python3:Pandas库中的DataFrame中所有函数解读 - 中文官方文档解析
pandas官方文档
数据结构还包含标记的轴(行和列)。 算术运算在行和列标签上对齐。 可以看作是Series对象的类似dict的容器。
语法结构:
pandas.DataFrame(data=None, index: Optional[Collection] = None, columns: Optional[Collection] = None, dtype: Optional[Union[str, numpy.dtype, ExtensionDtype]] = None, copy: bool = False)
parameter:
1. 属性和底层数据:
1.1 轴数axes:
| DataFrame.index | row行索引 |
|---|---|
| DataFrame.columns | 数据框的列标签 |
| DataFrame.dtypes | 返回数据框的dtypes |
| DataFrame.select_dtypes(self[, include, exclude]) | 根据数据框列的dtypes返回DataFrame列的子集。 |
| DataFrame.values | 将DataFrame转换为Numpy数组表示形式 |
| DataFrame.axes | 返回一个表示DataFrame轴的列表 |
1.1.1 df.axes
import pandas as pd
df = pd.DataFrame({'col1': [1, 2], 'col2': [3, 4]})
df.axes
#Out[2]: [RangeIndex(start=0, stop=2, step=1), Index(['col1', 'col2'], dtype='object')]
#表示索引的起始和结束点及索引步次,列标签信息,数据框值的dtype
| DataFrame.ndim | 返回一个表示轴数/数组维数的整数,即有几列 |
|---|---|
| DataFrame.size | 返回一个int表示此对象中元素的数量 |
| DataFrame.shape | 返回一个tuple元组,表示数据框的纬度,几行几列 |
| DataFrame.empty | 指示DataFrame是否为空 |
1.1.2 df.ndim
import pandas as pd
df = pd.DataFrame({'col1': [1, 2,3], 'col2': [3, 4,5]})
df.ndim
#Out[6]: 2
1.2 Conversion:
| DataFrame.astype(self, dtype, copy, errors) | |
|---|---|
| DataFrame.convert_dtypes(self, …) | |
| DataFrame.infer_objects(self) | |
| DataFrame.copy(self, deep) | |
| DataFrame.isna(self) | 检测缺失值。返回的是对值的判断结果True or False |
| DataFrame.notna(self) | 检测现有(非缺失)值。返回的是对值的判断结果True or False |
| DataFrame.bool(self) |
1.2.1 df.isna
import pandas as pd
import numpy as np
df = pd.DataFrame({'age': [5, 6, np.NaN],
'born': [pd.NaT, pd.Timestamp('1939-05-27'),
pd.Timestamp('1940-04-25')],
'name': ['Alfred', 'Batman', ''],
'toy': [None, 'Batmobile', 'Joker']})
df.isna()
#Out[8]:
age born name toy
0 False True False True
1 False False False False
2 True False False False
1.3 Indexing, iteration:
| DataFrame.head(self, n) | 返回数据框的前n行,默认是5行 |
|---|---|
| DataFrame.at | 访问行/列标签对的单个值 |
| DataFrame.iat | |
| DataFrame.loc | 通过标签或布尔数组访问一组行和列 |
| DataFrame.iloc | 基于整数位置的索引,用于按位置进行选择 |
| DataFrame.insert(self, loc, column, value[, …]) | 将列插入DataFrame中的指定位置 |
| DataFrame.iter(self) | |
| DataFrame.items(self) | |
| DataFrame.iteritems(self) | |
| DataFrame.keys(self) | |
| DataFrame.iterrows(self) | |
| DataFrame.itertuples(self[, index, name]) | |
| DataFrame.lookup(self, row_labels, col_labels) | |
| DataFrame.pop(self, item) | |
| DataFrame.tail(self, n) | 返回最后n行 |
| DataFrame.xs(self, key[, axis, level]) | |
| DataFrame.get(self, key[, default]) | 从对象获取给定键的项目(例如:DataFrame列) |
| DataFrame.isin(self, values) | DataFrame中的每个元素是否包含在值中 |
| DataFrame.where(self, cond[, other, …]) | |
| DataFrame.mask(self, cond[, other, inplace, …]) | |
| DataFrame.query(self, expr[, inplace]) |
1.3.1 df.at
#.at
#.at与.loc相似,两者都提供基于(label)标签的查找。如果只需要在DataFrame或Series中获取或**设置单个值,请使用at**
import pandas as pd
import numpy as np
df = pd.DataFrame([[0, 2, 3], [0, 4, 1], [10, 20, 30]],
index=[4, 5, 6], columns=['A', 'B', 'C'])
df.at[4, 'B']#要给出要查找数据的精确位置,第几行第几列
1.3.2 df.loc
.loc []主要基于标签,但也可以与布尔数组一起使用。
允许的输入:
- 单个标签,例如 5或’a’,(请注意5被解释为索引的标签,而不是沿索引的整数位置);
- 标签label的列表或数组,例如 [‘a’,‘b’,‘c’];
- 带有标签的切片对象,例如 ‘a’:‘f’。【注意:此切片的开始和停止都包括在内】;
- 与所切片的轴的长度相同的布尔数组,例如 [True,False,True];
- 一个带有一个参数的可调用函数(调用Series或DataFrame),并且返回用于索引的有效输出(上述之一)
如果找不到任何项目,会报keyerror
Examples:
(1)通过行标签或列标签对DataFrame或series进行操作取数
#按行匹配两个excel中的数据,以左边的表为基准
import pandas as pd
import numpy as np
df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
