深度篇——目标检测史(八) 细说 CornerNet-Lite 目标检测
返回主目录
返回 目标检测史 目录
上一章:深度篇——目标检测史(七) 细说 YOLO-V3目标检测 之 代码详解
论文地址:https://arxiv.org/pdf/1904.08900.pdf
原码地址:https://github.com/princeton-vl/CornerNet-Lite.
本小节,细说 CornerNet-Lite 目标检测,下一小节细说 CornerNet-Lite 目标检测 之 代码详解
九. CornerNet-Lite 目标检测
在 2019.04.19 这天,有位大佬发表了一篇论文 《CornerNet-Lite: Efficient Keypoint Based Object Detection Hei Law Yun Teng Olga Russakovsky Jia Deng Princeton University》。该论文号称,可以吊打 yolo-v3,无论精度、还是效率(有大佬测试 CornerNet-Lite 的 python 版本,比 c++ 版本 的 yolo-v3 还要快),都碾压 yolo-v3。这么犀利的利器,我们当然很有兴趣掌握在自己的手里了。下面,就来说说 CornerNet-Lite 目标检测。
1. 概要 (Abstrace)
在目标检测中,基于关键点 (keypoint-base) 检测的方法是比较新颖的范例。它消除了对anchor boxes的需求,并提供了简化的框架。基于关键点检测的CornerNet在众多的单级检测器(如SSD, YOLOv3等)中取得了最好的精度。尽管这种高精度的代价来源于高处理。在工作中,我们解决了基于关键点的高效的目标检测问题,并引入了CornerNet-Lite。CornerNet-Lite是由:CornerNet-Saccade和CornerNet-Squeeze两种处理机制组成。CornerNet-Saccade是一种使用注意力机制来消除对图像中的所有像素使用穷举处理的方法。而CornerNet-Squeeze是一种紧凑型背骨结构。CornetNet-Lite的这两种变体都是高效目标检测中的关键范例:在不牺牲精度的情况下提升效率,和在实时效率中提高精确度。
CornerNet-Saccade([sæ'kɑd]) 适用于离线处理,在 COCO 数据集中将 CornerNet 的效率提高了 6.0 倍,并提高了 1.0% AP。
CornerNet-Squeeze([skwiz]) 适用于实时检测,它提升了当下流行的实时检测器 yolo v3 的效率和精度(CornerNet-Squeeze 为 34.4% AP 和 34ms,yolo v3 为33.0% AP 和 39ms)
综合这些贡献,它首次显示了基于关键点的检测器对要求高效处理的应用是很有效的潜力

2. 介绍 (Introduction)
基于关键点的目标检测是一类对它们关键点进行分组并用来生成目标 bounding boxes 进行检测的方法。CornerNet 是它们之中的佼佼者,它对 bounding boxes 的左上角和右下角进行分组和检测。CornerNet 使用一个堆叠的 沙漏网络 (hourglass network) 来对角点热图进行预测,然后使用关联嵌入来对它们进行分组。CornerNet 可以使用一个简单的设计来消除对 anchor boxes 的要求,当前并在 COCO 数据集上获得艺术级的精度,从而从众多的单级检测器中脱颖而出。
然而,CornerNet 的主要缺点是它的推理速度。它在 COCO 数据集获得 42.2% AP(平均查准率)的代价为每张图要消耗 1.147s 推理时间,这对于要求实时或交互式的视频应用来说,实在太慢了。虽然它一方面通过减少像素数量的处理很容易就提升推理速度(例如,通过减少处理的尺度或分辨率),但是这也会导致精度大幅度下降。例如,单尺度处理与减少输入图像的分辨率相结合可以将 CornerNet 推理提速到 42ms 每张图片,速度与当下最流行的快速检测器 yolo v3 的 39ms 相差不大,但是它的精度将减少到 25.6% AP,比 yolo v3 的33.0% AP 低了太多。这就导致 CornerNet 在团队权衡精度和效率考虑时因缺乏竞争力而被放弃。
在这篇论文中,我们在探索如何提升 CornerNet 的推理效率。对于任何目标检测器来说,效率的提升都可以从以下这两个方面着手: 减少像素处理的数量(比方说,原来要处理100个像素,现在只处理30个像素) 和 减少对每个像素的处理量(比方说,原来有10种处理方式,现在只用2种方式去处理)。在这些探索中,于是自然而然就出现了上面介绍的两种 CornerNet 的变体: CornerNet-Saccade 和 CornerNet-Squeeze,我们将这两种变体统称为 CornerNet-Lite
