain, dfTest, X_train, y_train, X_test, ids_test, cat_features_indices首先读取原始数据文件TRAIN_FILE,TEST_FILE
preprocess(df)添加了两个特征分别是missing_feat【缺失特征个数】与ps_car_13_x_ps_reg_03【两个特征的乘积】
返回:
dfTrain, dfTest :所有特征都存在的Dataframe形式
X_train, X_test:删掉了IGNORE_COLS的ndarray格式 【X_test后面都没有用到啊】
y_train: label
ids_test:测试集的id,ndarray
cat_features_indices:类别特征的特征indices
- 利用X_train, y_train 进行了K折均衡交叉验证切分数据集
- DeepFM参数设置
- 2._run_base_model_dfm
def _run_base_model_dfm(dfTrain, dfTest, folds, dfm_params):
fd = FeatureDictionary(dfTrain=dfTrain, dfTest=dfTest,
numeric_cols=config.NUMERIC_COLS,
ignore_cols=config.IGNORE_COLS)
data_parser = DataParser(feat_dict=fd)
Xi_train, Xv_train, y_train = data_parser.parse(df=dfTrain, has_label=True)
Xi_test, Xv_test, ids_test = data_parser.parse(df=dfTest)
dfm_params["feature_size"] = fd.feat_dim
dfm_params["field_size"] = len(Xi_train[0])
y_train_meta = np.zeros((dfTrain.shape[0], 1), dtype=float)
y_test_meta = np.zeros((dfTest.shape[0], 1), dtype=float)
_get = lambda x, l: [x[i] for i in l]
gini_results_cv = np.zeros(len(folds), dtype=float)
gini_results_epoch_train = np.zeros((len(folds), dfm_params["epoch"]), dtype=float)
gini_results_epoch_valid = np.zeros((len(folds), dfm_params["epoch"]), dtype=float)
for i, (train_idx, valid_idx) in enumerate(folds):
Xi_train_, Xv_train_, y_train_ = _get(Xi_train, train_idx), _get(Xv_train, train_idx), _get(y_train, train_idx)
Xi_valid_, Xv_valid_, y_valid_ = _get(Xi_train, valid_idx), _get(Xv_train, valid_idx), _get(y_train, valid_idx)
dfm = DeepFM(**dfm_params)
dfm.fit(Xi_train_, Xv_train_, y_train_, Xi_valid_, Xv_valid_, y_valid_)
y_train_meta[valid_idx,0] = dfm.predict(Xi_valid_, Xv_valid_)
y_test_meta[:,0] += dfm.predict(Xi_test, Xv_test)
gini_results_cv[i] = gini_norm(y_valid_, y_train_meta[valid_idx])
gini_results_epoch_train[i] = dfm.train_result
gini_results_epoch_valid[i] = dfm.valid_result
y_test_meta /= float(len(folds))
# save result
if dfm_params["use_fm"] and dfm_params["use_deep"]:
clf_str = "DeepFM"
elif dfm_params["use_fm"]:
clf_str = "FM"
elif dfm_params["use_deep"]:
clf_str = "DNN"
print("%s: %.5f (%.5f)"%(clf_str, gini_results_cv.mean(), gini_results_cv.std()))
filename = "%s_Mean%.5f_Std%.5f.csv"%(clf_str, gini_results_cv.mean(), gini_results_cv.std())
_make_submission(ids_test, y_test_meta, filename)
_plot_fig(gini_results_epoch_train, gini_results_epoch_valid, clf_str)
return y_train_meta, y_test_meta经过
DataReader中的FeatureDictionary
这个对象中有一个self.feat_dict属性,长下面这个样子:
{'missing_feat': 0, 'ps_ind_18_bin': {0: 254, 1: 255}, 'ps_reg_01': 256, 'ps_reg_02': 257, 'ps_reg_03': 258}
DataReader中的DataParser
class DataParser(object):
def __init__(self, feat_dict):
self.feat_dict = feat_dict #这个feat_dict是FeatureDictionary对象实例
def parse(self, infile=None, df=None, has_label=False):
assert not ((infile is None) and (df is None)), "infile or df at least one is set"
assert not ((infile is not None) and (df is not None)), "only one can be set"
if infile is None:
dfi = df.copy()
else:
dfi = pd.read_csv(infile)
if has_label:
y = dfi["target"].values.tolist()
dfi.drop(["id", "target"], axis=1, inplace=True)
else:
ids = dfi["id"].values.tolist()
dfi.drop(["id"], axis=1, inplace=True)
# dfi for feature index
# dfv for feature value which can be either binary (1/0) or float (e.g., 10.24)
dfv = dfi.copy()
for col in dfi.columns:
if col in self.feat_dict.ignore_cols:
dfi.drop(col, axis=1, inplace=True)
dfv.drop(col, axis=1, inplace=True)
continue
if col in self.feat_dict.numeric_cols:
dfi[col] = self.feat_dict.feat_dict[col]
else:
dfi[col] = dfi[col].map(self.feat_dict.feat_dict[col])
dfv[col] = 1.