index=['cobra', 'viper', 'sidewinder'],
columns=['max_speed', 'shield'])
#单个标签(行名或列名)。这会将行作为series返回
df.loc['viper'] #返回列名为viper的所有行
#Out[16]:
max_speed 4
shield 5
Name: viper, dtype: int64
#标签列表。注意使用[[]]返回一个DataFrame
df.loc[['cobra','viper']]
#Out[15]:
max_speed shield
cobra 1 2
viper 4 5
#行和列的单个标签
df.loc['cobra','shield']
#Out[17]: 2
#切片带有行标签和单个标签列。如上所述,请注意切片的开始和结束都包括在内,这与iloc只包含左端点不同
df.loc['cobra':'sidewinder','shield']
#Out[19]:
cobra 2
viper 5
sidewinder 8
Name: shield, dtype: int64
#有条件的返回布尔序列。shield列大于等于的所有行都会被返回
df.loc[df['shield']>=6]
#Out[20]:
max_speed shield
sidewinder 7 8
#有条件的返回带有指定列标签的布尔系列。
df.loc[df['shield']>=3,'max_speed']
#Out[22]:
viper 4
sidewinder 7
Name: max_speed, dtype: int64
#返回可调用的布尔系列
df.loc[lambda df: df['shield'] <= 5] #lambda的用法:df表示函数的输入,:后面表示函数lambda的输出
#Out[26]:
max_speed shield
cobra 1 2
viper 4 5
#设定值。为与标签列表匹配的所有项目设置值
df.loc[['viper', 'sidewinder'], ['shield']] = 50
#[OUT]: max_speed shield
cobra 1 2
viper 4 50
sidewinder 7 50
#给数据框整行设置值
df.loc['viper']=10
#给数据框整列赋值
df.loc[:, 'max_speed'] = 30
df
#Out[28]:
max_speed shield
cobra 30 2
viper 30 50
sidewinder 30 50
#设置符合可调用条件的行的值
df.loc[df['shield'] > 35] = 'ok'
df
Out[29]:
max_speed shield
cobra 30 2
viper ok ok
sidewinder ok ok
1.3.3 df.iloc
基于整数位置的索引,用于按位置进行选择。
意思就是iloc函数只根据行列号对数据进行切片或选择,与loc函数不同,loc函数可以通过规定dataframe的列名进行选择,iloc函数则是“纯粹”按照数据位置进行数据索引,参数也都是对行列号或行列号的切片或行列号的其他函数操作。
允许的Input:
- 整数,例如 5,
- 整数列表或数组,例如 [4,3,0]。
- 具有整数的切片对象,例如 1:7
- 布尔数组。
- 一个带有一个参数的可调用函数(调用Series或DataFrame),并返回用于索引的有效输出(上述之一)。
当您没有对调用对象的引用但希望基于某个值进行选择时,这在方法链中很有用。
Examples:
(1)只针对行索引的情况
#单个方括号输出的类型是series
>>> type(df.iloc[0])
<class 'pandas.core.series.Series'>
>>> df.iloc[0]
a 1
b 2
c 3
d 4
Name: 0, dtype: int64
#双重大括号输出的才是数据框
>>> df.iloc[[0]]
a b c d
0 1 2 3 4
>>> type(df.iloc[[0]])
<class 'pandas.core.frame.DataFrame'>
#输出的是index=0和index=1的行
>>> df.iloc[[0, 1]]
a b c d
0 1 2 3 4
1 100 200 300 400
#切片操作。切片的时候用单方括号,输出的type是数据框
>>> df.iloc[:3]
a b c d
0 1 2 3 4
1 100 200 300 400
2 1000 2000 3000 4000
#通过参数x传递。输出行索引除以2余数为0的行
>>> df.iloc[lambda x: x.index % 2 == 0]
a b c d
0 1 2 3 4
2 1000 2000 3000 4000
(2)针对行和列两个轴的索引情况
#单方括号,两个整数,表示(rows_index,columns_index)
>>> df.iloc[0, 1]
2
#输入整数列表分别作为行索引和列索引
>>> df.iloc[[0, 2], [1, 3]]
b d
0 2 4
2 2000 4000
#对行和列的切片操作。左闭右开,即包含左端点不包含右端点
>>> df.iloc[1:3, 0:3]
a b c
1 100 200 300
2 1000 2000 3000
#输入为series或DataFrame的可调用函数,所有行和index=0和index=2的列
>>> df.iloc[:, lambda df: [0, 2]]
a c
0 1 3
1 100 300
2 1000 3000
1.3.4 df.get
SSS
1.3.5 df.isin
XX
1.3.6 df.tail
1.4 Function application, GroupBy & window
| DataFrame.apply(self, func[, axis, raw, …]) | 沿DataFrame的轴应用功能 |
|---|---|
| DataFrame.agg(self, func[, axis])(agg=aggregate) | 使用指定轴上的一项或多项操作进行汇总 |
| DataFrame.groupby(self[, by, axis, level]) | 使用映射器或按一系列列对DataFrame进行分组 |
| DataFrame.applymap(self, func) | |
| DataFrame.pipe(self, func, *args, **kwargs) | |
| DataFrame.transform(self, func[, axis]) | |
| DataFrame.rolling(self, window[, …]) | |
| DataFrame.expanding(self[, min_periods, …]) | |
| DataFrame.ewm(self[, com, span, halflife, …]) |
1.4.1 df.apply
沿一个轴应用函数func.
语法结构:
DataFrame.apply(self, func, axis=0, raw=False, result_type=None, args=(), **kwds)
传递给函数的对象是Series对象,其索引是DataFrame的索引(axis = 0)或DataFrame的列(axis = 1)。 默认情况下(result_type = None),从应用函数的返回类型推断出最终的返回类型。 否则,它取决于result_type参数。
返回值是series或Dataframe
参数:
Func: 要apply的函数
axis: 0或index,表示行;1或columns,表示列 。默认是0(行)。如果axis=0(或index),表示对每一列应用函数func;如果axis=1(or columns),表示对每一行应用函数func
raw:bool,默认为False.