CornerNet-Saccade 是通过减少处理像素量来加速推理。它使用一种类似于人类视觉场景中扫视的注意力机制。它从缩小全图开始并生成一张之后被模型放大后进一步处理的注意力图(attention map)。与原始的 CornerNet 不同之处在于 CornerNet-Saccade 应用了多尺度的全卷积。CornerNet-Saccade 通过选择一个在高分辨率下裁剪得到的子集,并对其进行检测,从而提升效率与精度。在 COCO 数据集上面的试验表明 CornerNet-Saccade 对每张图像耗时 190ms 并取得了 43.2% AP,相对于原始的 CornerNet, 提升了 1% AP 和 提升了 6.0 倍的效率。
CornerNet-Squeeze 是通过减少每个像素的处理量来提升推理速度。它整合了 SqueezeNet 和 MobileNets 的思路,并引入一种紧凑沙漏背骨,它是将被广泛应用的 1 x 1 卷积 和 瓶颈层相结合而得到在深度方面分离卷积。在COCO 数据集上,基于新的沙漏背骨的 CornerNet-Squeeze 对每张图像耗时 30ms 并获得了 34.4% AP ,比yolo v3 (33.0%AP 和 39ms) 更精准,更快。
通过对 CornerNet-Saccade 和 CornerNet-Squeeze 变体的研究,人们发现,它们均可以提升效率,并有一定的精度提升。那么,如果把它们整合起来(例如,CornerNet-Squeeze 是否可以被 saccades 整合成 CornerNet-Squeeze-saccades),是不是会更快更准更嗨呢?有了想法,当然忍不住去实验一把了,毕竟,实践出真理嘛。结果,一实验就跪了,因为,想象是丰满的,现实是骨感的。整合后的 CornerNet-Squeeze-saccades 被证明比原来的 CornerNet-Squeeze 效率更慢,精度更低。这是因为 saccades 网络需要可以生成一张足够精度的 注意力图(attention map) 来协助,但是 CornerNet-Squeeze 的超紧凑型架构没有这个额外的功能。此外,原始的 CornerNet 应用的是多尺度模式,这为 saccades 减少像素量处理提供了足够的空间。相对的,由于 CornerNet-Squeeze 超紧凑架构已经应用了单尺度的推理预算,这对于 saccades 的保存,无法提供足够的空间。
意义和新奇:
总的来说,CornerNet-Lite 的两种变体都是基于关键点竞争的方法,它涵盖了两个流行的用例: CornerNet-Saccade 用于离线处理,在不牺牲精度的情况下提高效率;和CornerNet-Squeeze用于实时处理,在不牺牲效率的情况下提升精度。
CornerNet-Lite 的两种变体在技术上都很新颖。在目标检测中 CornerNet-Saccade 是第一个将 saccades (滑动窗口)与基于关键点结合起来的。这个关键区别在于如何处理剪切图(像素或 feature maps) 先验。saccade-like 先验机制采用对每张裁剪图进行单目标检测(比方说,Fast R-CNN) 或对在一个包含附件子裁剪图的两级网络的每个裁剪图产生多个检测(比方说,自动对焦)。相反的,CornerNet-Saccade 则是在一个单级的网络上对每个裁剪图产生多个检测
在目标检测中 CornerNet-Squeeze 是第一个将 SqueezeNet 网络和堆叠沙漏架构进行整合和应用。先验是采用沙漏架构来获取较好的精度竞争力,但是尚不清楚沙漏架构在效率方面是否也有较好的竞争力。我们的设计和结果显示这也许是第一次,特别是在目标检测的上下文中。
贡献:
(1). 提出了两个新颖的基于关键点的目标检测方法 CornerNet-Saccade 和CornerNet-Squeeze来提升效率。
(2). 在COCO数据集上,在基于关键点检测的 CornerNet-Saccade 提升了 6 倍的效率达到当前艺术级别;并且精度也从 42.2%AP提升到43.2%AP。
(3). 在COCO数据集上,对于实时目标检测 CornerNet-Squeeze 不仅提升了精度,同时也提升了效率(从YOLO V3的33.0%AP和39ms提升到34.4%AP和30ms)
3. 相关工作 (Related Work)
目标检测中的滑动窗口(saccades)
滑动窗口是指: 就好像在人类视觉对图像上的不同区域上一系列快速的扫视。在目标检测算法的上下文中,在推理阶段我们广泛使用滑动窗口这个词来描述图像区域的选择性裁剪和处理 (按顺序或平行,像素或features)。
