TensorFlow学习笔记6----tf.contrib.learn Quickstart
原文教程:tensorflow官方教程
记录关键内容与学习感受。未完待续。。
tf.contrib.learn 快速介绍
——tf.contrib.learn是tensorflow高级别的机器学习API,它可以很轻松安装、训练、验证多种类的机器学习模型。在本教程中,你可以使用它来构建一个神经网络分类器并且利用Iris CSV数据训练,基于花萼、花瓣的几何形状来预测花的种类。
——你可以按照以下五步写下代码:
- 加载包含了训练数据和测试数据的Iris CSV数据集到tensorflow Dataset。
- 构建一个神经网络分类器
- 使用训练数据使模型适合数据
- 验证模型的正确度
- 新样本分类
1、完整的神经网络源代码
——这是神经网络的全部代码:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
import numpy as np
#Data sets
IRIS_TRAINING ="iris_training.csv"
IRIS_TEST = "iris_test.csv"
# load datasets
training_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename = IRIS_TRAINING,
target_dtype = np.int,
features_dtype = np.float32
)
test_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename = IRIS_TEST,
target_dtype = np.int,
features_dtype = np.float32
)
# specify that all features have real-value data
feature_columns = [tf.contrib.layers.real_valued_column("",dimension=4)]
# build 3 layer dnn with 10,20,10 units respectively.
classifier = tf.contrib.learn.DNNClassifier(
feature_columns = feature_columns,
hidden_units = [10,20,10],
n_classes = 3,
model_dir = "/tmp/iris_model"
)
# fit model
classifier.fit(
x = training_set.data,
y = training_set.target,
steps = 2000
)
# evaluate accuracy
accuracy_score = classifier.evaluate(
x = test_set.data,
y = test_set.target
)["accuracy"]
print('Accuracy:{0:f}'.format(accuracy_score))
# classify two new flower samples
new_samples = np.array(
[[6.4, 3.2, 4.5, 1.5], [5.8, 3.1, 5.0, 1.7]],
dtype = float
)
y = list(classifier.predict(new_samples, as_iterable=True))
print('Prediction:{}'.format(str(y)))——以下部分是对代码的详细介绍。
2、加载Iris CSV数据到tensorflow
——Iris data set包含了150行数据,由三种鸢尾花,每种50个样本构成,分别是Iris setosa, Iris virginica, and Iris versicolor。可见下图:

——从左到右,Iris setosa (by Radomil, CC BY-SA 3.0), Iris versicolor(by Dlanglois, CC BY-SA 3.0), and Iris virginica (by Frank Mayfield, CC BY-SA 2.0).
——-每一行包含了对于每个花样本的以下数据:花萼长度、花萼宽度、花瓣长度、花瓣宽度、花的种类。花的种类用一个整数表示:0表示Iris setosa,1表示Iris versicolor,2表示Iris virginica。
| Sepal Length | Sepal Width | Petal Length | Petal Width | Species |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 4.9 | 3.0 | 1.4 | 0.2 | 0 |
| 4.7 | 3.2 | 1.3 | 0.2 | 0 |
| … | … | … | … | … |
| 7.0 | 3.2 | 4.7 | 1.4 | 1 |
| 6.4 | 3.2 | 4.5 | 1.5 | 1 |
| 6.9 | 3.1 | 4.9 | 1.5 | 1 |
| … | … | … | … | … |
| 6.5 | 3.0 | 5.2 | 2.0 | 2 |
| 6.2 | 3.4 | 5.4 | 2.3 | 2 |
| 5.9 | 3.0 | 5.1 | 1.8 | 2 |
.
——对于本教程,iris 数据进行随机排列并分成两个csv文件:
- 包含120个样本的训练数据集(iris_training.csv)
- 包含30个样本的测试数据集(iris_test.csv)
——把这些文件放在与你的代码同一个文件夹下。
——为了开始,首先要引入tensorflow和numpy模块。
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
import numpy as np——接下来,使用learn.datasets.base中的load_csv_with_header()方法加载训练数据集和测试数据集到Datasets。load_csv_with_header()方法有三个参数:
- filename:获取csv文件路径。
- target_dtype:取出数据集的目标值的numpy datatype。
- features_dtype:取出数据集的特征值的numpy datatype。
——这里,目标(你训练模型预测的值)是花的种类,它是0-2之间的整数,因此合适的numpy类型是np.int:
#Data sets
IRIS_TRAINING ="iris_training.csv"
IRIS_TEST = "iris_test.csv"
# load datasets
training_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename = IRIS_TRAINING,
target_dtype = np.int,
features_dtype = np.float32
)
test_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename = IRIS_TEST,
target_dtype = np.int,
features_dtype = np.float32
)——Datasets在tf.contrib.learn中被称为元组(tuples),你可以通过数据和目标域获得特征数据和目标值。这里,training_set.data和training_set.target包括训练数据集的特征数据和目标值,test_set.data和test_set.target包括测试数据集的特征数据和目标值。
——后面,在将DNN分类器适应于Iris CSV数据这一节,你可以使用training_set.data 和training_set.target训练你的模型,在验证模型正确度一节,你将使用test_set.data 和test_set.target测试模型。但是首先你需要在下一节中构建你的模型。
3、构建深度神经网络分类器
——tf.contrib.learn提供各种已经预定义好的模型,称为Estimators,你可以直接使用它,在你的数据上跑训练和测试的操作。这里,你可以构建一个深度神经网络分类器模型去适应iris数据。使用tf.contrib.learn,你可以只用几行代码就能直接实例化你的DNN分类器。
# specify that all features have real-value data
feature_columns = [tf.contrib.layers.real_valued_column("",dimension=4)]