#dfi.to_csv('dfi.csv')
#dfv.to_csv('dfv.csv')
# list of list of feature indices of each sample in the dataset
Xi = dfi.values.tolist()
# list of list of feature values of each sample in the dataset
Xv = dfv.values.tolist()
if has_label:
return Xi, Xv, y
else:
return Xi, Xv, ids这里Xi,Xv都是二位数组,可以将dfi,dfv存在csv文件中看一下长什么样子,长的很奇怪【可能后面模型需要吧~】
dfi:value值为特征index,也就是上文中feat_dict属性保存的值 
dfv:如果是数值变量,则保持原本的值,如果是分类变量,则value为1 
4.2 模型架构
def _init_graph(self):
self.graph = tf.Graph()
with self.graph.as_default():
tf.set_random_seed(self.random_seed)
self.feat_index = tf.placeholder(tf.int32, shape=[None, None],
name="feat_index") # None * F
self.feat_value = tf.placeholder(tf.float32, shape=[None, None],
name="feat_value") # None * F
self.label = tf.placeholder(tf.float32, shape=[None, 1], name="label") # None * 1
self.dropout_keep_fm = tf.placeholder(tf.float32, shape=[None], name="dropout_keep_fm")
self.dropout_keep_deep = tf.placeholder(tf.float32, shape=[None], name="dropout_keep_deep")
self.train_phase = tf.placeholder(tf.bool, name="train_phase")
self.weights = self._initialize_weights()
# model
self.embeddings = tf.nn.embedding_lookup(self.weights["feature_embeddings"],
self.feat_index) # None * F * K
#print(self.weights["feature_embeddings"]) shape=[259,8] n*k个隐向量
#print(self.embeddings) shape=[?,39,8] f*k 每个field取出一个隐向量[这不是FFM每个field取是在取非0量,减少计算]
feat_value = tf.reshape(self.feat_value, shape=[-1, self.field_size, 1])
#print(feat_value) shape=[?,39*1] 某一个样本的39个Feature值
self.embeddings = tf.multiply(self.embeddings, feat_value) #multiply在有一个维度不同时,较少的维度会自行扩展
#print(self.embeddings) shape=[?,39*8]
# 所以这个multiply之后得到的矩阵是Vixi,方便以后进行*xi*xj=的计算,后面的计算FM被简化为了
# sum_square part-square_sum part的形式,采用上面multiply的形式更方便啊!
# ---------- first order term ----------
self.y_first_order = tf.nn.embedding_lookup(self.weights["feature_bias"], self.feat_index) # None * F * 1
self.y_first_order = tf.reduce_sum(tf.multiply(self.y_first_order, feat_value), 2) # None * F
self.y_first_order = tf.nn.dropout(self.y_first_order, self.dropout_keep_fm[0]) # None * F
# ---------- second order term ---------------
# sum_square part
self.summed_features_emb = tf.reduce_sum(self.embeddings, 1) # None * K
self.summed_features_emb_square = tf.square(self.summed_features_emb) # None * K
# square_sum part
self.squared_features_emb = tf.square(self.embeddings)
self.squared_sum_features_emb = tf.reduce_sum(self.squared_features_emb, 1) # None * K
# second order
self.y_second_order = 0.5 * tf.subtract(self.summed_features_emb_square, self.squared_sum_features_emb) # None * K
self.y_second_order = tf.nn.dropout(self.y_second_order, self.dropout_keep_fm[1]) # None * K
# ---------- Deep component ----------
self.y_deep = tf.reshape(self.embeddings, shape=[-1, self.field_size * self.embedding_size]) # None * (F*K)
self.y_deep = tf.nn.dropout(self.y_deep, self.dropout_keep_deep[0])
for i in range(0, len(self.deep_layers)):
self.y_deep = tf.add(tf.matmul(self.y_deep, self.weights["layer_%d" %i]), self.weights["bias_%d"%i]) # None * layer[i] * 1
if self.batch_norm:
self.y_deep = self.batch_norm_layer(self.y_deep, train_phase=self.train_phase, scope_bn="bn_%d" %i) # None * layer[i] * 1
self.y_deep = self.deep_layers_activation(self.y_deep)
self.y_deep = tf.nn.dropout(self.y_deep, self.dropout_keep_deep[1+i]) # dropout at each Deep layer
# ---------- DeepFM ----------
if self.use_fm and self.use_deep:
concat_input = tf.concat([self.y_first_order, self.y_second_order, self.y_deep], axis=1)
elif self.use_fm:
concat_input = tf.concat([self.y_first_order, self.y_second_order], axis=1)
elif self.use_deep:
concat_input = self.y_deep
self.out = tf.add(tf.matmul(concat_input, self.weights["concat_projection"]), self.weights["concat_bias"]) 不知道为什么这篇代码把FM写的看起来很复杂。人家复杂是有原因的!!避免了使用one-hot编码后的大大大矩阵
其实就是embedding层Deep和FM共用了隐向量【feature_size*k】矩阵
所以这个实现的重点在embedding层啊,这里的实现方式通过Xi,Xv两个较小的矩阵【n*field】注意这里field不是FFM中的F,而是未one-hot编码前的Feature数量。 
根据内积的公式我们可以得到