在目标检测中使用滑动窗口来提升推理效率的历史由来已久。例如,对一个区域的子集进行重复选择并进一步处理的级联操作是滑动窗口中的一个特例,以 Viola Jones 的人脸检测为例。滑动窗口的思想已被广泛应用于各种形式,但是可以根据每种裁剪进行粗略的分类,特别是,每种裁剪处理后生成的输出种类。
滑动窗口在 R-CNN, Fast R-CNN, 和 Faster R-CNN 中用来提取代表潜在目标的裁剪区域。经过处理后,每个裁剪区域通过分类和回归操作,要么被认为是负样本被拒绝,要么被认为是正样本而处理成一个单标签框。从 R-CNN 扩展为 Fast R-CNN 是通过使用一个滑动窗口对每个区域进行分类和回归迭代,从而对该区域进行拒绝或提炼来达到的。在所有这类 R-CNN 变体中的滑动窗口都是单类型或单目标的,因为这里处理的裁剪区域都是单类型的,并且每个裁剪区域最多只会生成一个单目标(就是说,就算是多分类,一个框,最终只会预测为一个目标,而不是一个框可以预测出两个或两个以上的目标)。

建立在SNIPER的基础之上的自动对焦改进了R-CNN的训练,增加了一个Faster R-CNN的分支来预测可能包含小目标的区域。这样再次将 Faster R-CNN 应用到对原始像素进行裁剪而得到的每一个区域。自动对焦有两类裁剪,一类是能够生成多个目标(通过调用Faster R-CNN作为一个分支),另一类则最多只能生成一个目标(在Faster R-CNN 内完成裁剪)。这类自动对焦的滑动窗口是多焦点类型和混合类型的,这就意味着它的处理方式是两种不同类型下交互进行的。
相对的,在 CornerNet-Lite 中的滑动窗口是单类型和多目标的,由于一旦没有额外的子裁剪,它就是对裁剪框处理只有一种类型,而每个裁剪框却会生成多个目标。这就意味着 CornerNet-Lite 处理的裁剪框数量可能要比目标的数量要少,然而,在R-CNN 变体的自动变焦中,裁剪的数量一定不可能小于目标的数量。
高效的目标检测器:
除了准确率外,自从引进R-CNN,近年来许多作品都应用了卷积神经网络来获取2000个感兴趣区域(ROI)来提升检测器的效率。由于 R-CNN 对 ROIs 反复使用一个卷积神经网络会产生大量冗余的计算。这点上,SPP 和 Fast R-CNN 在是通过在图像上应用一个卷积神经网络对整张图像上的每个 ROI的特征图直接进行卷积提取特征的;Faster R-CNN 则通过替换成一个低级视觉算法 RPN 网络来进一步提升效率;R-FCN 则是使用一个全卷积网络替换掉代价昂贵的全连接子检测网络;Light-Head R-CNN则通过应用可分离卷积在ROI pooling之前来降低feature map的通道数量来达到降低R-FCN的代价。在另一方面,one-stage检测器移除了two-stage检测器区域池化这种步骤。
高效的网络体系结构:
高效的卷积神经网络对许多模型和嵌入式应用来说,都是非常重要的。而那些已经被设计出来的高效网络更是倍受人关注。
SqueezeNet 提出一种fire模块,该模块可以将AlexNet中的参数量降低50倍,并同时能达到相同的性能。
MobileNets 是一类深度可分离的卷积轻量级网络,并提出在精度和效率方面获取一个较好的平衡策略。
PeleeNet 正好相反,它通过介绍了一个由双向 dense layers 和一个 stem block 组合成的 DenseNet 高性能变体来证明标准卷积神经的高性能。
其他的网络是专门为real-time检测设计的。Yolo-v2 融合了NIN思想,设计出一种新的 VGG 变体。Yolo-v3 通过让网络层级更深,并且引入跳过连接,进一步改善了 DarkNet-19。RFBNet 提出了一种模仿人类视觉感受野的新模块来有效的收集不同尺度上的信息。
4. CornerNet-Saccade
CornerNet-Saccade 是在图像中围绕在可能出现目标位置的小区域周围来检测目标。它使用缩小全图尺度来预测 attention maps 和粗 bounding boxes;这两者综合对可能是目标的位置进行建议(提议)。CornerNet-Saccade 之后通过对高分辨率区域的中心位置检查来检测目标。它同样可以通过控制每张图像目标位置的最大数量来权衡精度和性能。这个流程概述如下图所示。在本章节将具体介绍每一步骤。
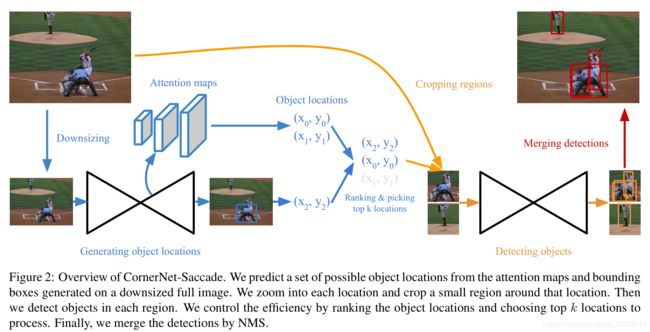
评估目标的位置:
CornerNet-Saccade 第一步是从 image 中获取可能是目标的位置。通过使用缩小全图尺度来预测 attention maps 来表明原图尺度位置和放缩尺度后粗糙目标尺度位置这两者之间的关系。给出一张 image,通过 resize image 操作来缩放图像中较长边的尺度,将其缩放为 255 和 192 像素这两个尺度。将 192 尺度的图像以 零填充 方式 padding 到 255 尺度大小,以便 192 尺度和 255 尺度可以并行操作。使用如此低分辨率图像有两个原因:第一,这一步不会出现推理时间瓶颈(即不会太费时);第二,这个网络可以很好利用 image的上下文信息来预测 attention maps。
