Ear Recognition: More Than a Survey
文还介绍了一个新的完全不受约束的从网络收集的耳朵图像数据集,
提供一个工具箱,该工具箱实现了几种最先进的耳朵识别技术。(Matlab)
The toolbox is available from: http://awe.fri. uni-lj.si
自动耳朵识别系统中使用的耳朵图像
通常可以从个人头像拍摄或录像中提取出来。采集过程是非接触的且非侵入性的,并且也不取决于人们试图识别的人的合作能力。在这方面,人耳识别技术与其他基于图像的生物特征识别方法具有相似之处。耳部生物识别技术的另一个吸引人的特性是其独特性[1]。最近的研究甚至凭经验验证了现有的推测,即对于同卵双胞胎,耳朵的某些特征是不同的[2]。这一事实对于与安全相关的应用具有重要意义,并且使耳部图像与流行病学生物识别方式(例如虹膜)相当。耳朵图像还可以作为自动识别系统中其他生物特征识别方法的补充,并在其他信息不可靠甚至不可用时提供身份提示。例如,在监视应用中,人脸识别技术可能无法处理轮廓脸,耳朵可以充当有关身份识别信息的来源。
耳朵识别要点
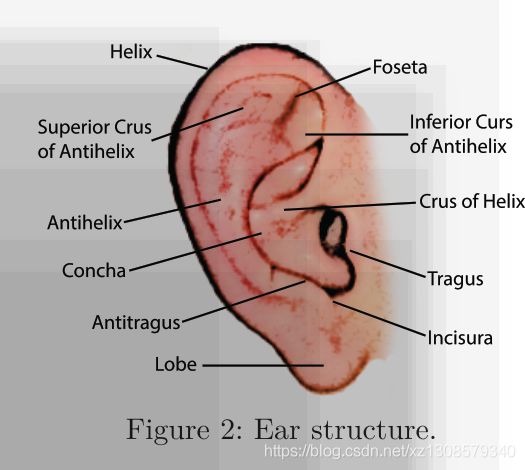
耳朵结构
人耳在怀孕早期发育,并且
在出生时已经完全形成。 由于其作为人类听觉器官的作用,耳朵具有一种特征性的结构(大部分情况下)在整个人群中共享。 外耳的外观由耳屏,反耳屏,螺旋线,反螺旋线,切齿,下垂和其他重要结构部分的形状定义,如图2所示。这些解剖软骨的形状不同 ,外观和相对
人与人之间的螺旋位置,因此可以用于身份识别
一般来说,一个人的左耳和右耳是
类似于这样的程度:使用自动技术将右耳与左耳匹配(反之亦然)比偶然性要好得多。 例如,Yan和Bowyer [17]在跨耳匹配实验中报告了大约90%的识别性能。 他们观察到,对于大多数人来说,左耳和右耳至少接近双侧对称,尽管有些人的两只耳朵的形状有所不同[17]。 Abaza和Ross在[18]中也报告了类似的发现。
文献表明,耳朵的大小会随时间而变化[19],[15],[16],[20]。 来自印度[21]和欧洲[20],[22],[23]的纵向研究发现,男女的耳朵长度随着年龄的增长而显着增加,而耳朵的宽度则保持相对恒定。 耳朵的生长如何影响自动识别系统的性能目前仍是一个尚待研究的问题。 这里的主要问题是在足够长的时间内缺少适当的数据集,这可能无法提供最终的结论性答案。 最近有一些有关此主题的初步研究出现,但只有间隔不到一年的特色图像被捕获[24]
耳朵识别的时间发展
750/5000
耳朵识别技术的时间发展