确定是否将行或列作为Series或ndarray对象传递:False:将每个行或列作为series传递给函数。True:传递的函数将改为接收ndarray对象。 如果仅应用NumPy缩减功能,则将获得更好的性能。
result_type {‘expand’,‘reduce’,‘broadcast’,None},默认为None: 这些仅在axis = 1(列)时起作用:
| “ expand”:list-like的结果将变成列。 |
|---|
| ‘reduce’:如果可能,返回一个Series而不是扩展类似列表的结果。 这与“展开”相反。 |
| “broadcast”:结果将以DataFrame的原始形状进行广播,原始索引和列将保留。 |
| 默认行为(None)取决于所应用函数的返回值:类似于列表的结果将作为一series结果返回。 但是,如果apply函数返回Series,则将它们扩展为列。 |
import pandas as pd
import numpy as np
df = pd.DataFrame([[4, 9]] * 3, columns=['A', 'B'])
df
df.apply(np.sum,axis=0)
#Out[5]:
A 12
B 27
dtype: int64
1.4.2 df.agg
聚合函数.agg语法结构:
DataFrame.agg(self, func, axis=0, *args, **kwargs)
参数:
func:用于汇总数据的功能。 如果是函数,则必须在传递DataFrame或传递给DataFrame.apply时起作用。
可接受的组合是:函数;字符串函数名称;函数和/或函数名称列表,例如 [np.sum,“平均值”];轴标签的字典->函数,函数名称或此类列表。
axis:0或index,表示行;1或columns,表示列 。默认是0(行)。如果axis=0(或index),表示对每一列应用函数func;如果axis=1(or columns),表示对每一行应用函数func
*args:位置参数传递给func。
**kwargs:传递给func的关键字参数。
返回值可以是:
标量:使用单个函数调用Series.agg时
Series:使用单个函数调用DataFrame.agg时
DataFrame:使用多个函数调用DataFrame.agg时
返回标量,系列或数据框。
examples:
>>> df = pd.DataFrame([[1, 2, 3],
... [4, 5, 6],
... [7, 8, 9],
... [np.nan, np.nan, np.nan]],
... columns=['A', 'B', 'C'])
#输入字符串函数名称列表。默认是在行上应用函数sum和min,意思就是对每列进行统计总和和最小值,然后每列有一个sum,最后会在一行上,如输出结果所示
>>> df.agg(['sum', 'min'])
A B C
sum 12.0 15.0 18.0
min 1.0 2.0 3.0
#针对不同列的aggregate操作
>>> df.agg({'A' : ['sum', 'min'], 'B' : ['min', 'max']})
A B
max NaN 8.0
min 1.0 2.0
sum 12.0 NaN
1.4.3 df.groupby
语法结构
DataFrame.groupby(self, by=None, axis=0, level=None, as_index: bool = True, sort: bool = True, group_keys: bool = True, squeeze: bool = False, observed: bool = False)
examples:
>>> df = pd.DataFrame({'Animal': ['Falcon', 'Falcon',
... 'Parrot', 'Parrot'],
... 'Max Speed': [380., 370., 24., 26.]})
>>> df
Animal Max Speed
0 Falcon 380.0
1 Falcon 370.0
2 Parrot 24.0
3 Parrot 26.0
>>> df.groupby(['Animal']).mean()#以列animal进行分组,然后计算各组的均值
Max Speed
Animal
Falcon 375.0
Parrot 25.0
1.5 统计计算函数
DataFrame.abs(self):返回series或DATa Frame中每个元素的绝对值DataFrame.all(self[, axis, bool_only, …]):如果所有的元素都为true(不为空),则返回true(可能沿着某个轴)。可用于判断是否存在空值DataFrame.any(self[, axis, bool_only, …]):如果所有元素都为False,则返回False。有一个元素为true就返回trueDataFrame.clip(self[, lower, upper, axis]):DataFrame.corr(self[, method, min_periods]):计算任意两个变量之间的相关系数矩阵(列),不包括NA /空值DataFrame.corrwith(self, other[, axis, …]):DataFrame.count(self[, axis, level, …]):计算每行或每列非NA的行数DataFrame.cov(self[, min_periods]):计算任意两个变量之间的协方差矩阵,不包括NA /空值DataFrame.cummax(self[, axis, skipna]):返回DataFrame或Series轴上的累积最大值DataFrame.cummin(self[, axis, skipna]):返回DataFrame或Series轴上的累积最小值DataFrame.describe(self[, percentiles, …]):描述性统计。给出每列数据的行数,均值,标准差、最小值、四分位数等统计信息
df = pd.DataFrame(data={
'A':list('abaacdadaf'),
'B':[2,4,6,3,6,2,5,8,0,2]
})
print(df.describe())
#[OUT]: B
count 10.000000
mean 3.800000
std 2.440401
min 0.000000
25% 2.000000
50% 3.500000
75% 5.750000
max 8.000000
DataFrame.diff(self[, periods, axis]):DataFrame.max(axis=None, skipna=None, level=None, numeric_only=None, **kwargs):返回某行或某列的最大值。
参数:
axis:行为0,列为1;
skipna:默认为true。即计算的时候跳过NA值;
level:当有多索引的时候会用到level,就是索引的水平名字
DataFrame.mean(self[, axis, skipna, level, …]):计算均值DataFrame.median(self[, axis, skipna, …]):计算中位数DataFrame.min(self[, axis, skipna, level, …]):与.max函数参数相同。DataFrame.quantile(q=0.5, axis=0, numeric_only=True, interpolation='linear'):
参数:
q:默认为0.5。意思就是中位数,q=0.25为四分之一分位数,q=0.75为四分之三分位数;
axis:计算哪个轴的数据,默认为0;
interpolation:{‘linear’, ‘lower’, ‘higher’, ‘midpoint’, ‘nearest’}。当所需分位数位于两个数据点i和j之间时,此可选参数指定要使用的插值方法:
[linear]:i +(j-i)*分数,其中分数是被i和j包围的索引的分数部分。
[lower]: i.
