SparkStreaming消费Kafka根据数据时间落地Hdfs,维护偏移量至kudu
一 环境信息项目依赖
scala 2.11.0 jdk 1.8
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<configuration>
<source>7source>
<target>7target>
configuration>
plugin>
plugins>
build>
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>2.4.0version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_2.11artifactId>
<version>2.4.0version>
dependency>
<dependency>
<groupId>org.apache.kudugroupId>
<artifactId>kudu-clientartifactId>
<version>1.10.0version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka-0-10_2.11artifactId>
<version>2.4.0version>
<exclusions>
<exclusion>
<groupId>org.lz4groupId>
<artifactId>lz4-javaartifactId>
exclusion>
<exclusion>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
exclusion>
<exclusion>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
exclusion>
<exclusion>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-slf4j-implartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.11artifactId>
<version>2.4.0version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql-kafka-0-10_2.11artifactId>
<version>2.4.0version>
<exclusions>
<exclusion>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
exclusion>
<exclusion>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
exclusion>
<exclusion>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-slf4j-implartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.47version>
dependency>
dependencies>
二 kudu表建表语句
CREATE TABLE default.kafka_offsit(
id bigint comment 'id',
groupid String comment '消費者組',
topic String comment '主題',
topic_partition int comment '分区号',
untiloffset STRING comment '偏移量',
PRIMARY KEY(id)
)
PARTITION BY HASH PARTITIONS 6
comment 'kafka偏移量表'
STORED AS KUDU TBLPROPERTIES ('kudu.num_tablet_replicas' = '1');
三 获取偏移量 查询kudu表
def getOffsetFromKudu(param:Map[String,String]): util.Map[TopicPartition, lang.Long] = {
val kudu_client = new KuduClient.KuduClientBuilder(param("kudu_master")).build()
val clumns: util.ArrayList[String] = new util.ArrayList[String]()
clumns.add("groupid")
clumns.add("topic")
clumns.add("topic_partition")
clumns.add("untiloffset")
val kuduTable = kudu_client.openTable(param("kudu_table_name"))
val kuduTableScaner = kudu_client.newScannerBuilder(kuduTable).setProjectedColumnNames(clumns)
val predicate = KuduPredicate.newComparisonPredicate(kuduTable.getSchema.getColumn("groupid"),KuduPredicate.ComparisonOp.EQUAL,param("groupId"))
val predicate2 = KuduPredicate.newComparisonPredicate(kuduTable.getSchema.getColumn("topic"),KuduPredicate.ComparisonOp.EQUAL,param("topic"))
kuduTableScaner.addPredicate(predicate).addPredicate(predicate2);
val scanner = kuduTableScaner.build()
val resMap: util.Map[TopicPartition, java.lang.Long] = new util.HashMap[TopicPartition,java.lang.Long]()
while (scanner.hasMoreRows) {
val row: RowResultIterator = scanner.nextRows()
while (row.hasNext) {
val line = row.next()
val topicPartition: TopicPartition = new TopicPartition(line.getString("topic"),line.getInt("topic_partition"))
resMap .put(topicPartition,line.getString("untiloffset").toLong)
}
}
kudu_client.close()
resMap
}
四 文件追加写类
1 AppendTextOutputFormat
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.Progressable;
import org.apache.hadoop.util.ReflectionUtils;
import java.io.DataOutputStream;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
public class AppendTextOutputFormat extends TextOutputFormat<Text, Text> {
protected static class MyLineRecordWriter<K, V> implements RecordWriter<K, V> {
private static final byte[] NEWLINE;
