tensorflow cats vs dogs
作为一个萌新,跟随网易云课堂的课程和参考博客做了cats vs dogs 项目,现在做个总结
网易云课堂网址:https://mooc.study.163.com/course/2001396000#/info
参考该博客的读入数据:https://blog.csdn.net/lin453701006/article/details/79402976
数据集:https://www.kaggle.com/c/dogs-vs-cats/data
该项目要求对12500张猫的图片和12500张狗的图片进行区分。项目的总体框架类同全连接神经网络 读入数据 建立网络模型 使用优化器优化 得到模型。
读入模型,图片的标签在图的名字里,如一张猫的图片命名为cat.1.jpg 图片分批次读入,根据命名建立标签集与之一一对应。图片处理时用了网上的包,自己处理的话可以通过裁剪和填充将图片shape变为(224.224.3) 224为vdd16模型输入的图片尺寸,3为通道数,为rgb颜色 标签则得转换为独热编码

cat.1.jpg => [0,1]
建立模型,用的是vgg16模型,先简要介绍下卷积神经网络 ,参考博客https://blog.csdn.net/weixin_42451919/article/details/81381294
卷积神经网络将输入的图片用filter卷积,再进行池化降纬度,将得到的矩阵变为一维特征集,连接全连接神经网络输出预测结果。
卷积层核心代码为 tf.nn.conv2d(input_data,kernel,[1,1,1,1],padding="SAME"),input_data 是输入数据,四维,分别表示数据ID,图片长宽,通道数。如{1,224,224,3]表示第一张图片,shape=[224,224,3]的RGB图片。kernel为filter的大小,也是四维,分别是行列,输入数据通道数,输出通道数。如[3,3,3,64],第三个3接收通道数为3的RGB图片,64表示filter数量,也是输出的通道数。 接下来是步长,四维,一一对应input_data的四维,表示移动的距离,通常第一个1和最后的1固定,毕竟ID和通道移动多步没意义,中间的是在图片上移动,若要移动2个距离,可改为【1,2,2,1】。最后是填充,指是否在图片周围填充一圈0,可以更好读取图片边缘的特征。padding 有两个参数,‘SAME' 和’VALID' ‘SAME'表示填充,’VALID'不填充,可能丢失数据。(个人观点:都在图片边角了也不会是什么重要特征,而且丢一点点数据万一还能防过拟合呢)
池化层分为最大池化和平均池化,池化范围通常2*2 最大池化指在2*2范围内选取最大值,平均池化是选取平均值。
| 1 | 2 | 3 | 4 |
| 8 | 7 | 6 | 5 |
| 4 | 3 | 2 | 1 |
| 1 | 2 | 3 | 4 |
最大池化结果:
| 8 | 6 |
| 4 | 6 |
平均池化结果:
| 4.5 | 4.5 |
| 2.5 | 2.5 |
池化能降维,凸现特征,防止过拟合。代码为tf.nn.max_pool(input_data,[1,2,2,1],[1,2,2,1],padding='SAME',name=name),第二个表示池化大小,第三个表示步长。
vgg16进行了5次卷积池化,采用三层全连接层,可以做到对1000样物品进行分类。具体看图。
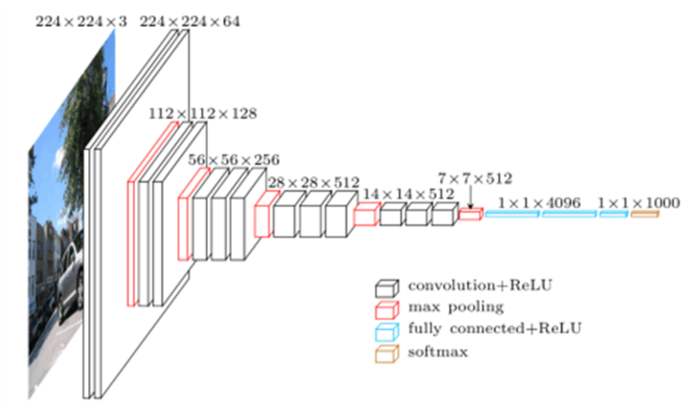
个人理解是把图片化为224*224*3,然后卷积,池化,卷积,池化共5次,最后化为一维共4096个特征,再使用三层全连接神经网络进行预测。
项目中采用了迁移学习,vgg16网上已经有训练数据,可以使用网上数据填充,大大降低训练时间。不然我的电脑跑个一天也不会出结果。填充后vgg16模型中其他几层的train able设为false表示不可训练,将全连接层最后一层设为true,指改变最后一层值,将千分类变为二分类
由于用cpu运行,跑的很慢,保存模型很重要。建议迭代一次保存一次,因为在多线程下我跑一次还要十几分钟,并且跑一次输出loss值和准确率。 准确率是在训练集上随机抽取30张狗图片和30张猫图片用于计算模型的准确率。
跑的时候出现很多问题,所以代码中有许多注释,通过注释中的代码让我找到了很多BUG。
cats vs dogs
import tensorflow as tf
import numpy as np
import pandas as pd
import os
import vgg16_model as model
import utils2
from time import time
tf.reset_default_graph()
startTime = time()
batch_size = 32
capacity = 256 #内存中存储的最大数据容量
means = [123.68,116.779,103.939] #vgg训练图像预处理所减均值(RGB)
filepath = 'C:\\Users\\ASUS\\Desktop\\python\\data\\dogs-vs-cats\\train\\train\\'
image_list,label_list = utils2.get_files(filepath)
image_batch,label_batch = utils2.get_batch(image_list,label_list,224,224,batch_size,capacity)
filepath1 = 'C:\\Users\\ASUS\\Desktop\\python\\data\\dogs-vs-cats\\train\\train1\\'
image_test,label_test = utils2.get_files(filepath1)
image_batchte,label_batchte = utils2.get_batch(image_test,label_test,224,224,batch_size,capacity)
x = tf.placeholder(tf.float32,[None,224,224,3])
y = tf.placeholder(tf.float32,[None,2])
vgg = model.vgg16(x)