[higher]: j
[nearest]: i or j 哪个近插入哪个。
[midpoint]: 插入两者的平均值,(i + j) / 2。
DataFrame.sum(self[, axis, skipna, level, …]):计算某行或某列的和DataFrame.std(axis=None, skipna=None, level=None, ddof=1, numeric_only=None, **kwargs):计算标准差。DataFrame.var(axis=None, skipna=None, level=None, ddof=1, numeric_only=None, **kwargs):计算方差。
ddof:Delta自由度。计算中使用的除数为N-ddof,其中N表示元素数。
DataFrame.nunique(self[, axis, dropna]):DataFrame.prod(self[, axis, skipna, level, …]):DataFrame.product(self[, axis, skipna, …]):DataFrame.rank(self[, axis]):DataFrame.sem(self[, axis, skipna, level, …]) ;DataFrame.skew(self[, axis, skipna, level, …]):DataFrame.round(self[, decimals]):DataFrame.mode(self[, axis, numeric_only, …]) :DataFrame.pct_change(self[, periods, …]):
3
1.6 Reindexing / selection / label manipulation
DataFrame.align(self, other[, join, axis, …]):使用指定的join方法将两个对象在其轴上对齐。返回连接后的对象(数据框或其它类型)
DataFrame.align(self, other, join='outer', axis=None, level=None, copy=True, fill_value=None, method=None, limit=None, fill_axis=0, broadcast_axis=None)
参数:
other:DataFrame or Series
join:{‘outer’, ‘inner’, ‘left’, ‘right’}, default ‘outer’
DataFrame.add_prefix(self, prefix):DataFrame.add_suffix(self, suffix):DataFrame.at_time(self, time, asof[, axis]):DataFrame.between_time(self, start_time, …):DataFrame.drop_duplicates(subset=None, keep='first', inplace=False …):官方文档给的作用是“Return DataFrame with duplicate rows removed. Considering certain columns is optional.”,意思是 可以指定某些列中的重复值所在的行,返回一DataFrame
参数解释:
subset:列名或列名序列,['A']删除A列重复值所在行或['A','B']删除AB列同时重复的值所在行。可以不选,默认是所有行
keep:可选的参数有三个first、last、False,first表示保留第一次出现的重复值,其余删除,last表示保留最后一次出现的重复值,其余删除,False表示删除所有重复值
inplace:默认是False,表示不动原始数据,而是备份出来进行去重复,True表示在原始数据里去除重复行,一经变动,原始数据不可恢复
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise'):删除指定的行或列。返回数据框
labels:一个字符或者数值,加上axis ,表示带label标识的行或者列;如 (labels='A', axis=1) 表示A列
axis:axis=0表示行,axis=1表示列
columns:列名
index:表示dataframe的index, 如index=1, index=a
inplace:True表示删除某行后原dataframe变化,False不改变原始dataframe
【注意:KeyError:If any of the labels is not found in the selected axis.】
8. DataFrame.duplicated(subset=None, keep='first'):返回表示重复行的布尔系列(True or False),True表示重复,False表示不重复,可以选择指定某些列。返回值是布尔series
参数和drop_duplicates一样含义
subset:列名或列名序列,['A']删除A列重复值所在行或['A','B']删除AB列同时重复的值所在行。可以不选,默认是所有行
keep:可选的参数有三个first、last、False,first表示保留第一次出现的重复值,其余删除,last表示保留最后一次出现的重复值,其余删除,False表示删除所有重复值
DataFrame.equals(self, other):DataFrame.filter(self: ~ FrameOrSeries, items=None, like: Union[str, NoneType] = None, regex: Union[str, NoneType] = None, axis=None) :根据指定的索引标签对数据框的行或列进行子集设置。请注意,此routine不会在其内容上过滤数据帧。 过滤器将应用于索引标签。
参数:
items:保持columns中轴的位置,必须用columns名,不能是index名称
like:保持标签远离“类似于标签== True”的轴。
regex正则表达式:str(正则表达式),保持标签远离re.search(regex,label)== True的轴。
axis:{0或'index',1或'columns',无},默认为none
要过滤的轴,以索引(int)或轴名称(str)表示。默认情况下,这是信息轴,“索引”用于系列,“列”用于DataFrame。
Examples:
#like就类似于模糊查询,比如下面筛选列名中包含字符o的列(若要筛选行则axis=0)
import pandas as pd
import numpy as np
df = pd.DataFrame(np.array(([1, 2, 3], [4, 5, 6])),
index=['mouse', 'rabbit'],
columns=['one', 'two', 'three'])
print(df)
df1 = df.filter(like='o',axis=1)
print(df1)
#[OUT]:
one two
mouse 1 2
rabbit 4 5
#select columns by name
df2 = df.filter(items=['two','one'])
print(df2)
[OUT]:
two one
mouse 2 1
rabbit 5 4
