【python热搜爬虫+定时发送邮件操作①】不会吧不会吧!不会2020了还有人需要用软件看微博热搜吧?
以下内容为本人原创,欢迎大家观看学习,禁止用于商业用途,转载请说明出处,谢谢合作!
【写在前面】
大噶好,我是python练习时长3个月的Yhen,好久久久久…不见啦,已经有一个多月没有写博客啦哈哈哈,不知道手有没生生疏了哈哈哈。现在放假了,就可以抽点时间出来写博客啦~
还有我上星期发了那个Blink后,我的粉丝从58涨到了83,哈哈哈真有点受宠若惊呀,哈哈谢谢你们的支持,你们的支持是我创作的最大动力。
我当然也不能辜负你们的关注,所以今天给大家带来一个好玩的项目----爬取新浪微博热搜榜数据并通过邮件定时自动发送到邮箱~
文章目录
- 一.最终效果展示
- 二.前期准备
- 三.思路分析
- 四.项目实战
- 五.源码分享
- 六.往期文章回顾
一.最终效果展示
不错吧~以后每天一睡醒,打开微信查看今天的邮件就可以知道今天的热搜信息了,哪还要打开软件这么麻烦呀,美滋滋 ~
这篇文章主要介绍的是第一步——热搜数据的爬取
话不多说,马上起飞
二.前期准备
首先介绍一下这篇文章所需要用到的一些库以及在这篇文章中的用法
requests 经典爬虫库
pyquery 页面数据的定位解析
datetime 获取当今日期
大家安装的时候只需要在终端输入 pip install +对应的库名即可。如(pip install requests)
okk,准备好以后,就开始分析一波吧
三.思路分析
①首先明确我们的需求是爬取热搜榜单的数据
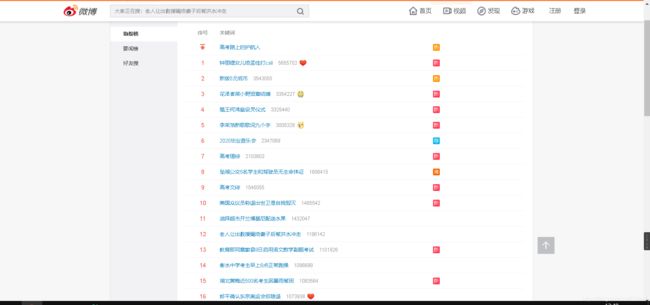
喏,就是上面这些,我们要把他们爬取下来。
URL地址:https://s.weibo.com/top/summary
②然后按下F12盘一波
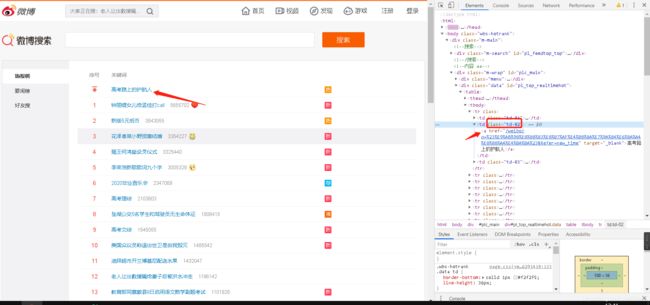
③当我们定位页面到第一条数据的时候
代码跳转到了类选择器为“td-02”的td标签
而在其下级有个超链接标签
里面即有我们想要的热搜内容以及其对应的链接。
所以想必大家思路已经很明确的吧!
通过requests对页面进行请求------>通过pyquery解析数据,提取热搜文字以及链接----->保存为txt文件----->点赞收藏加关注!
哈哈哈哈哈既然思路明确了,那就放码过来吧!
四.项目实战
首先将今天要用到的包导入
import requests
from pyquery import PyQuery as pq
import datetime
然后对微博网页发送请求,获取其文本数据
# 微博热搜网址
url = 'https://s.weibo.com/top/summary'
# 请求微博热搜网址 获取其文本数据
res = requests.get(url).text
我们来看看效果

是可以成功获取到数据的!
接下来用pyquery来解析数据
刚刚我们说到,我们想要的数据在类选择器为td-02下的a标签里
# 数据初始化
doc = pq(res)
# 通过类选择器提取热搜信息
td = doc('.td-02 a').items()
而链接就在这个a标签下的herf属性中,文字也可以直接提取

然后我们遍历得到的数据
将链接和文字提取出来
并拼接在一起
# 遍历数据
for x in td:
# 获取热搜文字
title = x.text()
# 获取热搜链接 并拼接成完整链接
href = 'https://s.weibo.com' + x.attr('href')
# 将文字和链接合并在一个content变量中
content = title + '\n' + href + '\n\n'
我们来看看效果

成功获取到了内容
接下来就是把这些内容保存到本地啦
因为每天的热搜都不一样,所以文件的名字当然要用当天的日期命名啦
所以我们可以通过以下的代码获取到今天的日期
date = datetime.datetime.now().strftime('%Y-%m-%d')
最后再保存到本地就ok啦
# 将文件保存以日期命名的txt文件 以追加的方式写入 编码为utf-8
f = open(date + '.txt', 'a', encoding='utf-8')
# 将热搜内容写入
f.write(content)
# 关闭写入
f.close()
最后实现的效果是这样的
![]()
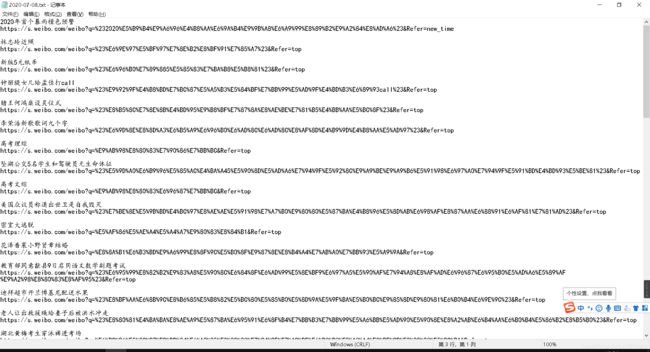
OK~至此,我们这个项目的第一步微博爬虫部分已经完成啦!
下一篇文章已更新:
【python微博爬虫+定时发送邮件操作②】不会吧不会吧!不会2020了还有人需要用软件看微博热搜吧?
大家如果觉得我写的还可以的话,
可以点个赞鼓励下小弟嘛,点个关注就更好啦!
你们的支持是我创作的最大动力!
谢谢大家!
五.源码分享
import requests
from pyquery import PyQuery as pq
import datetime
def WeiBo_Spider():
# 微博热搜网址
url = 'https://s.weibo.com/top/summary'
# 请求微博热搜网址 获取其文本数据
res = requests.get(url).text
# 数据初始化
doc = pq(res)
# 通过类选择器提取热搜信息
td = doc('.td-02 a').items()
# 遍历数据
for x in td:
# 获取热搜文字
title = x.text()
# 获取热搜链接 并拼接成完整链接
href = 'https://s.weibo.com' + x.attr('href')
# 将文字和链接合并在一个content变量中
content = title + '\n' + href + '\n\n'
# 获取今日日期,并转换为字符串的形式。以此日期命名建立文件路径
date = datetime.datetime.now().strftime('%Y-%m-%d')
# 将文件保存以日期命名的txt文件 以追加的方式写入 编码为utf-8
f = open(date + '.txt', 'a', encoding='utf-8')
# 将热搜内容写入
f.write(content)
# 关闭写入
f.close()
WeiBo_Spider()
六.往期文章回顾
【爬虫+数据可视化】Yhen手把手带你爬取CSDN博客访问量数据并绘制成柱状图
【爬虫】Yhen手把手带你爬取去哪儿网热门旅游信息(并打包成旅游信息查询小工具
【爬虫】Yhen手把手带你用python爬小说网站,全网打尽,想看就看!(这可能会是你看过最详细的教程)
【实用小技巧】用python自动判断并删除目录下的空文件夹(超优雅)
【爬虫+数据库操作】Yhen手把手带你用pandas将爬取的股票信息存入数据库!
【selenium爬虫】
Yhen手把手带你用selenium自动化爬虫爬取海贼王动漫图片
【爬虫】秀才不出门,天下事尽知。你也能做到!Yhen手把手带你打造每日新闻资讯速达小工具。
【爬虫】Yhen手把手带你用python爬取知乎大佬热门文章
【爬虫】Yhen手把手教你爬取表情包,让你成为斗图界最靓的仔
【前端】学过一天的HTML+CSS后,能做出什么有趣的项目?