fc8_finetuining = vgg.probs #即sortmax(fc8) predict
cont = tf.equal(tf.argmax(fc8_finetuining,1),tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(cont,tf.float32))
loss_function = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=fc8_finetuining,labels=y))
variable_name = [v.name for v in tf.trainable_variables()]
print(variable_name)
'''
with tf.Session() as sess:
print("999999")
print(variable_name)
values = sess.run(variable_name)
for k,v in zip(variable_name,values):
print('Variable ',k)
print('shape ',v.shape)
print(v)
'''
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001).minimize(loss_function)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
#通过npz格式的文件获取vgg的相应权重参数,从而将权重注入即可实现复用
vgg.load_weights('./vgg16_weights.npz',sess)
saver = tf.train.Saver()
print('load is ok-----------')
'''
ckpt_dir = "./model/"
ckpt = tf.train.get_checkpoint_state(ckpt_dir)
saver.restore(sess,ckpt.model_checkpoint_path)
'''
coord = tf.train.Coordinator() #使用协调器来管理线程
threads = tf.train.start_queue_runners(coord=coord,sess=sess) #启动线程
print('begin')
for i in range(2):
epoch_start_time = time()
images,labels = sess.run([image_batch,label_batch])
labels = utils2.onehot(labels) #独热处理
sess.run(optimizer,feed_dict={x:images,y:labels})
loss = sess.run(loss_function,feed_dict={x:images,y:labels})
test_img,test_labels = sess.run([image_batchte,label_batchte])
test_labels = utils2.onehot(test_labels)
acc = sess.run(accuracy,feed_dict={x:test_img,y:test_labels})
epoch_end_time = time()
if (i+1) % 1 ==0:
saver.save(sess,os.path.join("./model/",'epoch_{:06d}.ckpt'.format(i)))
print("epoch = ",i," loss = ",loss,'acc = ',acc)
print('time = ',epoch_end_time-epoch_start_time)
saver.save(sess,"./model/")
print('train finish')
coord.request_stop()#通知其他线程关闭
coord.join(threads)#join操作等待其他线程结束,着一函数才能返回
edtime = time()
print('total time = ',edtime - startTime)
util2
import numpy as np
import pandas as pd
import os
import tensorflow as tf
def get_files(file_dir):
cats = []
label_cats = []
dogs = []
label_dogs = []
for file in os.listdir(file_dir): #返回文件名
name = file.split(sep='.') #文件名按。分割
if name[0]=='cat':
cats.append(file_dir + file)
label_cats.append(0)
else:
dogs.append(file_dir + file)
label_dogs.append(1)
print('There are %d cats\nThere are %d dogs'%(len(cats),len(dogs)))
image_list = np.hstack((cats,dogs)) #上下连接
#print(image_list)
label_list = np.hstack((label_cats,label_dogs))
#print(label_list)
temp = np.array([image_list,label_list])
temp = temp.transpose() #置换数组的维度 转置
#print(temp)
np.random.shuffle(temp) #打乱图片
print(temp)
image_list = list(temp[:,0])
label_list = list(temp[:,1])
#print(label_list)
label_list = [int(i) for i in label_list] #转成int
#print(label_list)
return image_list,label_list
from vgg_preprocess import preprocess_for_train
