代码练习
1.完善HybridSN高光谱分类网络

三维卷积部分:conv1:(1, 30, 25, 25), 8个7x3x3 的卷积核 ==>(8, 24, 23, 23)conv2:(8, 24, 23, 23), 16个 5x3x3 的卷积核 ==>(16, 20, 21, 21)conv3:(16, 20, 21, 21),32个 3x3x3 的卷积核 ==>(32, 18, 19, 19)
接下来要进行二维卷积,因此把前面的 32*18 reshape 一下,得到 (576, 19, 19)
二维卷积:(576, 19, 19) 64个 3x3 的卷积核,得到 (64, 17, 17)
然后是一个 flatten 操作,变为 18496 维的向量
依次为256,128节点的全连接层,都使用比例为0.4的 Dropout,
最后输出为 16 个节点。
在上一周的测试结果为

本周学习并修改代码为
class_num = 16 class HybridSN(nn.Module): def __init__(self): super(HybridSN,self).__init__() self.conv1 = nn.Conv3d(1,8,kernel_size=(7,3,3),stride=1,padding=0) self.bn1 = nn.BatchNorm3d(8) self.conv2 = nn.Conv3d(8,16,kernel_size=(5,3,3),stride=1,padding=0) self.bn2 = nn.BatchNorm3d(16) self.conv3 = nn.Conv3d(16,32,kernel_size=(3,3,3),stride=1,padding=0) self.bn3 = nn.BatchNorm3d(32) self.conv4 = nn.Conv2d(576,64,kernel_size=(3,3),stride=1,padding=0) self.bn4 = nn.BatchNorm2d(64) self.fc1 = nn.Linear(18496,256) self.fc2 = nn.Linear(256,128) self.fc3 = nn.Linear(128,16) self.drop = nn.Dropout(0.4) def forward(self,x): out = F.relu(self.bn1(self.conv1(x))) out = F.relu(self.bn2(self.conv2(out))) out = F.relu(self.bn3(self.conv3(out))) out = out.reshape(out.shape[0],-1,19,19) out = F.relu(self.bn4(self.conv4(out))) out = out.reshape(out.shape[0],-1) out = F.relu(self.drop(self.fc1(out))) out = F.relu(self.drop(self.fc2(out))) out = self.fc3(out) return out
得到的测试结果为:
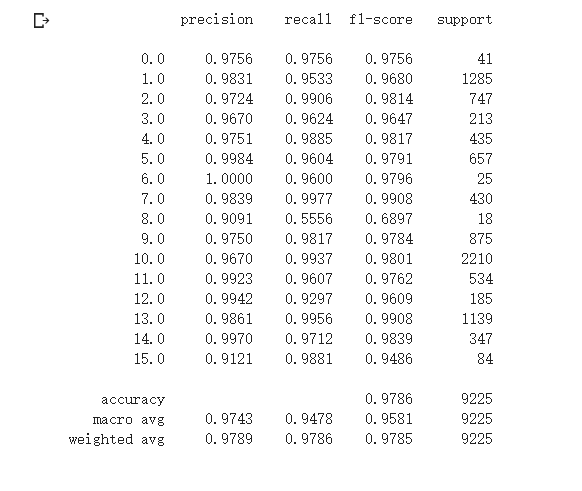
从以上两图可以看到第二个图得到的结果明显好于第一个图。
SENet 实现