Niques可以分为手动(自动)时代和自动时代。 在自动前时代,发表了几项研究和经验观察,这些研究和经验表明耳朵具有识别身份的潜力[25],[26],[27],[28]。 Iannarelli于1989年对这个领域做出了最大的贡献之一[19],当时他发表了关于耳朵识别潜力的长期研究。 Iannarelli的开创性工作包括10 000多只耳朵,涉及识别的各个方面,例如兄弟姐妹,双胞胎和三胞胎的耳朵相似度,父母和孩子的耳朵外观之间的关系以及耳朵外观的种族差异[ 11]
1990年代标志着自动耳朵识别的开始-
民族。 在此期间开发了各种方法,并在文献中进行了介绍。 例如,在1996年,Burge和Burger [29]使用从耳朵曲线段的Voronoi图计算得到的邻接图来描述耳朵,在1999年,Moreno等人使用了邻接图。 [30]提出了第一个利用耳朵的几何特征和压缩网络的全自动耳朵识别程序。 2000年,Hurley等人。 [31]描述了一种基于力场变换的耳朵识别方法,事实证明该方法非常成功。 一年后的2001年,法医耳朵识别项目(FEARID)项目启动,标志着耳朵识别领域的第一个大型项目[32
随着新千年的开始,自动
耳识别技术开始受到生物识别界的关注,并且新技术被更频繁地引入。 2002年,Victor等人。 [33]在耳朵图像上应用主成分分析(PCA)并报告了有希望的结果。 2005年,尺度不变特征变换(SIFT)[34]首次用于耳朵图像,这提高了现有识别技术的性能水平。 Yuan等人在2006年开发了一种基于非负矩阵分解的方法。 [35]并应用于遮挡的和非遮挡的耳朵图像,具有竞争性的结果。在2007年,Nosrati等人提出了一种基于2D小波变换的方法。 [36],其后是基于对数Gabor小波的技术[37]。最近,在2011年,[38]中将局部二进制模式(LBP)用于耳朵图像描述,而后来的二值化统计图像特征(BSIF)和局部相位量化(LPQ)特征也证明可以成功完成此任务[39] ,[40],[41]。图1显示了耳部识别技术发展中主要里程碑的图形表示(上面简要讨论过)。
Ear Recognition Approaches
首先在输入图像中检测出轮廓脸,然后从检测到的区域中分割出耳朵。 然后将耳朵对准一些预定义的规范形式,并进行处理以解决照明的潜在变化。 从预处理的图像中提取特征,最后使用合适的分类技术基于计算出的特征进行身份识别。

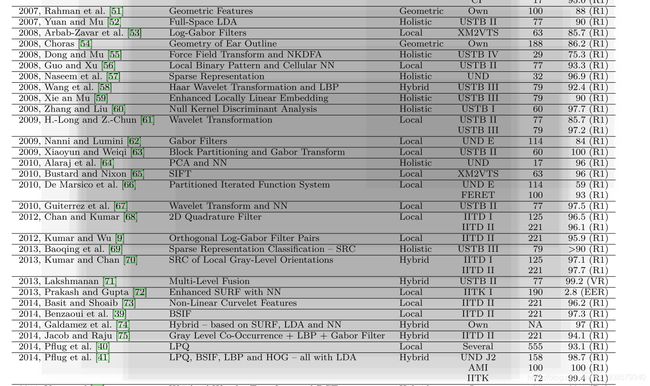
当前公开数据集

上一节中回顾的大多数数据集都是
在受控的实验室条件下进行。 在本节中,我们介绍带注释的Web Ears(AWE)数据集,该数据集在这方面与其他现有数据集有很大不同。 我们还介绍了用于耳朵识别的AWE Matlab工具箱。 数据集和工具箱均可从http://awe.fri.uni-lj.si公开获得。
一个。
A. AWE数据集的动机:大多数现有的用于评估耳朵识别技术的数据集都包含在控制的实验室设置中捕获的图像或在摄像机前摆在户外的人的轮廓照片。这些图像的可变性通常是有限的,并且可变性的来源是由数据集的作者预先选择的。这与人脸识别领域形成了鲜明的对比,在过去的十年中,研究重点转移到了完全不受控制的图像数据集上,这极大地促进了技术水平的提高。这种发展的基础是直接从网上收集的数据集,例如LFW [98],PubFig [99],FaceScrub [100],Casia WebFaces [101],IJB-A [102]等。这些数据集引入了在野外捕获的图像的概念,文字游戏表示图像是在不受控制的环境中获取的。这些数据集的困难为技术的改进提供了很大的空间,并促进了该领域的发展。
到今天为止,据报道耳识别的性能
技术在大多数可用数据集上已经超过了90%的1级识别率。 这一事实表明,该技术已经达到了可以轻松处理类似实验室环境中捕获的图像的成熟水平,并且需要更多具有挑战性的数据集来识别未解决的问题并为进一步的发展提供空间。 受到野外收集的人脸识别数据集成功的启发,我们从网络上收集了耳图像的新数据集,并将其提供给研究社区。
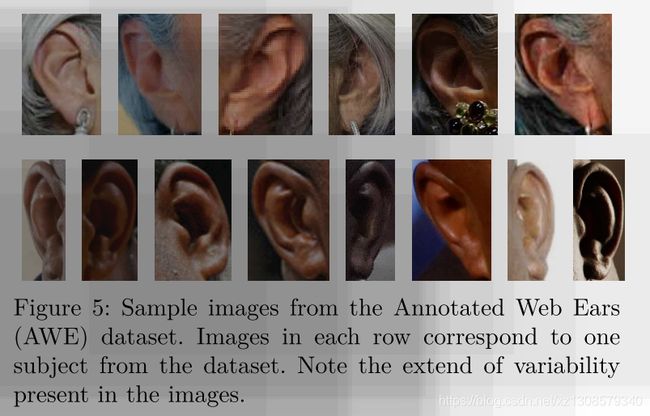
结构和注释:总计,数据集
包含100个主题的1000个耳朵图像。 每个对象有10张不同质量和尺寸的图像。 数据集中最小的图像为15×29像素,最大的为473×1022像素,平均图像大小为83×160像素。 耳朵图像被严格裁剪,并且不包含如图5所示的侧面。
数据集中的每个图像均由经过培训的人注释
研究人员根据以下类别进行分类:性别,种族,配件,遮挡,头部倾斜度,头部侧倾,头部偏航和头部侧面。 根据头部姿势估算俯仰角,横滚角和偏航角。 表III中显示了每个类别的可用标签,图6中显示了整个数据集的标签分布。此外,还在每个图像中标记了耳屏的位置。
3入


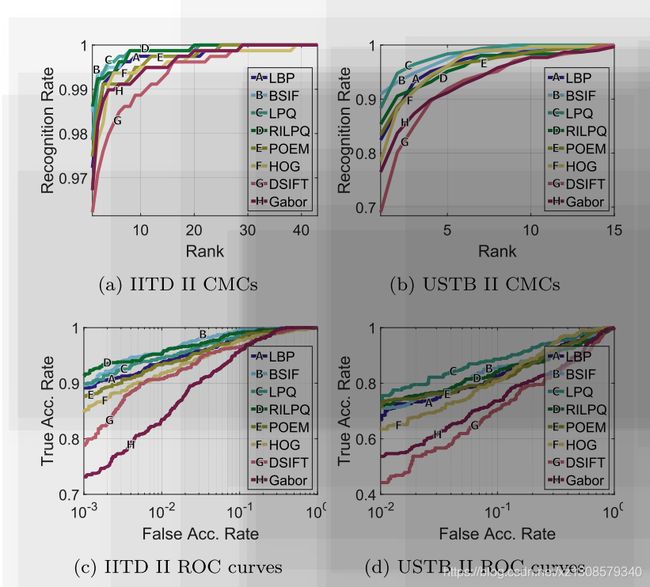
[15],[16]指出,有几个因素
关于耳朵识别的知识尚不十分清楚,为进一步探索提供了空间。这些因素包括:i)耳朵对称:一些研究发现许多对象的左耳和右耳接近对称,但是需要更多的研究来寻找在自动识别系统中利用这一事实的方法; ii)衰老:众所周知,耳朵的大小会随着年龄的增长而增加,例如[20],[22],[23],但这种影响如何影响自动技术的识别性能尚不清楚;这里的主要问题是缺少合适的数据集,无法详细分析模板老化的影响; iii)继承:正如[16]所指出的,Iannarelly [19]的工作表明外耳的某些特征可以被继承;这些特征是否可以通过自动技术识别并用于确定两个人是否相关,或者它们是否可能为自动识别系统带来错误源仍然是一个悬而未决的问题