def get_batch(image,label,image_w,image_h,batch_size,capacity):
'''
Args:
image:list type
label:list type
image_w:image width
image_h:image height
batch_size:batch size
capacity:the maximum elements in queue
Returns:
image_batch:4D tensor[batch_size,width,height,3],dtype=tf.float32
label_batch:1D tensor[batch_size],dtype=tf.int32
'''
#image和label 为list类型,转换为tensorflow可以识别的tensor格式
image = tf.cast(image,tf.string)
label = tf.cast(label,tf.int32)
#make an input queue 把 image 和 label 合并成一个队列
input_queue = tf.train.slice_input_producer([image,label])
label = input_queue[1] #读取label
image_contents = tf.read_file(input_queue[0]) #读取图片
'''
image = tf.image.decode_jpeg(image_contents,channels=3) #解码图片 通道为3(rgb) 灰度通道为1
#图片大小不一,进行裁剪/扩充
image = tf.image.resize_image_with_crop_or_pad(image,image_w,image_h)
#标准化
image = tf.image.per_image_standardization(image)
'''
image = tf.image.decode_jpeg(image_contents,channels = 3)
image = preprocess_for_train(image,224,224)
image = tf.nn.l2_normalize(image,dim = 0 )
#生成批次
image_batch,label_batch = tf.train.batch([image,label],
batch_size = batch_size,
num_threads=64,
capacity = capacity)
label_batch = tf.reshape(label_batch,[batch_size])
return image_batch,label_batch
def onehot(labels):
n_sample = len(labels)
n_class = max(labels)+1
onehot_labels = np.zeros((n_sample,n_class))
onehot_labels[np.arange(n_sample),labels] = 1
return onehot_labels
vgg_preprocess.py 这是网上的对图片处理的代码
"""Provides utilities to preprocess images.
The preprocessing steps for VGG were introduced in the following technical
report:
Very Deep Convolutional Networks For Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman
arXiv technical report, 2015
PDF: http://arxiv.org/pdf/1409.1556.pdf
ILSVRC 2014 Slides: http://www.robots.ox.ac.uk/~karen/pdf/ILSVRC_2014.pdf
CC-BY-4.0
More information can be obtained from the VGG website:
www.robots.ox.ac.uk/~vgg/research/very_deep/
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
slim = tf.contrib.slim
_R_MEAN = 123.68
_G_MEAN = 116.78
_B_MEAN = 103.94
_RESIZE_SIDE_MIN = 256
_RESIZE_SIDE_MAX = 512
def _crop(image, offset_height, offset_width, crop_height, crop_width):
"""Crops the given image using the provided offsets and sizes.
Note that the method doesn't assume we know the input image size but it does
assume we know the input image rank.
Args:
image: an image of shape [height, width, channels].
offset_height: a scalar tensor indicating the height offset.
offset_width: a scalar tensor indicating the width offset.
crop_height: the height of the cropped image.
crop_width: the width of the cropped image.
Returns:
the cropped (and resized) image.
Raises:
InvalidArgumentError: if the rank is not 3 or if the image dimensions are
less than the crop size.
"""
original_shape = tf.shape(image)
rank_assertion = tf.Assert(
tf.equal(tf.rank(image), 3),
['Rank of image must be equal to 3.'])
with tf.control_dependencies([rank_assertion]):
cropped_shape = tf.stack([crop_height, crop_width, original_shape[2]])
size_assertion = tf.Assert(
tf.logical_and(
tf.greater_equal(original_shape[0], crop_height),
tf.greater_equal(original_shape[1], crop_width)),
['Crop size greater than the image size.'])
offsets = tf.to_int32(tf.stack([offset_height, offset_width, 0]))
# Use tf.slice instead of crop_to_bounding box as it accepts tensors to
# define the crop size.
with tf.control_dependencies([size_assertion]):
image = tf.slice(image, offsets, cropped_shape)
return tf.reshape(image, cropped_shape)
def _random_crop(image_list, crop_height, crop_width):
"""Crops the given list of images.
The function applies the same crop to each image in the list. This can be
effectively applied when there are multiple image inputs of the same
dimension such as:
image, depths, normals = _random_crop([image, depths, normals], 120, 150)
Args:
image_list: a list of image tensors of the same dimension but possibly
varying channel.
crop_height: the new height.
crop_width: the new width.
Returns:
the image_list with cropped images.
Raises:
ValueError: if there are multiple image inputs provided with different size
or the images are smaller than the crop dimensions.
"""
if not image_list:
raise ValueError('Empty image_list.')
# Compute the rank assertions.
rank_assertions = []
for i in range(len(image_list)):
image_rank = tf.rank(image_list[i])
rank_assert = tf.Assert(
tf.equal(image_rank, 3),
['Wrong rank for tensor %s [expected] [actual]',
image_list[i].name, 3, image_rank])
rank_assertions.append(rank_assert)
with tf.control_dependencies([rank_assertions[0]]):
image_shape = tf.shape(image_list[0])
image_height = image_shape[0]
image_width = image_shape[1]
crop_size_assert = tf.Assert(
tf.logical_and(
tf.greater_equal(image_height, crop_height),
tf.greater_equal(image_width, crop_width)),
['Crop size greater than the image size.'])
asserts = [rank_assertions[0], crop_size_assert]
for i in range(1, len(image_list)):
image = image_list[i]
asserts.append(rank_assertions[i])
with tf.control_dependencies([rank_assertions[i]]):
shape = tf.shape(image)
height = shape[0]
width = shape[1]
height_assert = tf.Assert(
tf.equal(height, image_height),
['Wrong height for tensor %s [expected][actual]',
image.name, height, image_height])
width_assert = tf.Assert(
tf.equal(width, image_width),
['Wrong width for tensor %s [expected][actual]',
image.name, width, image_width])
asserts.extend([height_assert, width_assert])
# Create a random bounding box.
#
# Use tf.random_uniform and not numpy.random.rand as doing the former would
# generate random numbers at graph eval time, unlike the latter which
# generates random numbers at graph definition time.
with tf.control_dependencies(asserts):
max_offset_height = tf.reshape(image_height - crop_height + 1, [])
with tf.control_dependencies(asserts):
max_offset_width = tf.reshape(image_width - crop_width + 1, [])
offset_height = tf.random_uniform(
[], maxval=max_offset_height, dtype=tf.int32)
offset_width = tf.random_uniform(
[], maxval=max_offset_width, dtype=tf.int32)
return [_crop(image, offset_height, offset_width,
crop_height, crop_width) for image in image_list]
def _central_crop(image_list, crop_height, crop_width):
"""Performs central crops of the given image list.
Args:
image_list: a list of image tensors of the same dimension but possibly
varying channel.
crop_height: the height of the image following the crop.
crop_width: the width of the image following the crop.
Returns:
the list of cropped images.
"""
outputs = []
for image in image_list:
image_height = tf.shape(image)[0]
image_width = tf.shape(image)[1]
offset_height = (image_height - crop_height) / 2
offset_width = (image_width - crop_width) / 2
outputs.append(_crop(image, offset_height, offset_width,
crop_height, crop_width))
return outputs
def _mean_image_subtraction(image, means):
"""Subtracts the given means from each image channel.
For example:
means = [123.68, 116.779, 103.939]
image = _mean_image_subtraction(image, means)
Note that the rank of `image` must be known.
Args:
image: a tensor of size [height, width, C].
means: a C-vector of values to subtract from each channel.
Returns:
the centered image.
Raises:
ValueError: If the rank of `image` is unknown, if `image` has a rank other
than three or if the number of channels in `image` doesn't match the
number of values in `means`.
"""
if image.get_shape().ndims != 3:
raise ValueError('Input must be of size [height, width, C>0]')
num_channels = image.get_shape().as_list()[-1]
if len(means) != num_channels:
raise ValueError('len(means) must match the number of channels')
channels = tf.split(axis=2, num_or_size_splits=num_channels, value=image)
for i in range(num_channels):
channels[i] -= means[i]
return tf.concat(axis=2, values=channels)
def _smallest_size_at_least(height, width, smallest_side):
"""Computes new shape with the smallest side equal to `smallest_side`.
Computes new shape with the smallest side equal to `smallest_side` while
preserving the original aspect ratio.
Args:
height: an int32 scalar tensor indicating the current height.
width: an int32 scalar tensor indicating the current width.
smallest_side: A python integer or scalar `Tensor` indicating the size of
the smallest side after resize.
Returns:
new_height: an int32 scalar tensor indicating the new height.
new_width: and int32 scalar tensor indicating the new width.
"""
smallest_side = tf.convert_to_tensor(smallest_side, dtype=tf.int32)
height = tf.to_float(height)
width = tf.to_float(width)
smallest_side = tf.to_float(smallest_side)
scale = tf.cond(tf.greater(height, width),
lambda: smallest_side / width,
lambda: smallest_side / height)
new_height = tf.to_int32(height * scale)
new_width = tf.to_int32(width * scale)
return new_height, new_width
def _aspect_preserving_resize(image, smallest_side):
"""Resize images preserving the original aspect ratio.
Args:
image: A 3-D image `Tensor`.
smallest_side: A python integer or scalar `Tensor` indicating the size of
the smallest side after resize.
Returns:
resized_image: A 3-D tensor containing the resized image.
"""
smallest_side = tf.convert_to_tensor(smallest_side, dtype=tf.int32)
shape = tf.shape(image)
height = shape[0]
width = shape[1]
new_height, new_width = _smallest_size_at_least(height, width, smallest_side)
image = tf.expand_dims(image, 0)
resized_image = tf.image.resize_bilinear(image, [new_height, new_width],
align_corners=False)
resized_image = tf.squeeze(resized_image)
resized_image.set_shape([None, None, 3])
return resized_image
def preprocess_for_train(image,
output_height,
output_width,
resize_side_min=_RESIZE_SIDE_MIN,
resize_side_max=_RESIZE_SIDE_MAX):
"""Preprocesses the given image for training.
Note that the actual resizing scale is sampled from
[`resize_size_min`, `resize_size_max`].
Args:
image: A `Tensor` representing an image of arbitrary size.
output_height: The height of the image after preprocessing.
output_width: The width of the image after preprocessing.
resize_side_min: The lower bound for the smallest side of the image for
aspect-preserving resizing.
resize_side_max: The upper bound for the smallest side of the image for
aspect-preserving resizing.
Returns:
A preprocessed image.
"""
resize_side = tf.random_uniform(
[], minval=resize_side_min, maxval=resize_side_max+1, dtype=tf.int32)
image = _aspect_preserving_resize(image, resize_side)
image = _random_crop([image], output_height, output_width)[0]
image.set_shape([output_height, output_width, 3])
image = tf.to_float(image)
image = tf.image.random_flip_left_right(image)
return _mean_image_subtraction(image, [_R_MEAN, _G_MEAN, _B_MEAN])
def preprocess_for_eval(image, output_height, output_width, resize_side):
"""Preprocesses the given image for evaluation.
Args:
image: A `Tensor` representing an image of arbitrary size.
output_height: The height of the image after preprocessing.
output_width: The width of the image after preprocessing.
resize_side: The smallest side of the image for aspect-preserving resizing.
Returns:
A preprocessed image.
"""
image = _aspect_preserving_resize(image, resize_side)
image = _central_crop([image], output_height, output_width)[0]
image.set_shape([output_height, output_width, 3])
image = tf.to_float(image)
return _mean_image_subtraction(image, [_R_MEAN, _G_MEAN, _B_MEAN])
def preprocess_image(image, output_height, output_width, is_training=False,
resize_side_min=_RESIZE_SIDE_MIN,
resize_side_max=_RESIZE_SIDE_MAX):
"""Preprocesses the given image.
Args:
image: A `Tensor` representing an image of arbitrary size.
output_height: The height of the image after preprocessing.
output_width: The width of the image after preprocessing.
is_training: `True` if we're preprocessing the image for training and
`False` otherwise.
resize_side_min: The lower bound for the smallest side of the image for
aspect-preserving resizing. If `is_training` is `False`, then this value
is used for rescaling.
resize_side_max: The upper bound for the smallest side of the image for
aspect-preserving resizing. If `is_training` is `False`, this value is
ignored. Otherwise, the resize side is sampled from
[resize_size_min, resize_size_max].
Returns:
A preprocessed image.
"""
if is_training:
return preprocess_for_train(image, output_height, output_width,
resize_side_min, resize_side_max)
else:
return preprocess_for_eval(image, output_height, output_width,
resize_side_min)vgg16_model.py
import tensorflow as tf
import numpy as np
import pandas as pd
class vgg16:
global out
def __init__(self,imgs):
self.parameters = [] #在类的初始化时加入全局列表,将所需共享的参数加载进来
self.imgs = imgs
self.convlayers()
self.fc_layers()
#模型输出
self.probs = tf.nn.softmax(self.fc8)#输出每个属于各个类别的概率
def maxpool(self,name,input_data):
'''
第一个【1,2,2,1】为池化大小,第一个和最后一个通常为1,中间表示2*2取最大值
第二个【1,2,2,1】为步长
'''
out = tf.nn.max_pool(input_data,[1,2,2,1],[1,2,2,1],padding='SAME',name=name)
return out
#卷积
def conv(self,name,input_data,out_channel,trainable=False): #trainable参数变动
in_channel = input_data.get_shape()[-1]
with tf.variable_scope(name):
ppp = tf.Variable('ppp',[2,2])
#filter 过滤器
kernel = tf.get_variable("weights",[3,3,in_channel,out_channel],dtype=tf.float32,trainable=False)#trainable参数变动
#偏置
biases = tf.get_variable("biases",[out_channel],dtype=tf.float32,trainable=False)#trainable参数变动
'''
卷积,
input_data 输入数据,四维,数据数量,行列 通道数
kernel 为过滤器 四维,行列,输入数据通道数,输出通道数(过滤器数量)
strides 步长 四维 对应input_data的四维,通常【1,2,2,1】
padding 边缘是否填充,‘SAME' 为填充
'''
conv_res = tf.nn.conv2d(input_data,kernel,[1,1,1,1],padding="SAME")
res = tf.nn.bias_add(conv_res,biases)
out = tf.nn.relu(res,name=name)
self.parameters += [kernel,biases] #将卷积层定义的参数加入列表
return out
def fc(self,name,input_data,out_channel,trainable=True):
shape = input_data.get_shape().as_list()
#全局,局部报错,用下面的过
#out = input_data
if len(shape)==4:
#将三维转为一维 表示全连接层神经元个数
size = shape[-1] * shape[-2] * shape[-3]
else:
size = shape[1]
input_data_flat = tf.reshape(input_data,[-1,size])
with tf.variable_scope(name):
weights = tf.get_variable(name='weights',shape=[size,out_channel],dtype=tf.float32,trainable=trainable)
biases = tf.get_variable(name='biases',shape=[out_channel],dtype=tf.float32,trainable=trainable)
res = tf.matmul(input_data_flat,weights)
out = tf.nn.relu(tf.nn.bias_add(res,biases))
self.parameters += [weights,biases] #将全连接层定义的参数保存
return out
def saver(self):
return tf.train.Saver()
def convlayers(self):
#conv1
self.conv1_1 = self.conv('conv1re_1',self.imgs,64,trainable=False)
self.conv1_2 = self.conv('conv1_2',self.conv1_1,64,trainable=False)
self.pool1 = self.maxpool('poolre1',self.conv1_2)
#conv2
self.conv2_1 = self.conv('conv2re_1',self.pool1,128,trainable=False)
self.conv2_2 = self.conv('conv2_2',self.conv2_1,128,trainable=False)
self.pool2 = self.maxpool('poolre2',self.conv2_2)
#conv3
self.conv3_1 = self.conv('conv3_1',self.pool2,256,trainable=False)
self.conv3_2 = self.conv('convrwe3_2',self.conv3_1,256,trainable=False)
self.conv3_3 = self.conv('convrew3_3',self.conv3_2,256,trainable=False)
self.pool3 = self.maxpool('poolre3',self.conv3_3)
#conv4
self.conv4_1 = self.conv('conv4_1',self.pool3,512,trainable=False)
self.conv4_2 = self.conv('convrwe4_2',self.conv4_1,512,trainable=False)
self.conv4_3 = self.conv('conv4rwe_3',self.conv4_2,512,trainable=False)
self.pool4 = self.maxpool('pool4',self.conv4_3)
#conv5
self.conv5_1 = self.conv('conv5re_1',self.pool4,512,trainable=False)
self.conv5_2 = self.conv('convrwe5_2',self.conv5_1,512,trainable=False)
self.conv5_3 = self.conv('conv5_3',self.conv5_2,512,trainable=False)
self.pool5 = self.maxpool('poolwel5',self.conv5_3)
def fc_layers(self):
self.fc6 = self.fc('fc1',self.pool5,4096,trainable=False)
self.fc7 = self.fc('fc2',self.fc6,4096,trainable=False)
self.fc8 = self.fc('fc3',self.fc7,2,trainable=True) #训练我们需要的
#将获取的权重载入VGG模型
def load_weights(self,weight_file,sess):
weights = np.load(weight_file)
keys = sorted(weights.keys())
#enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中
for i,k in enumerate(keys):
if i not in [30,31]: #剔除不需载入的层
sess.run(self.parameters[i].assign(weights[k]))
print("---------weights loaded------")
最后是我测试模型的代码
# -*- coding: utf-8 -*-
"""
Created on Wed Jul 10 20:21:46 2019
@author: ASUS
"""
import numpy as np
import pandas as pd
import tensorflow as tf
import vgg16_model as model
from vgg_preprocess import preprocess_for_train
import matplotlib.pyplot as plt
tf.reset_default_graph()
means = [123.68,116.779,103.939]
x = tf.placeholder(tf.float32,[None,224,224,3])
with tf.Session() as sess:
vgg = model.vgg16(x)
fc8_finetuining = vgg.probs
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
print('model restoring..')
#check_path = 'C:\\Users\\ASUS\\Desktop\\python\\data\\dogs-vs-cats\\code1\\model\\epoch_000003.ckpt.meta'
ckpt_dir = "./model/"
ckpt = tf.train.get_checkpoint_state(ckpt_dir)
saver.restore(sess,ckpt.model_checkpoint_path)
#new_saver.restore(sess,tf.train.lasters_checkpoint('./model/')) #恢复最后保存的模型
filepath = 'C:\\Users\\ASUS\\Desktop\\python\\data\\dogs-vs-cats\\train\\train\\dog.1490.jpg'
'''
image_contents = tf.read_file(filepath) #读取图片
image = tf.image.decode_jpeg(image_contents,channels = 3)
image = preprocess_for_train(image,224,224)
'''
image_raw_data = tf.gfile.FastGFile(filepath,'rb').read()
img_data = tf.image.decode_jpeg(image_raw_data)
plt.imshow(img_data.eval())
plt.show()
#print(img_data.eval())
image = preprocess_for_train(img_data,224,224)
img = image.eval()
print(img.shape)
image = tf.expand_dims(image,0)
print(image.shape)
#for c in range(3):
# img[:,:,c] -= means[c]
prob = sess.run(fc8_finetuining,feed_dict={x:[img]})
max_index = np.argmax(prob)
if max_index == 0:
print('this is a cat with possibility %.6f'%prob[:,0])
else:
print('this is a dog with possibility %.6f'%prob[:,1])