DataFrame.first(self, offset):DataFrame.head(n):默认返回前10行数据,n表示返回数据行数DataFrame.idxmax(self[, axis, skipna]):DataFrame.idxmin(self[, axis, skipna]):DataFrame.last(self, offset):DataFrame.reindex(self[, labels, index, …]):DataFrame.reindex_like(self, other, method, …):DataFrame.rename(self[, mapper, index, …]):DataFrame.rename_axis(self[, mapper, index, …]):DataFrame.reset_index(self, level, …):DataFrame.sample(self[, n, frac, replace, …]):DataFrame.set_axis(self, labels[, axis, inplace]):DataFrame.set_index(self, keys, drop=True, append=False, inplace=False, verify_integrity=False):使用现有列的值设置DataFrame索引。使用一个或多个现有列或数组(长度正确)设置DataFrame索引(行标签)。
参数:
keys:labels或类数组或标签/数组的列表。此参数可以是单个列键,长度与调用DataFrame相同的单个数组,也可以是包含列键和数组的任意组合的列表。在这里,“数组”包含Series,Index,np.ndarray和Iterator的实例。
drop:布尔值,默认为True。删除要用作新索引的列。
append:布尔值,默认为False。是否将列追加到现有索引。
inplace:为True时表示要在原始数据中做修改
verify_integrity:布尔值,默认为False。检查新索引是否重复。否则,将检查推迟到必要时进行。设置为False将改善此方法的性能。
Examples:
import pandas as pd
import numpy as np
df = pd.DataFrame({'month': [1, 4, 7, 10],
'year': [2012, 2014, 2013, 2014],
'sale': [55, 40, 84, 31]})
df1 = df.set_index('month')
print(df1)
s = pd.Series([2,3,4,5])
df2 = df.set_index(s)
print(df2)
#[OUT]:
year sale
month
1 2012 55
4 2014 40
7 2013 84
10 2014 31
month year sale
2 1 2012 55
3 4 2014 40
4 7 2013 84
5 10 2014 31
DataFrame.tail( n):默认返回后10行数据,n表示返回数据行数DataFrame.take(self, indices[, axis]):DataFrame.truncate(self[, before, after, axis]):
1.8 Missing data handling
DataFrame.dropna(self, axis=0, how='any', thresh=None, subset=None, inplace=False):删除缺失值
参数:
axis:{0或“index”,1或“columns”},默认0。确定是否删除包含缺失值的行或列。0是行,1是列
how:{any,all},默认是any。当有一个或多个NA时,确定是否从DataFrame中删除行或列。all表示只要有NA,删除整行/列;any表示所有值均为NA,删除整行/列
thresh:int,可选。需要一定的NA值。thresh=2,表示删除有两个空值的行或列
subset:array-like,可选。沿其他轴考虑的标签,例如 如果要删除行,这些将是要包括的列的列表。
inplace:布尔值,默认为False。如果为True,则执行就地操作并返回None。
DataFrame.fillna(self, value=None, method=None, axis=None, inplace=False, limit=None, downcast=None):使用指定值填充NA值
参数:
value:标量,dict,Series或DataFrame。用于填充的值(例如0),或者是值的dict / Series / DataFrame,它指定每个index(对于Series)或columns(对于DataFrame)使用哪个值。不在dict / Series / DataFrame中的值将不被填充。该值不能是列表。
method:{'backfill','bfill','pad','ffill',None},默认为None,指定一个值去替换缺失值。backfill,bfill:向前填充,用下一个非缺失值填充该缺失值。pad,ffill:向后填充,用前一个非缺失值去填充该缺失值。
axis:同上drop
inplace:同上drip
limit:int,默认值none。如果指定了method,则这是要向前/向后填充的连续NaN值的最大数量,limit=1表示只向前/向后填充一个。换句话说,如果存在连续的NaN数量大于此数量的缺口,它将仅被部分填充。如果未指定method,则这是将填写NaN的整个轴上的最大条目数。如果不为None,则必须大于0。
downcast:dict,默认为none。item-> dtype决定是否向下转换的内容,或字符串“ infer”将尝试向下转换为适当的相等类型(例如,如果可能,则从float64到int64)。
Examples:
#用指定值填充
import pandas as pd
import numpy as np
df = pd.DataFrame([[np.nan, 2, np.nan, 0],
[3, 4, np.nan, 1],
[np.nan, np.nan, np.nan, 5],
[np.nan, 3, np.nan, 4]],
columns=list('ABCD'))
values = {'A': 0, 'B': 1, 'C': 2, 'D': 3}
df1 = df.fillna(value=values)
print(df1)
#[OUT]:
A B C D
0 0.0 2.0 2.0 0
1 3.0 4.0 2.0 1
2 0.0 1.0 2.0 5
3 0.0 3.0 2.0 4
DataFrame.replace(self, to_replace=None, value=None, inplace=False, limit=None, regex=False, method='pad'):将to_replace中给出的值替换为value。DataFrame的值动态替换为其他值。这与使用.loc或.iloc更新不同,后者需要您指定要使用一些值更新的位置。
参数:
to_replace:需要被替换的值。
(1)numeric, str or regex正则表达式。numeric:等于to_replace的数值将替换为value;str:与to_replace完全匹配的字符串将替换为value;regex正则表达式:与to_replace匹配的正则表达式将替换为value