对于缩小后的 image,CornerNet-Saccade 也类似 yolo-v3 一样,做了 3 个预测 attention maps,一个用来预测小目标,一个用来预测中等目标,还有一个用来预测大目标。在这里,如果目标的 bounding boxes 较大的边长小于 32 像素,则这个目标会被认为是小目标;如果目标的 bounding boxes 较大的边长在 32 ~ 96 像素之间,则这个目标会被认为是中目标;而如果目标的 bounding boxes 较大的边长大于 96 像素,则这个目标会被认为是大目标。CornerNet-Saccade 对不同尺度目标分开预测更有利于控制其每个位置应该缩放多少。这样,我们就可以对小目标的位置进行放大操作,也可以对中目标的位置进行缩小操作。
通过使用不同尺度的feature maps来预测attention maps。这些 feature maps 是通过以沙漏网络为背骨网络的CornerNet-Saccade来获取的。在网络中,每个沙漏模块应用几个卷积神经和下采样层来缩小输入的feature maps。之后,再通过多个卷积神经和上采样层来对前面得到的 feature maps 进行上采样,从而恢复到原来输入尺度的分辨率大小。这些上采样到原来输入尺度分辨率的 feature maps 则用来预测 attention maps。在这些 feature maps 中,较细小的尺度用于较小的目标,而那些较粗糙的尺度则用于较大的目标。这里通常在每个 feature maps后使用一个 3 x 3 conv + ReLU 模块,其后紧跟着是一个 1 x 1 conv + Sigmoid 模块来预测这些 attention maps。通过测试,我们仅处理那些得分在阈值 t 之上的区域(在试验中,设置的阈值 t = 0.3)
在 CornerNet-Saccade 对 image 进行缩放处理时,它可能会检测 到image 中的一些目标,并为这些目标生成 bounding boxes。因此,我们通常也对那些高分辨率的区域进行检测,以便可以获得更好的 bounding boxes。
在训练的过程中,我们对与 attention maps 相对应的 bounding boxes 区域内设置其中心位置作为正例(目标),而剩下区域则为负例(背景)。之后的焦点损失使用 ![]() ,而卷积层中的 biases 则是根据 attention maps 的预测来设置的。
,而卷积层中的 biases 则是根据 attention maps 的预测来设置的。
目标检测器:
CornerNet-Saccade 使用通过获得缩小后的 image 来确定哪些区域需要处理。如果直接对缩小后的 image 区域进行裁剪,那么有些目标将会可能由于太小而以至于没办法精确地检测出来。因此,必须在第一步的时候就通过检测高像素的区域来获取基于这个尺度的信息。
从 attention maps 中获取的区域可以用来为不同的目标尺度(![]() 用于小目标,
用于小目标,![]() 用于中目标,
用于中目标,![]() 用于大目标) 确定不同的缩放尺度。由于对小目标缩放的尺度更大,因此通常有
用于大目标) 确定不同的缩放尺度。由于对小目标缩放的尺度更大,因此通常有 ![]() ,于是我们可以设置
,于是我们可以设置 ![]() 。对于每个可能的区域(x, y),我们根据目标的粗略尺寸来使用
。对于每个可能的区域(x, y),我们根据目标的粗略尺寸来使用 ![]() 将缩小后的 image 进行尺寸放大。然后在该区域的中心位置的一个 255 x 255 窗口上使用 CornerNet-Saccade 。
将缩小后的 image 进行尺寸放大。然后在该区域的中心位置的一个 255 x 255 窗口上使用 CornerNet-Saccade 。
通过对 bounding boxes 的预测所给出更多关于目标尺寸的信息来获得该区域。我们可以使用 bounding boxes 的尺寸来确定缩放的尺寸。这些尺寸是这样确定的:对于放大后的 bounding boxes 中较长的边,如果是 24 则为小目标,如果是 64 则为中目标,如果是 192 则为大目标。
这里有一些用于实现高效处理的重要细节。第一,批量处理这些区域,以更好的利用 GPU 资源。第二,在 GPU 内存中保持原始的 image,并在 GPU 上对图像进行 resizing 和 cropping,以降低 image 在 CPU 和 GPU 上交互而产生的开销。
