【机器学习】分类决策树基本介绍+代码实现
参考:https://blog.csdn.net/u012351768/article/details/73469813
1.基础知识
基于特征对实例进行分类。
优点:复杂度低,输出结果易于理解,缺失中间值不敏感,可处理不相关特征数据。
缺点:过度匹配。
适用数据类型:标称和数值型。(数值型需要离散化)
构建决策树时,在每次分支时都要选择最能区分数据的特征。
2.划分数据集依据
2.1 信息增益(ID3),越大越好
D:数据集
A:特征A
K:类别的集合 k~K
D的经验熵:
 ,(表示数据集D的纯度,H越小,纯度越高)
,(表示数据集D的纯度,H越小,纯度越高)
特征A将数据集D分成N个数据集,特征A对数据集D的经验条件熵:
 ,(即给定特征A,计算每个子数据集的纯度再求和,表示给定A后数据集的纯度,数值越小纯度越高)
,(即给定特征A,计算每个子数据集的纯度再求和,表示给定A后数据集的纯度,数值越小纯度越高)
特征A对数据集的信息增益:
![]() ,(即特征A帮助提升的纯度的大小,值越大越好)
,(即特征A帮助提升的纯度的大小,值越大越好)
2.2 信息增益率(C4.5)越大越好
由于信息增益会偏向取值较多的特征(过拟合),解释:当特征A取值很多,则划分出的组数增多,使得H(D|A)减小,则信息增益增大。但是过于精细的划分,会使得分类失去意义。(比如按照身份证号给人分类,则每一个人都是一类)。
特征A对数据集D的信息增益率:
![]()
其中,特征A将数据集分成N类,则对于所有特征A相对应的数据的N个类的信息经验熵为(即表示了特征A为类别标签时,数据D的纯度):
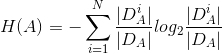
因为当A将数据集D分成太多类时,其纯度降低,H(A)增加,相当于给信息增益添加了一项惩罚项。
2.3 Gini系数(CART)越小越好
基尼指数:从数据集里随机选取子项,度量其被错误分类到其他分组里的概率。基尼系数指数据的不纯度,越小越好。
CART是一个二叉树分类。
K是数据集D的标签集合:k~K
数据D的基尼系数:
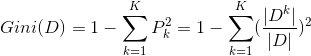
若特征A将数据D分成两个数据集:
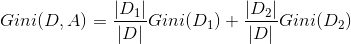
但是若当特征A将数据集D分成超过两个数据集时,需要计算以每一个取值作为划分点,对样本D划分之后子集的纯度Gini(D,Ai),(其中Ai 表示特征A的可能取值),然后从所有的可能划分的Gini(D,Ai)中找出Gini指数最小的划分,这个划分的划分点,便是使用特征A对样本集合D进行划分的最佳划分点。
对各个概念的理解:熵描述了信息的不确定性,我们的目标是划分数据集D,使得划分后的数据集的不确定性降低。信息增益描述了特征A对于降低数据集D的不确定性的帮助,信息增益越大,说明A的引入增加了信息,降低了D的不确定性。然而,由于信息增益会偏向取值较多的特征,为了解决这个特征之间的选择不平衡的现象,我们添加了一项惩罚项,引入了信息增益率。
3. ID3, C4.5, CART比较
| 任务 | 准则 | 适合数据 | 优点 | 缺点 | |
| ID3 | 分类 | 信息增益最大化 | 标称 | 基础算法,结构简单 | 偏好取值较多的特征,无法处理连续值 |
| C4.5 | 分类 | 信息增益率最大化 | 标称,连续(二分法) | 解决ID3不平衡偏好,可处理连续值 | 过拟合(剪枝) |
| 回归 | 平方误差最小化 | ||||
| CART | 分类 | 基尼指数最小化 | 标称,连续(二分法) | 既可以分类,又可以回归 | 二叉树,当离散型特征超过两个取值时,需要逐个比较选择。过拟合(剪枝) |
| 回归 | 平方误差最小化 |
4. 决策树剪枝
构建决策树时,根据最优的特征进行构建,往往会使得所得的树分支过多,过拟合。因此需要对树进行剪枝。
预剪枝:边构建树边剪枝。当到某一节点无法达到要求时,即停止分支。
后剪枝:先完整地构建出决策树,然后自下而上地进行剪枝。
判断是否剪枝的标准:剪枝前后的泛化能力,若剪枝后泛化能力增强,则剪枝,否则不剪枝。
泛化能力的判断方法:留出法。即在原数据集中拿出一部分做为验证集,剪枝时,判断该分支分与部分对验证集分类的影响(准确率的影响)。
注意:因为预剪枝含有“贪心”的思想,即一旦某个节点分支不能提高泛化能力,立即停止。此时可能会忽略后续泛化能力高的分支。因此预剪枝可能会造成“欠拟合”。
5. “连续属性&缺失属性”的分类问题
连续属性:使用二分法,属性值排序后取中点。C4.5使用该方法。
缺失属性:指样本数据不完整,某些属性的值缺失。当使用含有缺失属性的数据构建决策树时,一个方法是舍弃含有缺失属性的样本;当对含有缺失属性的数据进行分类时,将含有未知属性的样本用不同概率划分到不同的子节点。
6.代码实现
参考:《机器学习实战》
源码地址以及数据:https://github.com/JieruZhang/MachineLearninginAction_src
from math import *
import operator
import pickle
#计算熵
def entropy(data):
num = len(data)
num_labels ={}
for vec in data:
num_labels[vec[-1]] = num_labels.get(vec[-1],0)+1
ent = 0.0
for key in num_labels.keys():
prob = float(num_labels[key])/num
ent -= prob*log(prob,2)
return ent
#根据给定特征划分数据集, axis是特征对应的编号,value是匹配的值
def splitDataSet(data, axis, value):
res = []
for vec in data:
if vec[axis] == value:
res.append(vec[:axis] + vec[axis+1:])
return res
#遍历数据集,计算每种特征对应的信息增益,选出增益最小的,该特征即为用于分类的特征
def chooseFeature(data):
num_feature = len(data[0])-1