(2)str,regex或数字列表:首先,如果to_replace和value都是列表,则它们的长度必须相同;其次,如果regex = True,则两个列表中的所有字符串都将被解释为regex,否则它们将直接匹配。值无关紧要,因为您只能使用几种可能的替换正则表达式。
(3)dict,字典可用于为不同的现有值指定不同的替换值。例如,{'a':'b','y':'z'}将值“ a”替换为“ b”,将“ y”替换为“ z”。若要以这种方式使用字典,则value参数应为None; 对于DataFrame,字典可以指定在不同的列中替换不同的值。例如,{'a':1,'b':'z'}在“ a”列中查找值1,在“ b”列中查找值“ z”,并将这些值替换为value中指定的值。在这种情况下,value参数不应为None。
value:标量,dict,list,str,正则表达式,默认值为none。用于替换与to_replace匹配的任何值的值。对于DataFrame,可以使用值的字典来指定要用于每一列的值(不在字典中的列将不被填充)。还允许使用此类对象的正则表达式,字符串和列表或字典。
inplace:bool,默认为False。如果为True,则在原始数据中做替换动作。【注意】:这将修改此对象上的所有其他视图(例如,DataFrame中的列)。
limit:
regex:bool或与to_replace相同的类型,默认为False。是否将to_replace和/或value解释为正则表达式。如果为True,则to_replace必须为字符串。或者,这可以是正则表达式或正则表达式的列表,字典或数组,在这种情况下,to_replace必须为None。
method:{“ pad”,“ ffill”,“ bfill”,无}
当to_replace是标量,列表或元组且值是None时,用于替换的方法。
df.replace官方解释
4. DataFrame.interpolate(self[, method, axis, …]):
1.9 Reshaping, sorting, transposing
DataFrame.droplevel(self, level[, axis]):DataFrame.pivot(data, index=None, columns=None, values=None):返回按给定的索引/列名组织的新的DataFrame。
参数:
data:DataFrame
index:用于制作新框架索引的列。如果为None,则使用现有索引
columns:用于制作新框架列的列
values:用于填充新框架值的列。 如果未指定,将使用所有剩余的列,并且结果将具有按层次结构索引的列。
DataFrame.pivot_table(self[, values, index, …]):DataFrame.reorder_levels(self, order[, axis]):
1.9.5 DataFrame.sort_values
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False, key=None):沿任一轴的值排序
参数:
by:名称或要排序的名称列表
axis:要按照哪个轴进行排序
ascending:默认为True,表示按升序排序,若为Fasle,则表示按降序排序
na_position:{first,last},默认为last,表示优先将NAN值放在最后,若为first表示优先将NAN值放在前面
DataFrame.sort_index(self[, axis, level, …]):DataFrame.nlargest(self, n, columns[, keep]):DataFrame.nsmallest(self, n, columns[, keep]):DataFrame.swaplevel(self[, i, j, axis]):DataFrame.stack(self[, level, dropna]):DataFrame.unstack(self[, level, fill_value]):DataFrame.swapaxes(self, axis1, axis2[, copy]):DataFrame.melt(self[, id_vars, value_vars, …]):DataFrame.explode(self, column, Tuple]):DataFrame.squeeze(self[, axis]):DataFrame.to_xarray(self):DataFrame.transpose(self, *args, copy):DataFrame.T:
1.10. Combining / joining / merging
DataFrame.append(Self, other, ignore_index=False, verify_integrity=False, sort=False) :新增行到调用方的末尾,并返回一个新对象,返回的对象类型是数据框。
参数:
other:DataFrame或类似Series / dict的对象,或这些对象的列表
ignore_index:默认为False,如果为True,则表示不使用索引标签
verify_integrity:默认为False,如果为True,则在创建具有重复项的索引时引发ValueError
sort:默认为False,如果self和other的列不对齐,则对列进行排序
【注意】:如果传递了一系列dict / series,并且键都包含在DataFrame的索引中,则结果DataFrame中列的顺序将保持不变。
迭代地将行附加到DataFrame可能比单个连接更多地占用大量计算资源。 更好的解决方案是将这些行添加到列表中,然后一次将列表与原始DataFrame连接起来。
Examples:
#ignore_index = True 表示的是不使用新增的数据的行索引,而是根据df1的数据的索引继续往下添加行
import pandas as pd
import numpy as np
df1 = pd.DataFrame([[1, 2], [3, 4]], columns=list('AB'))
df2 = pd.DataFrame([[5, 6], [7, 8]], columns=list('AB'))
df1 = df1.append(df2,ignore_index = True)
print(df1)
#[OUT]:ignore_index = True时的结果
A B
0 1 2
1 3 4
2 5 6
3 7 8
#[OUT]:ignore——index = False 的结果
A B
0 1 2
1 3 4
0 5 6
1 7 8
DataFrame.merge(self, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes='_x', '_y', copy=True, indicator=False, validate=None) :
用数据库样式的联接合并DataFrame或命名的Series对象。联接在列或索引上完成。 如果在列上连接列,则将忽略DataFrame索引(比如通过ID匹配,就是增加字段,行不变字段)。 否则,如果在索引上连接索引或在一个或多个列上连接索引,则将传递索引。返回的是两个对象合并后的数据框