在检测到目标的可能位置之后,我们通过使用 Soft-NMS 来对 bounding boxes 进行合并和去除冗余。当我们对区域进行裁剪时,可能会出现裁剪到的区域会包含其他目标中的一部分边界区域,如下图所示。检测器也许会产生包含这些目标的 bounding boxes,原因可能是在对 bounding boxes 进行 Soft-NMS 操作时,这些区域的 bounding boxes 对整个目标的覆盖率都较低,从而没有被移除掉。因此,可以通过触碰裁剪边界来移除bounding boxes。在训练期间,CornerNet-Saccade 应用相同的训练损失训练这个网络来预测角点的热图、嵌入和偏移量。
精度和效率之间的平衡:
可以通过控制每一张image要处理目标区域的最大数量来权衡精度和效率。为了在精度和效率之间获得一个较好的平衡,我们优先考虑那些更可能包含目标的区域。因此,我们在获取到目标的区域(优先考虑从 bounding boxes 中获得的区域) 之后,再对它们的得分进行排序。通过处理前面给出最大数量的裁剪框来得到 ![]() ,然后再从最高的
,然后再从最高的 ![]() 的目标区域来检测目标。
的目标区域来检测目标。
抑制冗余的目标区域:
当目标彼此之间非常靠近的时候,这会产生一些较高覆盖率的区域,如下图所示。把它们两者之间的区域当做其中一个目标来处理显然是不可取的,因为当你检测其中一个目标的时候,很可能会检测到另一个目标。

为了解决这个问题,我们采用一个类似于 NMS 的过程来去除那些冗余的区域。首先,对目标区域进行排序,排序的区域顺序为 bounding boxes 区域优先于 attention maps 区域。之后,对最好的目标区域进行保存,将那些靠近目标区域的区域进行移除操作。这样重复迭代操作,直至将所有冗余的目标区域移除完。
背骨网络:
在CornerNet-Saccade中,我们设置了一种新型的沙漏骨架网络,并取得了较好的成绩。这个新型的沙漏网络它包含了 3 个沙漏模块,其深度并达到了 54 层,我们称这个背骨网络为 Hourglass-54。然而,在ConerNet 的 Hourglass-104 中,其包含 2 个沙漏模块,并深度达到 104 层。
在 Hourglass-54 中,其每个沙漏模块都只有很少的参数,并且其沙漏模块的深度比 Hourglass-104 中沙漏模块要浅得多。遵循 Hourglass-104 的缩放策略,我们采用 strides=2 来对 feature 进行缩放。我们在每一次下采样之后使用一个残差模块来跳过每一次的连接。每个沙漏模块对输入的feature进行三次下采样,并将通道数增加到(384, 384, 512)。在这模块的中间,有一个通道数为 512 的残差模块,并且在每一次上采用之后都有一个残差模块。在图像进入沙漏模块之前,我们对图像进行 2 次缩放操作。
按照通常的做法来,在训练一个沙漏网络过程中还可以增加一个中间监督。在测试中,我们仅使用网络中最后一个沙漏模块的预测结果。
训练细节:
我们使用 Adam 优化器来对 attention maps 和目标检测进行损失优化,并使用 CornerNet 中相同的超参来进行训练。网络输入图像大小为255 x 255,这也是在推理过程中使用的输入分辨率。我们在网络训练的时候,使用 4 块1080Ti 的 GPU,batch size 为 48。为了避免过拟合,我们采用在 CornerNet 用过的数据增强技术。当我们对目标周围随机裁剪一块区域时,这个目标要么被随机放置,要么被放置在有一些随机偏移的中心。这是为了确保训练和测试网络在检测目标和对目标区域中心裁剪时是一致的
5. CornerNet-Squeeze
概述:
与CornerNet-Saccade不同的是,CornerNet-Squeeze 关注的是减少对像素子集的处理量。CornerNet-Squeeze 探索一种对每个像素减少处理量的替代方法。在 CornerNet 中,在 Hourglass-104 中消耗了大量的计算资源。Hourglass-104 由包含两个 3 x 3 卷积层和一个跳跃连接的残差模块构成。尽管 Hourglass-104 可以获取到竞赛性的效率,但是却使用了大量的参数和推理时间。为了降低Hourglass-104的复杂性,我们结合了 SqueezeNet 和 MobileNets 的思想,设计了一个轻量级的沙漏结构。
源于 SqueezeNet 和 MobileNets 的思路:
SqueezeNet 提出了三种降低网络复杂度的方法:
(1). 将 3 x 3 的kernels 换成 1 x 1 的 kernels
(2). 将输入通道减少到 3 x 3的 kernels
(3). 延迟下采样
SqueezeNet 的组成部分,即防火模块,它概括了前两种思想。这防火模块通过一个由1 x 1 kernels 组成紧凑层来减少输入通道的数量。之后,它再通过一个由1 x 1 和3 x 3 kernels 混合的扩展层来得到结果。