#计算H(D)
base_ent = entropy(data)
max_gain = 0.0
best_feature = 0
for i in range(num_feature):
#找出feature的种类
uniqueFeature = set([vec[i] for vec in data])
#对每个feature计算其对应的条件信息熵
sub_ent = 0.0
for feature in uniqueFeature:
sub_data = splitDataSet(data, i, feature)
prob = len(sub_data)/float(len(data))
sub_ent += prob*entropy(sub_data)
#计算每个feature对应的信息增益
gain = base_ent - sub_ent
#选择最大的信息增益,其对应的feature即为最佳的feature
if gain > max_gain:
max_gain = gain
best_feature = i
return best_feature
#递归构建决策树
#原始数据集-> 递归地基于最好的属性划分数据集->终止条件:所有属性已经用过或划分后的数据集每个集合只属于一个label,
#若所有属性用完但是每个划分属性不都属于一个label,就使用“多数表决”的方法。
#多数表决函数
def majority(classes):
classCount = {}
for item in classes:
classCount[item] = classCount.get(item,0) + 1
sortedClassesCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse=True)
#返回表决最多的label
return sortedClassCount[0][0]
#递归构建树,存入字典中,以便随后的可视化.feature_name是feature的名字,仅是为了可视化方便。
def createTree(data, feature_names):
#找出data数据集中所有的labels
classList = [item[-1] for item in data]
#如果只属于一种label,则停止构建树
if len(set(classList)) == 1:
return classList[0]
#若果所有features属性都已经使用完,也停止构建树
#每次用完一个特征都会删除,这样最后数据集data中只剩下最后一位的label位
if len(data[0]) == 1:
return majority(classList)
bestFeat = chooseFeature(data)
bestFeatName = feature_names[bestFeat]
#bestFeatName是用于分离数据集的特征的名字,作为根
tree = {bestFeatName:{}}
#del只删除元素,但是原来的index不变
sub_names = feature_names[:]
del(sub_names[bestFeat])
uniqFeats = set([item[bestFeat] for item in data])
#对于每个feature,递归地构建树
for feature in uniqFeats:
tree[bestFeatName][feature] = createTree(splitDataSet(data,bestFeat,feature), sub_names)
return tree
#分类函数,也是递归地分类(从根到叶节点)
def classify(tree, feature_names, test_data):
#找到根,即第一个用于分类的特征
root = list(tree.keys())[0]
#找到根对应的子树
sub_trees = tree[root]
#找出对应该特征的index
feat_index = feature_names.index(root)
#对所有子树,将测试样本划分到属于其的子树
for key in sub_trees.keys():
if test_data[feat_index] == key:
#检查是否还有子树,或者已经到达叶节点
if type(sub_trees[key]).__name__ == 'dict':
#若还可以再分,则继续向下找
return classify(sub_trees[key], feature_names,test_data)
else:
#否则直接返回分的类
return sub_trees[key]
#存储树(存储模型)
def stroeTree(tree, filename):
fw = open(filename,'w')
pickle.dump(tree,fw)
fw.close()
return
#提取树
def grabTree(filename):
fr = open(filename)
return pickle.load(fr)
#预测隐形眼镜类型,已知数据集,如何判断患者需要佩戴的眼镜类型
fr = open('lenses.txt')
lenses = [line.strip().split('\t') for line in fr.readlines()]
feature_names = ['age', 'prescript','astigmatic','tearRate']
#构建树
tree = createTree(lenses,feature_names)
#可视化树
createPlot(tree)
#测试
print(classify(tree,feature_names,['pre','myope','no','reduced']))sklearn 实现,sklearn使用的是cart分类树。
from sklearn import tree
def DT(train_data, test_data, train_class):
clf = tree.DecisionTreeClassifier()
clf = clf.fit(train_data, train_class)
return clf.predict(test_data)