参数:
right:DataFrame或命名的Series,要合并的对象。
how:两个对象的连接方式有四种{‘left’, ‘right’, ‘outer’, ‘inner’}, 默认是 ‘inner’
{left:仅使用左数据框中的键,类似于SQL左外部联接; 保留关键顺序。
right:仅使用右数据框中的键,类似于SQL右外部联接; 保留关键顺序。
outer:使用两个数据框中键的并集,类似于SQL完全外部联接; 按字典顺序对键进行排序。
inner:使用两个数据框中键的交集,类似于SQL内部联接; 保留左键的顺序。}
on:要连接的列或索引名称。必须在两个DataFrame中都可以找到它们。 如果on为None且未在索引上合并,则默认为两个DataFrame中列的交集。
left_on:标签或列表,或类似数组。要在左侧DataFrame中加入的列或索引级别名称。 也可以是左侧DataFrame长度的数组或数组列表。 这些数组被视为列。
right_on:标签或列表,或类似数组。列或索引级别名称要加入到正确的DataFrame中。 也可以是正确DataFrame长度的数组或数组列表。 这些数组被视为列。
left_index:布尔值,默认为False。使用左侧DataFrame中的索引作为连接键。如果它是MultiIndex,则另一个DataFrame中的键数(索引或列数)必须与级别数匹配。
right_index:布尔值,默认为False。使用右侧DataFrame中的索引作为连接键。 与left_index相同的警告。
sort:布尔值,默认为False。在结果DataFrame中按字典顺序对联接键进行排序。如果为False,则联接键的顺序取决于联接类型(how关键字)。
suffixes:(str,str)的默认值('_x','_y'),后缀分别应用于左侧和右侧的重叠列名。要在重叠的列上引发异常,请使用(False,False)。
copy:布尔值,默认为True。如果为False,请尽可能避免复制。
indicator:bool或str,默认为False。如果为True,则在输出数据帧中添加一列,称为“ _merge”,其中包含有关每一行源的信息。如果为str,则将在每一行的源上带有信息的列添加到输出DataFrame中,并且该列将被命名为字符串的值。信息列是分类类型的,对于其合并键仅出现在“ left” DataFrame中的观测值,其值为“ left_only”,对于其合并键仅出现在“ right” DataFrame中的观测值,其值为“ right_only”,如果 两者中都存在观察值的合并键。
examples:
#left_on和right_on就是一个是左边的键,一个是右边的键,用他们两列进行匹配连接
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'lkey': ['foo', 'bar', 'baz', 'foo'],
'value': [1, 2, 3, 5]})
df2 = pd.DataFrame({'rkey': ['foo', 'bar', 'baz', 'foo'],
'value': [5, 6, 7, 8]})
df = df1.merge(df2,how='outer',left_on='lkey',right_on='rkey')
print(df)
#[OUT]:
lkey value_x rkey value_y
0 foo 1 foo 5
1 foo 1 foo 8
2 foo 5 foo 5
3 foo 5 foo 8
4 bar 2 bar 6
5 baz 3 baz 7
DataFrame.join(self, other, on=None, how='left', lsuffix='', rsuffix='', sort=False):连接另一个DataFrame的列。在索引或键列上将列与其他DataFrame连接起来。 通过传递列表,一次有效地通过索引连接多个DataFrame对象。
参数:
other:DataFrame,series或DataFrame列表。索引应与此列中的一列相似。如果传递了Series,则必须设置其name属性,并将其用作结果联接的DataFrame中的列名称。
on:str,str列表或类数组(可选)。the caller中的列或索引名称要与other索引一起联接,否则就按索引进行联结。如果给定多个值,则另一个DataFrame必须具有MultiIndex。 如果调用DataFrame中尚未包含数组,则可以将其作为连接键传递。就像Excel的VLOOKUP操作一样。
how:用法同merge中的how。默认是left连接
lsuffix:左边重复的列名使用的后缀。默认是str'_x'。两个数据框中的列名有重复时才会用到
rsuffix:右边重复的列名使用的后缀。默认是str'_y'。两个数据框中的列名有重复时才会用到
sort:同merge中的用法。默认False,联结键的顺序取决于联结键的类型
Examples:
#如果要使用键列进行联接,则需要将key设置为df1和df2的索引。加入的DataFrame将以key作为其索引。
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3', 'K4', 'K5'],
'A': ['A0', 'A1', 'A2', 'A3', 'A4', 'A5']})
df2 = pd.DataFrame({'key': ['K0', 'K1', 'K2'],
'B': ['B0', 'B1', 'B2']})
df3 = df1.set_index('key').join(df2.set_index('key'),on='key')
print(df3)
#[OUT]:
A B
key
K0 A0 B0
K1 A1 B1
K2 A2 B2
K3 A3 NaN
K4 A4 NaN
K5 A5 NaN
#使用键列进行连接的另一种方法是使用on参数。DataFrame.join始终使用其他人的索引,但我们可以使用df中的任何列。此方法在结果中保留原始DataFrame的索引
df4 =df1.join(df2.set_index('key'),on='key')
print(df4)
#[OUT]:
key A B
0 K0 A0 B0
1 K1 A1 B1
2 K2 A2 B2
3 K3 A3 NaN
4 K4 A4 NaN
5 K5 A5 NaN
DataFrame.update(self, other, join='left', overwrite=True, filter_func=None, errors='ignore') :使用来自另一个DataFrame的非NA值就地进行修改。在索引上对齐。没有返回值。
参数:
other:DataFrame或可强制转换为DataFrame的对象。原始DataFrame应该至少有一个匹配的索引/列标签。如果传递了Series,则必须设置其name属性,并将其用作列名以与原始DataFrame对齐。
left:{'left'},默认为'left'。仅能实现左连接,并保留原始对象的索引和列。
overwrite:布尔值,默认为True。
如何处理重叠键的非NA值:True:使用其他值覆盖原始DataFrame的值。False:仅更新原始DataFrame中NA的值。
filter_func:callable(1d-array)-> bool 1d-array,可选。