基于 SqueezeNet 提供的思路,我们在 CornerNet-Squeeze 使用防火模块来替代残差模块。此外,受 MobileNets 成功的灵感,我们甚至在第二层使用一个 3 x 3 深度可分的卷积将标准的 3 x 3 卷积给替换了,这样做的好处是进一步提高了推理效率。下表展示的是 CornerNet 中残差模块与 CornerNet-Squeeze 中新的防火模块的一个详细比较。

我们没在 SqueezeNet 中探索第三种想法。由于沙漏网络具有对称性,因此在上采用期间,延迟下采样会导致产生高分辨率特征图。对高分辨率特征图进行卷积是非常耗时的,这可能会影响到我们获取实时检测。
除了替换掉残差模块外,我们还做了一些微小的修改。我们通过在沙漏模块之前增加一个下采样层来减少沙漏模块最大的特征图分辨率,并且在每个沙漏模块中移除一个下采样层。相应的 CornertNet-Squeeze 在图像进入沙漏网络前,对图像进行了 3 次下采样,而 CornerNet 则对图像下采样了 2 次。我们在 CornertNet 的预测模块中用1 x 1 kernels 替代了 3 x 3 kernels 。最后,我们使用 4 x 4 的转置卷积核来替代沙漏网络中最邻近的上采样。
训练细节:
我们使用CornerNet相同的训练losses和超参来训练 CornerNet-Squeeze。唯一做出改变的只是 batch size。图像在进入CornerNet-Squeeze 中的沙漏模块之前,再次进行了下采样,这样使得与原来像素图像相比,内存的消耗减少为之前的 1/4。这样,我们可以在 4 块 1080Ti 的 GPU 上灌入 batch size 为 55 张图像进行网络训练(主 GPU 上面 13 张图像,其余的每块 GPU 上跑 14 张图像)。
6. 实验 (Experiments)
实现细节:
CornerNet-Lite 模型是使用pytorch来实现的。我们使用 COCO 数据集来对 CornerNet-Lite 进行评估和与其他检测器进行比较的。在 COCO 数据集中,这里是 80 种目标分类和使用 115K 张图像进行训练,使用 5K 张图像进行验证,并使用 20K 张图像进行测试。
为了测量每个检测器的推理时间,我们在网络刚刚读取完图像,就开始计时,等最后的 bounding boxes 一出来就马上结束计时。由于设备硬件会影响推理时间。为了保障两个不同检测器之间相对公平性,我们在相同 1080Ti GPU 和 i7-7700k CPU 机器上测量推理时间。
精度和效率之间的平衡:
我们对CornerNet-Lite和三个艺术级的目标检测器(包括YOLOv3、RetinaNet和CornerNet)进行验证集上的精度和效率之间平衡的比较。下图为精度和效率平衡曲线

我们是在 1~30 中随机设置一个 ![]() ,在这个
,在这个 ![]() 下对 CornertNet-Saccade 进行评估的。在 RetinaNet 中,我们是在包含了 300, 400, 500, 600, 700, 和 800(默认尺度) 的不同尺度下,进行单尺度评估的。在 CornerNet 中,我们是在包含原始图像分辨率的 0.5,0.6,0.7,0.8,0.9,和 1.0(原始图像分辨率) 的不同分辨率下,进行分辨率单尺度评估的。我们同样会测试它在默认的混合尺度下的设置,并且不翻转图像。CornerNet-Saccade 获取的精度和效率的平衡(42.6% 和 190ms) 比 RetinaNet(39.8% 和190ms) 和 CornerNet(40.6% 和 213ms) 更好。下图为 CornerNet-Saccade 和 CornerNet 的一些定性样本的比较:
下对 CornertNet-Saccade 进行评估的。在 RetinaNet 中,我们是在包含了 300, 400, 500, 600, 700, 和 800(默认尺度) 的不同尺度下,进行单尺度评估的。在 CornerNet 中,我们是在包含原始图像分辨率的 0.5,0.6,0.7,0.8,0.9,和 1.0(原始图像分辨率) 的不同分辨率下,进行分辨率单尺度评估的。我们同样会测试它在默认的混合尺度下的设置,并且不翻转图像。CornerNet-Saccade 获取的精度和效率的平衡(42.6% 和 190ms) 比 RetinaNet(39.8% 和190ms) 和 CornerNet(40.6% 和 213ms) 更好。下图为 CornerNet-Saccade 和 CornerNet 的一些定性样本的比较:
沿用 YOLOv3 的默认设置,我们在 YOLOv3 上对一张图像的三个尺度 (320, 416, 和608) 进行评估。类似的,我们在CornerNet-Squeeze 上同样进行多尺度 (0.5, 0.6, 0.7, 0.8, 0.9, 1.0) 评估。这样 CornerNet-Squeeze 获得的精度和效率 (34.4%和30ms) 的平衡比 YOLOv3(32.4%和39ms) 要好。在 CornerNet-Squeeze 中,我们使用翻转图和原图来进行训练,使精度得到进一步提升(提升到36.5%AP和50ms),并仍能获得一个很好的平衡。当我们在混合尺度设置下测试 CornerNet-Squeeze 时,我们看到,在AP方面仅仅提升了 0.6%,但是推理时间却达到了 170ms。
CornerNet-Saccade 的结果:
训练效率:CornerNet-Saccade 不仅在测试中提升了效率,而且在训练的时候也提升了效率。我们可以在 44GB 内存的1080Ti GPU 上面训练 CornerNet-Saccade ,但是想要训练 CornerNet 却要用一共 120GB 内存,10块Tian X(PASCAL) 的GPU。我们减少了超过 60% 的内存使用。既不在 CornerNet 也不在 CornerNet-Saccade 上使用混合密集训练

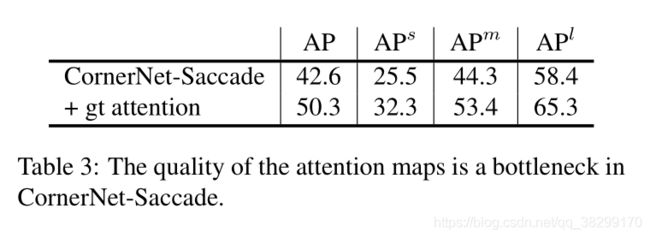
错误分析: 在 CornertNet-Saccade 中,attention maps 是非常重要的。如果 CornerNet-Saccade 中的 attention maps 不准确,则会导致图像中的目标丢失。为了更好的理解 attention map 的质量,我们使用一个 ground truth attention maps 来替代其中一个预测的 attention maps。这使得 CornerNet-Saccade 在验证集上的 AP 从4 2.6% 提升到 50.3%,这就显示出有足够的空间来提升 attention maps。
Hourglass-54 的性能分析: 在 CornerNet-Saccade 中,我们介绍了一种新的沙漏——Hourglass-54,通过执行两个实验来更好的理解 Hourglass-54 在性能方面的贡献。首先,我们在 CornerNet-Saccade 中用 Hourglass-104 网络来替代 Hourglass-54 网络来进行训练。其次,我们在 CornerNet 中用 Hourglass-54 网络来替代 Hourglass-104 网络来进行训练。在第二个实验中,由于资源的限制,我们将两个网络都置于 4 块 1080Ti 的 GPU 下,把 batch size 设为 15,并遵循 CornerNet 的细节来训练。下图展示为 CornerNet-Saccade 的 Hourglass-54(42.6%AP) 网络比 Hourgalss-104(41.4%AP) 网络更准确。

为了研究性能的差异,我们对 attention maps 和 bounding boxes 进行了质量评估。首先,可以将预测到的 attention maps 看做是一个二分类的问题——目标自信度正样本和负样本(即是前景,还是背景的问题)。我们使用平均预测的 attention maps 来估量它的品质,用 ![]() 来表示。Hourglass-54 获得的
来表示。Hourglass-54 获得的 ![]() 为 42.7%,而 Hourglass-104 获得的
为 42.7%,而 Hourglass-104 获得的 ![]() 为 40.1%,这表明Hourglass-54网络预测的attention maps 更好。
为 40.1%,这表明Hourglass-54网络预测的attention maps 更好。
其次,对于各个网络 bounding boxes 质量的研究,我们使用真实的 attention maps 来替换预测的 attention maps,同样使用 Hourglass-54 的 CornerNet 来训练。基于真实的 attention maps,CornerNet-Saccade 的 Hourglass-54 获得 50.3%AP,而CornerNet-Saccade 的 Hourglass-104 才获得 48.9%AP。CornerNet 的 Hourglass-54 获得 37.2%AP,而 CornerNet 的Hourglass-104 获得 38.2%AP,这个结果表明了 Hourglass-54 在结合扫视(滑动窗口),产生了更好的 bounding boxes
CornerNet-Squeeze 的结果:
与YOLOv3的比较: 我们将CornerNet-Squeeze与被广泛应用于实时目标检测的YOLOv3进行比较。如下图所示:

YOLOv3 不仅可以用 c 语言来实现,同时也提供了python 的 API,其中 python 版本的 YOLOv3 在推理方面比 c 语言的多耗时 10ms。换句话来说,CornerNet-Squeeze 使用 python 来实现却仍然比 c 语言版本的 YOLOv3 要快。如果我们使用 c 语言来实现 CornerNet-Squeeze 的话,可以进一步提升效率。
