python常用函数及方法解释
1.sort()
描述:
sort() 函数用于对原列表进行排序,如果指定参数,则使用比较函数指定的比较函数。
语法:
list
.
sort
(
key
=
None
,
reverse
=
False
)
key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
reverse -- 排序规则,
reverse = True 降序,
reverse = False 升序(默认)。
返回值:
该方法没有返回值,但是会对列表的对象进行排序
实例:
#!/usr/bin/python aList = ['Google', 'Runoob', 'Taobao', 'Facebook'] aList.sort() print ( "List : ", aList)
List : ['Facebook', 'Google', 'Runoob', 'Taobao']
2.list 切片:左闭右开
# 从0开始索引列表,索引值为整数
>>> a = list(range(10)) # 定义列表a
>>> a
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> a[:] # 复制列表
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> a[0:] # 从索引为0的列表元素开始迭代列表至列表结束
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> a[1:] # 从索引为1的列表元素开始迭代列表至列表结束
[1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> a[:9] # 从索引为0的列表元素开始迭代列表至索引为8的列表元素,不包含索引为9的列表元素
[0, 1, 2, 3, 4, 5, 6, 7, 8]
>>> a[3:5] # 从索引为3的列表元素开始迭代列表至索引为4的列表元素,不包含索引为5的列表元素
[3, 4]
>>> a[::1] # 从索引为0的列表元素开始索引列表,每次迭代索引值加1,直至列表结束
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> a[::2] # 从索引为0的列表元素开始索引列表,每次迭代索引值加2,直至列表结束
[0, 2, 4, 6, 8]
>>> a[3:9:2] # 从索引为3的列表元素开始索引列表,每次迭代索引值加2,直至索引为8的列表元素,不包含索引为9的列表元素
[3, 5, 7]
# 当索引值为负数时
>>> a[-1] # 列表的最后一个元素
9
>>> a[-2:] # 从列表的倒数第二个元素直至列表结束,即从索引值为-2的元素直至列表结束
[8, 9]
>>> a[:-1] # 从列表的第一个元素直至列表的倒数第二个元素结束,不包含最后一个列表元素
[0, 1, 2, 3, 4, 5, 6, 7, 8]
>>> a[:-2] # 从列表的第一个元素直至列表的倒数第三个元素结束,不包含最后两个个列表元素
[0, 1, 2, 3, 4, 5, 6, 7]
# 当step为负值时,表示逆向索引列表
>>> a[::-1] # 反转列表,从列表最后一个元素到列表的第一个元素
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
>>> a[1::-1] # 从索引值为1的列表元素开始,逆向索引直列表开头
[1, 0]
>>> a[-3::-1] # 从索引值为-3的列表元素开始,逆向索引直列表开头
[7, 6, 5, 4, 3, 2, 1, 0]
>>> a[:-3:-1] # 从索引值为-1,逆向索引直索引为-2的元素结束,不包含索引为-3的元素
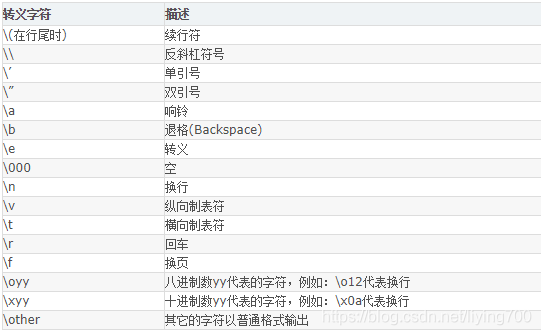
[9, 8]3.python 转义字符
4.Random()函数
描述:
random()
方法返回随机生成的一个实数,它在[0,1)范围内。
语法:
import random
random.random()
注意:
random()是不能直接访问的,需要导入 random 模块,然后通过 random 静态对象调用该方法。
返回值:
返回随机生成的一个实数,它在[0,1)范围内。
实例:
#!/usr/bin/python # -*- coding: UTF-8 -*-
import random # 生成第一个随机数 print "random() : ", random.random()
# 生成第二个随机数 print "random() : ", random.random()#!/usr/bin/python
# -*- coding: UTF-8 -*-
import random
print( random.randint(1,10) ) # 产生 1 到 10 的一个整数型随机数
print( random.random() ) # 产生 0 到 1 之间的随机浮点数
print( random.uniform(1.1,5.4) ) # 产生 1.1 到 5.4 之间的随机浮点数,区间可以不是整数
print( random.choice('tomorrow') ) # 从序列中随机选取一个元素
print( random.randrange(1,100,2) ) # 生成从1到100的间隔为2的随机整数
a=[1,3,5,6,7] # 将序列a中的元素顺序打乱
random.shuffle(a)
print(a)random中的一些重要函数的用法:
1 )、random() 返回0<=n<1之间的随机实数n;
2 )、choice(seq) 从序列seq中返回随机的元素;
3 )、getrandbits(n) 以长整型形式返回n个随机位;
4 )、shuffle(seq[, random]) 原地指定seq序列;
5 )、sample(seq, n) 从序列seq中选择n个随机且独立的元素;
5.字符串
strip 用于去除字符串前后的空格:
In [1]: ' I love python\t\n '.strip()
Out[1]: 'I love python'
replace 用于字符串的替换:
In [2]: 'i love python'.replace(' ','_')
Out[2]: 'i_love_python'
join 用于合并字符串:
In [3]: '_'.join(['book', 'store','count'])
Out[3]: 'book_store_count'
title 用于单词的首字符大写:
In [4]: 'i love python'.title()
Out[4]: 'I Love Python'
find 用于返回匹配字符串的起始位置索引:
In [5]: 'i love python'.find('python')
Out[5]: 76.re.compile
re模块中包含一个重要函数是compile(pattern [, flags]) ,该函数根据包含的正则表达式的字符串创建模式对象。可以实现更有效率的匹配。在直接使用字符串表示的正则表达式进行search,match和findall操作时,python会将字符串转换为正则表达式对象。而使用compile完成一次转换之后,在每次使用模式的时候就不用重复转换。当然,使用re.compile()函数进行转换后,re.search(pattern, string)的调用方式就转换为 pattern.search(string)的调用方式。
其中,后一种调用方式中,pattern是用compile创建的模式对象。如下:
import re
some_text = 'a,b,,,,c d'
reObj = re.compile('[, ]+')
reObj.split(some_text)
['a', 'b', 'c', 'd']
7.set()
描述:set() 函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。
语法:class set([iterable])
参数说明:iterable -- 可迭代对象对象;
返回值:返回新的集合对象。
x = set('runoob')
y = set('google')
x, y
(set(['b', 'r', 'u', 'o', 'n']), set(['e', 'o', 'g', 'l'])) # 重复的被删除
x & y # 交集
set(['o'])
x | y # 并集
set(['b', 'e', 'g', 'l', 'o', 'n', 'r', 'u'])
x - y # 差集
set(['r', 'b', 'u', 'n'])