# build 3 layer dnn with 10,20,10 units respectively.
classifier = tf.contrib.learn.DNNClassifier(
feature_columns = feature_columns,
hidden_units = [10,20,10],
n_classes = 3,
model_dir = "/tmp/iris_model"
)——以上代码,首先定义了模型的特征列,指定在数据集中特征的数据类型。所有的特征数据是连续的,因此tf.contrib.layers.real_valued_column对于构建特征列来说是个合适的函数。在数据集中有四个特征(花萼宽度、花萼长度、花瓣宽度、花瓣长度),因此维度是4来存放数据。
——接着代码使用以下参数创建了DNN分类器:
- feature_columns=feature_columns:前面定义的特征列的集合。
- hidden_units=[10, 20, 10]:三个隐藏层,每层各有10、20、10个神经元。
- n_classes=3:三个目标类别,分别代表三种鸢尾花类别。
- model_dir=/tmp/iris_model:在模型训练过程中,tensorflow保存的检查点数据的路径。更多关于tensorflow日志和监督的问题,可以查看Logging and Monitoring Basics with
tf.contrib.learn。
4、将DNN分类器适应于Iris CSV数据
——现在你已经构建了你的DNN分类器模型,你可以使用fit方法将其适用于iris训练数据。方法的参数分别是你的特征数据(training_set.data)、目标值(training_set.target)、训练的步数(这里是2000)。
# fit model
classifier.fit(
x = training_set.data,
y = training_set.target,
steps = 2000
)——模型的状态保存在分类器中,这意味着只要你喜欢,你可以反复迭代训练。上面的代码可以等同于下面的代码:
classifier.fit(
x = training_set.data,
y = training_set.target,
steps = 1000
classifier.fit(
x = training_set.data,
y = training_set.target,
steps = 1000——然而如果你想训练时跟踪模型,你可以使用一个tensorflow的monitor来执行日志操作。更多信息参见“Logging and Monitoring
Basics with tf.contrib.learn”。
5、验证模型正确度
——你已经将DNN分类器适应于Iris CSV数据,现在你需要使用evaluate方法来检查在iris测试数据上的正确度。这个方法像fit, evaluate这些函数一样,将特征数据和目标值作为参数,并且它还返回一个验证结果的字典。下面代码执行了 Iris 测试数据的test_set.data 和test_set.target来验证和打印结果的正确度。
# evaluate accuracy
accuracy_score = classifier.evaluate(
x = test_set.data,
y = test_set.target
)["accuracy"]
print('Accuracy:{0:f}'.format(accuracy_score))——运行所有的脚本,并且检查结果的正确度,
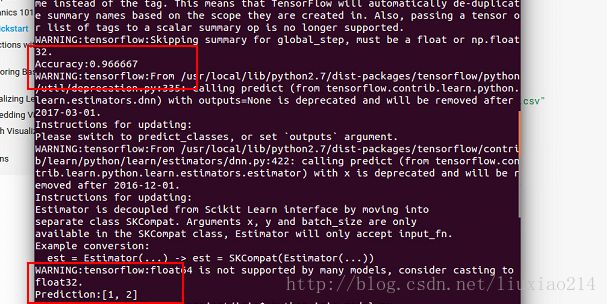
Accuracy: 0.966667——-你的结果的正确度可能会有点不同,但应该比90%高,这对于一个相对较小的数据集来说不算太坏。
6、新样本分类
——使用评估者的预测方法来分类新的样本。例如,你有两个新的花的样本:
| Sepal Length | Sepal Width | Petal Length | Petal Width |
|---|---|---|---|
| 6.4 | 3.2 | 4.5 | 1.5 |
| 5.8 | 3.1 | 5.0 | 1.7 |
.
——你使用一下代码来预测他们的分类:
# classify two new flower samples
new_samples = np.array(
[[6.4, 3.2, 4.5, 1.5], [5.8, 3.1, 5.0, 1.7]],
dtype = float
)
y = list(classifier.predict(new_samples, as_iterable=True))
print('Prediction:{}'.format(str(y)))——predict()方法返回一个预测的数组,包含对每个样本的预测:
Prediction: [1 2]——因此,这个模型预测样本一是Iris versicolor,样本二是Iris virginica。
7、其他资源
——关于tf.contrib.learn更多的参考资料,参见API docs。
——-其他还有很多资源,官网可看。
8、实际运行
——首先,获取训练数据和测试数据的文件,可从以下网址下载。下载完成后与代码文件放在同一文件下。
- 训练数据
- 测试数据
——运行结果:
——以下,本课程结束。