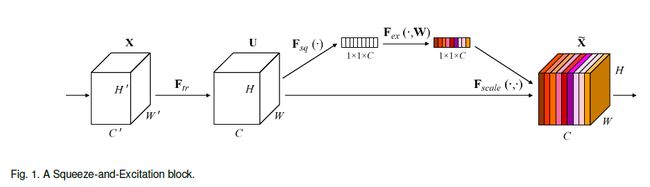
SE模块首先对卷积得到的特征图进行Squeeze操作,得到channel级的全局特征,然后对全局特征进行Excitation操作,学习各个channel间的关系,也得到不同channel的权重,最后乘以原来的特征图得到最终特征。本质上,SE模块是在channel维度上做attention或者gating操作,这种注意力机制让模型可以更加关注信息量最大的channel特征,而抑制那些不重要的channel特征。
将SE模块添加到上述HybridSN网络后面两个2D卷积中,添加的SE模块及修改后的HybridSN网络:
class_num = 16 class SEBlock(nn.Module): def __init__(self,channel,r=16): super(SEBlock,self).__init__() self.avg_pool = nn.AdaptiveAvgPool2d(1) self.fc1 = nn.Linear(channel,round(channel/r)) self.fc2 = nn.Linear(round(channel/r),channel) def forward(self,x): out = self.avg_pool(x) out = out.view(out.shape[0],-1) out = F.relu(self.fc1(out)) out = F.sigmoid(self.fc2(out)) out = out.view(x.shape[0],x.shape[1],1,1) out = x * out return out class HybridSN(nn.Module): def __init__(self): super(HybridSN,self).__init__() self.conv1 = nn.Conv3d(1,8,kernel_size=(7,3,3),stride=1,padding=0) self.bn1 = nn.BatchNorm3d(8) self.conv2 = nn.Conv3d(8,16,kernel_size=(5,3,3),stride=1,padding=0) self.bn2 = nn.BatchNorm3d(16) self.conv3 = nn.Conv3d(16,32,kernel_size=(3,3,3),stride=1,padding=0) self.bn3 = nn.BatchNorm3d(32) self.conv4 = nn.Conv2d(576,64,kernel_size=(3,3),stride=1,padding=0) self.SElayer = SEBlock(64,16) self.bn4 = nn.BatchNorm2d(64) self.fc1 = nn.Linear(18496,256) self.fc2 = nn.Linear(256,128) self.fc3 = nn.Linear(128,16) self.dropout = nn.Dropout(0.4) def forward(self,x): out = F.relu(self.bn1(self.conv1(x))) out = F.relu(self.bn2(self.conv2(out))) out = F.relu(self.bn3(self.conv3(out))) out = out.reshape(out.shape[0],-1,19,19) out = F.relu(self.bn4(self.conv4(out))) out = self.SElayer(out) out = out.reshape(out.shape[0],-1) out = F.relu(self.dropout(self.fc1(out))) out = F.relu(self.dropout(self.fc2(out))) out = self.fc3(out) return out
上述测试结果为:
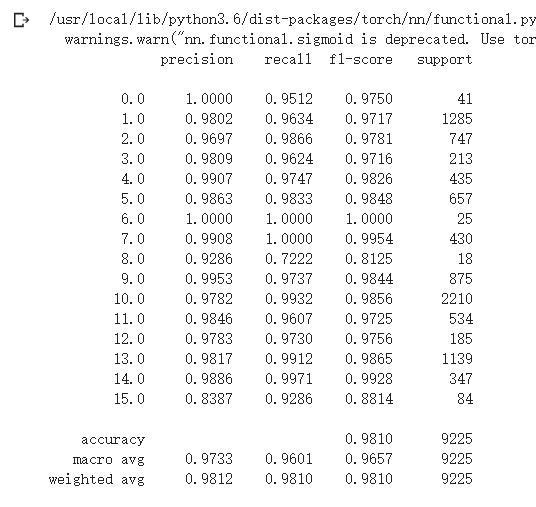
加入SEnet网络相对于没加的HybridSN 高光谱分类网络在结果上又有了提高。
从上周的0.9476提升到了0.9786再到现在的0.9810
视频学习部分:
《语义分割中的自注意力机制和低秩重重建》
语义分割是计算机视觉领域的一项基础任务,它的目标是为每个像素预测类别标签。由于类别多样繁杂,且类间表征相似度大,语义分割要求模型具有强大的区分能力。近年来,基于全卷积网络的一系列研究,在该任务上取得了卓越的成绩。这些语义分割网络,由骨干网络和语义分割头组成。全卷积网络受制于较小的有效感知域,无法充分捕获长距离信息。为弥补这一缺陷,诸多工作提出提出了高效的多尺度上下文融合模块,例如全局池化层、Deeplab的空洞空间卷积池化金字塔、PSPNet的金字塔池化模块等。近年来,自注意力机制在自然语言处理领域取得卓越成果。Nonlocal被提出后,在计算机视觉领域也受到了广泛的关注,并被一系列文章证明了在语义分割中的有效性。它使得每个像素可以充分捕获全局信息。然而,自注意力机制需要生成一个巨大的注意力图,其空间复杂度和时间复杂度巨大。其瓶颈在于,每一个像素的注意力图都需要对全图计算。本文所提出的期望最大化注意力机制(EMA),摒弃了在全图上计算注意力图的流程,转而通过期望最大化(EM)算法迭代出一组紧凑的基,在这组基上运行注意力机制,从而大大降低了复杂度。其中,E步更新注意力图,M步更新这组基。E、M交替执行,收敛之后用来重建特征图。本文把这一机制嵌入网络中,构造出轻量且易实现的EMA Unit。其作为语义分割头,在多个数据集上取得了较高的精度。
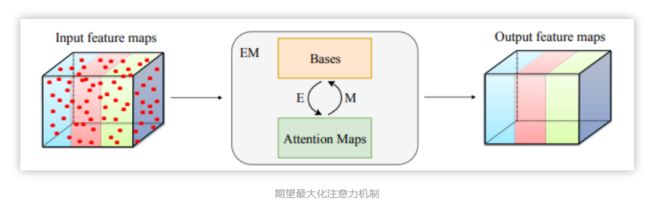
从微信公众号上看到的一张图片用于拓展:


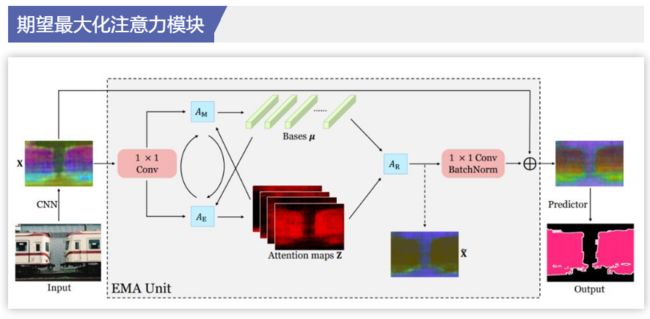
《图像语义分割前沿进展》
从卷积层的角度出发来提高卷积神经网络多尺度能力

右边这个图看起来比左边的复杂,但是实际计算量来说右图相对于左图来说有了大大的降低,运行速度更快。
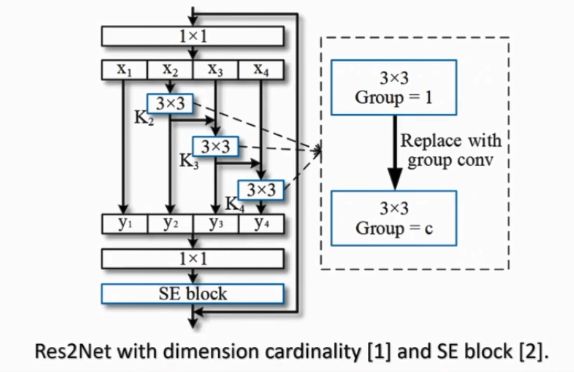
其优点为可以与其他类型神经网络兼容。
其特征的提取能力都有所增强,错误率也较其他方法有明显的下降。
从池化出发提高卷积神经网络多尺度能力
图像语义分割既需要细节又需要全局信息。
传统神经网络对细节信息提取较好,但对全局信息来说消耗资源非常多。
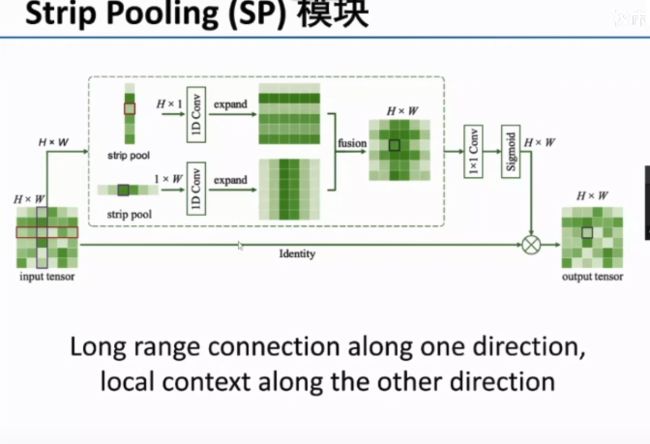
带状池化:使用条形的Pooling,可以得到各向异性的信息。