可以选择替换NA以外的值。对于应更新的值,返回True。
errors:{‘raise’,‘ignore’},默认为“ ignore”。
如果为“ raise”,则当DataFrame和其他两者在同一位置包含非NA数据时,将引发ValueError。
Examples:
import pandas as pd
import numpy as np
df = pd.DataFrame({'A': [1, 2, 3],
'B': [400, 500, 600]})
new_df = pd.DataFrame({'B': [4, 5, 6],
'C': [7, 8, 9]})
df2 = new_df.update(df)#运行后会发现new_df数据框的B列变成了df中B列的值,C列不变。
print(df2)
#[OUT]:
None
DataFrame.assign(self, **kwargs):返回一个新数据框对象,其中除新列外还包含所有原始列。重新分配的现有列将被覆盖。
【注意】:可以在同一分配中分配多个列。 “ ** kwargs”中的后续项目可能是指“ df”中新创建或修改的列;项目将按顺序计算并分配给“ df”。
参数:
**kwargs:(callable or series)的字典。列名称是关键字。如果这些值是callable,则它们将在DataFrame上计算并分配给新列。可调用对象不得更改输入DataFrame。 如果这些值是不可调用的(例如,series,标量或数组),则只需分配它们即可。
Examples:
import pandas as pd
import numpy as np
df = pd.DataFrame({'temp_c': [17.0, 25.0]},
index=['Portland', 'Berkeley'])
#新增一列,使用lambda的方式
df1 = df.assign(temp_f=lambda x: x.temp_c * 9 / 5 + 32)
#新增一列,使用df的方式
df2 = df.assign(temp_f=df['temp_c'] * 9 / 5 + 32)
#新增多个列
df3 = df.assign(temp_b=lambda x:x.temp_c*5+2,temp_k=lambda x:x.temp_c*7/2)
print(df3)
print(df2)
print(df1)
#[OUT]:
temp_c temp_b temp_k
Portland 17.0 87.0 59.5
Berkeley 25.0 127.0 87.5
temp_c temp_f
Portland 17.0 62.6
Berkeley 25.0 77.0
temp_c temp_f
Portland 17.0 62.6
Berkeley 25.0 77.0
1.11 Plot
Dataframe.plot():
参数:
1) data:series或Dataframe;
2) x:label or position,默认为none。x轴所用的数据是哪一列,如果数据是数据框形式需要选择
3) y:label, position or label/position的列表。默认为none。如果数据是数据框形式需要选择
4) kind:要画的图的类型。‘line’ : line plot (默认)折线图
‘bar’ : 垂直条形图 vertical bar plot
‘barh’ : 水平条形图 horizontal bar plot
‘hist’ : 直方图 histogram
‘box’ : 箱线图 boxplot
‘kde’ : Kernel Density Estimation plot
‘density’ : 密度图 same as ‘kde’
‘area’ : 面积图 area plot
‘pie’ : 饼图 pie plot
‘scatter’ : 散点图 scatter plot
‘hexbin’ : hexbin plot.
5) ax:matplotlib轴对象,默认为none。当前图形的轴。
6) sunplots:子图,布尔值,默认为False,为每列分别创建子图。
7) layout:元组,可选.(行,列)用于子图的布局。
8) figsize:一个以英寸为单位的元组(宽度,高度),图形的大小。
9) use_index:布尔值,默认为True.使用索引作为x轴的刻度。
10) title:str或list。图的标题。如果传递了字符串,在图的顶部打印该字符串。如果传递了一个列表且sunplots=True,则将列表中的每个item打印在相应子图的上方。
11) grid:布尔值,默认为无(matlab样式默认为),轴网格线。
12) legend:bool或{'reverse'},将图例放在轴子图上。
13) style:列表或字典。每列的matplotlib线型。
14) logx:bool或“ sym”,默认为False。在x轴上使用对数缩放或符号对数缩放。
15) logy:bool或“ sym”默认为False。在y轴上使用对数缩放或符号对数缩放。
16) loglog:bool或“ sym”,默认为False。在x和y轴上都使用对数缩放或符号对数缩放。
17) xticks:序列,用于xticks的值。yticks:序列,用于yticks的值。
18) xlim:2-元组/列表,设置当前轴的x极限。ylim:2-元组/列表,设置当前轴的y极限。
19) xlabel:标签,可选,在x轴上用于xlabel的名称。默认使用索引名称作为xlabel。
20) ylabel:标签,可选,在y轴上用于ylabel的名称。默认将不显示ylabel。
21) fontsize:int,默认值无,xticks和yticks的字体大小。
22) colormap:str或matplotlib颜色图对象,默认为无,从中选择颜色的颜色图。如果是字符串,则从matplotlib加载具有该名称的colormap。
23) colorbar:布尔值,可选,如果为True,则绘制颜色条(仅与“scatter”和“hexbin”图有关)。
24) stacked:bool,线图和条形图默认为False,面积图为True
如果为True,则创建堆积图。
25) sort_columns:布尔值,默认为False,对列名称进行排序,以确定打印顺序。
26) secondary_y:次坐标轴,bool或序列,默认为False,如果有列表/元组,是否在次要y轴上绘制,在次要y轴上绘制哪些列。
27) mark_right:布尔值,默认为True,使用secondary_y轴时,自动在图例中将列标签标记为“(右)”。
28) include_bool:布尔值,默认为False,如果为True,则可以绘制布尔值。
29) rot:int,默认值无,刻度的旋转(垂直的xticks,水平图的yticks)。轴标题朝向的旋转
Examples:
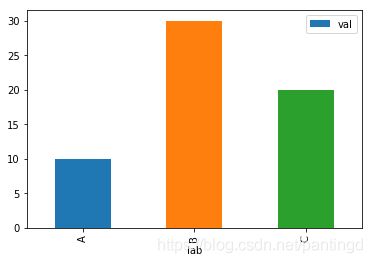
df = pd.DataFrame({'lab':['A', 'B', 'C'], 'val':[10, 30, 20]})
ax1 = df.plot.bar(x='lab', y='val',rot=0)
ax2 = df.plot.bar(x='lab', y='val')
ax1的绘图结果为:

ax2的绘图结果为: