pandas记录之文本数据
- 特殊字符
数据在收集的过程中由于各种原因,汇总的数据会出现一些出乎预料的问题
#数据中有特殊字符
309 0-
396 9`
485 /7
Name: col2, dtype: string
在进行数值统计时很头痛,一般情况下就是根据报错信息逐个replace
df.loc[df['col2'].str.contains('0-'),'col2']='0'
df.loc[df['col2'].str.contains('9`'),'col2']='9'一个两个还好,第三个出现时,已经有点奔溃了
从Joyful-Pandas中学到了一种使用正则表达式的方法(以下为链接)
https://github.com/datawhalechina/joyful-pandas/blob/master/README.md
df['col2'][~(df['col2'].str.replace(r'-?\d+','True')=='True')]
28 355`.3567
37 -5
73 1
122 9056.\2253
332 3534.6554{
370 7
Name: col3 , dtype: string遇到过这种数据的,在读取数据时使用convert_dtypes()方法就可以发现数据存在问题
df=pd.read_csv('data/String_data_two.csv').convert_dtypes()
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 500 entries, 0 to 499
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 col1 500 non-null string
1 col2 500 non-null string
2 col3 500 non-null string
dtypes: string(3)
memory usage: 11.8 KB
col2、col3两列存放的是数值,当使用convert_dtypes()读取时,如果数据没问题dtype应该是int或float,不可能是string
#列名中有空格
df.columns
Index(['col1', 'col2', 'col3 '], dtype='object')
列名中有空格,一般肉眼看不出来
2.文本数据的合并 str.cat
cat的inde必须一样,否则结果为NA
两个Series合并而言,是对应索引的元素进行合并
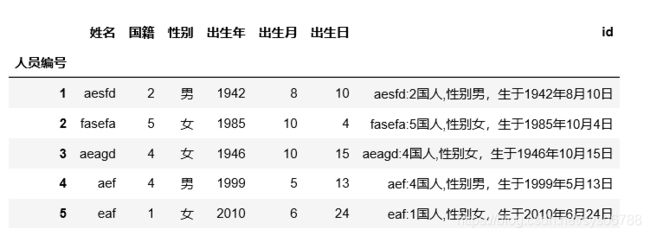
将下列数据改为:×××(名字):×国人,性别×,生于×年×月×日
df_2=pd.Series([':','国人,性别',',生于','年','月','日'],index=['姓名', '国籍', '性别', '出生年', '出生月', '出生日'])
df2=df.copy()
for i in range(1,df2.shape[0]+1):
s=df.loc[i].astype('str').astype('string').str.cat(df_2).values
df2.loc[i,'id']="".join(s)
df2.head()
3.文本数据拆分
将2中的ID列拆分回去
#参考代码
pd.Series(['10-87', '10-88', '10-'],dtype="string").str.extract(r'(?P[\d]{2})-(?P[\d]{2})?' )
#部分拆分
df2['id'].astype('str').astype('string').str.extract(r'(?P<姓名>\w+):(?P<国籍>\w)国人,性别(?P<性别>\w),?').head()

注意:正则表达式在文本数据处理中能够减少很多工作量,需花时间精力学习,多实践才是王道!