网络消融研究: 我们研究在 CornerNet-Squeeze 中的每一个主要的改变来理解它对推理时间和AP的贡献。为了保护 GPU 资源,每一个模型仅用 250K 迭代次数,和遵循上面 CornerNet-Squeeze 训练细节中的详情来训练,包括在进入沙漏模块之前使用额外的下采样。对于 GPU 的资源为 4 块 1080Ti 时,我们可以在训练网络中定义 batch size 为 55(参见 上面 CornerNet-Squeeze 训练细节) 的 CornerNet-Squeeze;而我们却只能训练 batch size 为 15 的 CornerNet。下面为 CornerNet 在 250k 迭代下的 Aps 的参考数据:

在 CornerNet 中,在进入沙漏网络之前,会有两个下采样层。如果我增加超过一个下采样层,我们可以将推理时间从 114ms 减少到 46ms。使用防火模块替代残差模块可以提升 11ms 效率,在预测层使用1 x 1卷积核又可以提升 2ms 效率,并且没有任何的性能损失。最后,我们使用转置卷积,因为它可以提升 0.5% 的 AP,并稍微增加了点推理时间。
CornerNet-Squeeze-Saccade 结果:
我们尝试对 CornerNet-Squeeze 与 saccades 进行组合来更好的提升效率。但是,我们发现 CornerNet-Squeeze-Saccade 无法超越 CornerNet-Squeeze 。在验证集上,CornerNet-Squeeze 获得了 34.4%AP,而 CornerNet-Squeeze-Saccade 在 ![]() 时才获取到 32.7%AP。如果我们使用真实的 attention maps 替代预测的 attention maps,我们则可以将 CornerNet-Squeeze-Saccade 提升到 38.0%AP,并超越 CornerNet-Squeeze。
时才获取到 32.7%AP。如果我们使用真实的 attention maps 替代预测的 attention maps,我们则可以将 CornerNet-Squeeze-Saccade 提升到 38.0%AP,并超越 CornerNet-Squeeze。
这结果说明了 saccades (滑动窗口)只能在 attention maps 足够精确的情况下有效。由于 CornerNet-Squeeze-Saccade 是超紧凑型结构,它没有足够的能力同时去检测目标和预测 attention maps。甚至,CornerNet-Squeeze 只能处理单尺度图像,为节约 CornerNet-Squeeze-Saccade 资源提供更少的空间。CornerNet-Squeeze-Saccade 与 CornerNet-Squeeze 相比,可以处理大量的像素,并减缓推理时间。

COCO Test AP:
我们将CornerNet-Lite与CornerNet 和YOLOv3在COCO测试数据集上做比较,如下图所示:

7. 结论
推荐使用 CornerNet 的两种高效的变体 CornerNet-Lite 网络: CornerNet-Saccade 和 CornerNet-Squeeze。它们的贡献是:首次揭示了基于关键点检测的潜力,并对要求高效处理的应用程序是有效。
CornerNet-Saccade 用于离线处理,在不牺牲精度的情况下提高效率,在 COCO 数据集中将 CornerNet 的效率提高了 6.0 倍,并提高了 1.0% AP。CornerNet-Squeeze用于实时处理,在不牺牲效率的情况下提升精度,它提升了当下流行的实时检测器 yolo v3 的效率和精度(CornerNet-Squeeze 为 34.4% AP 和 34ms,yolo v3 为33.0% AP 和 39ms)
CornerNet-Saccade 是通过减少处理像素量来加速推理; CornerNet-Squeeze 是通过减少每个像素的处理量来提升推理速度。
CornerNet-Saccade 是第一个将 saccades (滑动窗口)与基于关键点结合起来的; CornerNet-Squeeze 是第一个将 SqueezeNet 网络和堆叠沙漏架构进行整合和应用。
8. 作者源码结构图
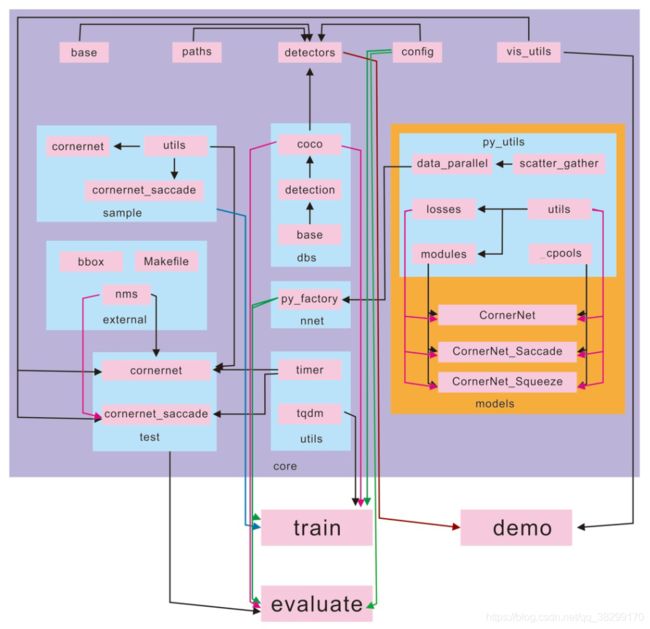
有这个结构图形,想来大家看源码,会轻松不少的。根据这些依赖,看着过去,会相对轻松的。而且,如果不是照搬源码的话,也可以干掉一些冗余的代码,让项目更清爽点。

返回主目录
返回 目标检测史 目录
上一章:深度篇——目标检测史(七) 细说 YOLO-V3目标检测 之 代码详解