protected DataOutputStream out;
private final byte[] keyValueSeparator;
public MyLineRecordWriter(DataOutputStream out, String keyValueSeparator) {
this.out = out;
this.keyValueSeparator = keyValueSeparator.getBytes(StandardCharsets.UTF_8);
}
public MyLineRecordWriter(DataOutputStream out) {
this(out, "\t");
}
private void writeObject(Object o) throws IOException {
if (o instanceof Text) {
Text to = (Text)o;
this.out.write(to.getBytes(), 0, to.getLength());
} else {
this.out.write(o.toString().getBytes(StandardCharsets.UTF_8));
}
}
public synchronized void write(K key, V value) throws IOException {
boolean nullKey = key == null || key instanceof NullWritable;
boolean nullValue = value == null || value instanceof NullWritable;
if (!nullKey || !nullValue) {
/*if (!nullKey) {
this.writeObject(key);
}
if (!nullKey && !nullValue) {
this.out.write(this.keyValueSeparator);
}*/
if (!nullValue) {
this.writeObject(value);
}
this.out.write(NEWLINE);
}
}
public synchronized void close(Reporter reporter) throws IOException {
this.out.close();
}
static {
NEWLINE = "\n".getBytes(StandardCharsets.UTF_8);
}
}
@Override
public RecordWriter getRecordWriter(FileSystem ignored, JobConf job, String name, Progressable progress) throws IOException {
boolean isCompressed = getCompressOutput(job);
String keyValueSeparator = job.get("mapreduce.output.textoutputformat.separator", "\t");
if (!isCompressed) {
Path file = FileOutputFormat.getTaskOutputPath(job, name);
FileSystem fs = file.getFileSystem(job);
Path newFile = new Path(FileOutputFormat.getOutputPath(job), name);
FSDataOutputStream fileOut = null;
if (fs.exists(newFile)) {
//存在,追加写
fileOut = fs.append(newFile);
} else {
fileOut = fs.create(file, progress);
}
return new AppendTextOutputFormat.MyLineRecordWriter(fileOut, keyValueSeparator);
} else {
Class<? extends CompressionCodec> codecClass = getOutputCompressorClass(job, GzipCodec.class);
CompressionCodec codec = (CompressionCodec) ReflectionUtils.newInstance(codecClass, job);
Path file = FileOutputFormat.getTaskOutputPath(job, name + codec.getDefaultExtension());
FileSystem fs = file.getFileSystem(job);
Path newFile = new Path(FileOutputFormat.getOutputPath(job), name);
FSDataOutputStream fileOut = null;
if (fs.exists(newFile)) {
//存在,追加写
fileOut = fs.append(newFile);
} else {
fileOut = fs.create(file, progress);
}
return new AppendTextOutputFormat.MyLineRecordWriter(new DataOutputStream(codec.createOutputStream(fileOut)), keyValueSeparator);
}
}
}
2 RDDMultipleTextOutputFormat
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.RecordWriter;
import org.apache.hadoop.mapred.lib.MultipleTextOutputFormat;
import org.apache.hadoop.util.Progressable;
import java.io.IOException;
public class RDDMultipleTextOutputFormat extends MultipleTextOutputFormat<String, String> {
private AppendTextOutputFormat theTextOutputFormat = null;
public String generateFileNameForKeyValue(String key, String value, String name) {
//输出格式 /ouput/key/key.csv
//key 2020-02-06 value:data name:part-00000
// System.out.println(key + "/"+name);
return key + "/"+name;
}
@Override
protected RecordWriter getBaseRecordWriter(FileSystem fs, JobConf job, String name, Progressable progressable) throws IOException {
if (this.theTextOutputFormat == null) {
this.theTextOutputFormat = new AppendTextOutputFormat();
}
return this.theTextOutputFormat.getRecordWriter(fs, job, name, progressable);
}
}
五 维护偏移量至kudu表
def commitOffset(kafkaDataDstream:InputDStream[ConsumerRecord[String, String]],param:Map[String,String]): Unit ={
kafkaDataDstream.foreachRDD(rdd=>{
//获取kudu的表连接
val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
val kudu_client = new KuduClient.KuduClientBuilder(param("kudu_master")).build()
val kuduTable = kudu_client.openTable(param("kudu_table_name"))
val kuduSession = kudu_client.newSession
import org.apache.kudu.client.SessionConfiguration
kuduSession.setFlushMode(SessionConfiguration.FlushMode.MANUAL_FLUSH)
kuduSession.setMutationBufferSpace(3000)
for(offset<-offsetRanges){
val upsert = kuduTable.newUpsert()
upsert.getRow.addLong("id",(param("groupId")+param("topic")).hashCode+offset.partition)
upsert.getRow.addString("groupid",param("groupId"))
upsert.getRow.addString("topic",param("topic"))
upsert.getRow.addInt("topic_partition",offset.partition)
upsert.getRow.addString("untiloffset",offset.untilOffset.toString)
kuduSession.flush
kuduSession.apply(upsert)
}
kuduSession.close()
})
}
六 获取kafka Dstream
/**
* 创建kafka 的dstream
* @param ssc
* @param param
* @return
*/
def getKafkaDstream(ssc: StreamingContext, param:Map[String,String]): InputDStream[ConsumerRecord[String, String]] ={
import scala.collection.JavaConversions._
val kafkaParams: Map[String, Object] = Map[String, Object](
"bootstrap.servers" -> param("boker_list"),
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> param("groupId"),
"auto.offset.reset" -> param("type"), //earliest
"enable.auto.commit" -> param("isAutoCommit")//isAutoCommit
)
var fromOffsets: util.Map[TopicPartition, lang.Long] = new util.HashMap[TopicPartition, lang.Long]()
// var fromOffsets: util.Map[TopicPartition, java.lang.Long] =new util.HashMap[TopicPartition, java.lang.Long]();
val topics = Seq(param("topic")) //topic
val isAutoCommit = param("isAutoCommit")
if("false".equalsIgnoreCase(isAutoCommit)){
fromOffsets = getOffsetFromKudu(param);
}
import org.apache.spark.streaming.kafka010._
if(fromOffsets==null || fromOffsets.isEmpty ){
KafkaUtils.createDirectStream[String,String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams)
)
}else{
KafkaUtils.createDirectStream[String,String](
ssc,
LocationStrategies.PreferConsistent,
Subscribe[String, String](topics, kafkaParams, fromOffsets)
)
}
}
七 测试Main方法
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("appName").setMaster("local[*]")
.set("spark.streaming.backpressure.enabled", "true") // 开启被压
.set("spark.streaming.kafka.maxRatePerPartition", "5") // 每秒 每个分区消费10条数据
.set("spark.streaming.stopGracefullyOnShutdown", "true"); // 优雅关闭
System.setProperty("HADOOP_USER_NAME", "hdfs")
val ssc: StreamingContext = new StreamingContext(conf, Seconds(3)) // 3 秒一个批次
val param: Map[String, String] = Map[String, String] (
"boker_list" -> "10.83.0.47:9092",
"groupId" -> "gc_test",
"topic" -> "maxwells",
"kudu_table_name" -> "impala::default.kafka_offsit",
"isAutoCommit" -> "false",
"type" -> "earliest",
"kudu_master" -> "node129:7051"
)
val kafkaDstream: InputDStream[ConsumerRecord[String, String]] = getKafkaDstream(ssc,param)
// 转换数据结构
val valueStream: DStream[(String, String)] = kafkaDstream.mapPartitions(it => {
var strings = List[(String,String)]()
while (it.hasNext) {
val consumer: ConsumerRecord[String, String] = it.next()
val data = consumer.value()
val jsonData: fastjson.JSONObject = JSON.parseObject(data)
val deal_date = jsonData.getJSONObject("data").getString("DEAL_DATE")
strings = (deal_date,data)::strings
}
strings.iterator
})
//按照key 做为文件夹的名称 写出数据
// key 为对应的时间 /user/admin/test00000/2020-02-06/part-00000
// key value 类型的rdd 写出去的时候 com.demo.gc.AppendTextOutputFormat.MyLineRecordWriter.writeObject 这里面 注释掉写key的代码
valueStream.foreachRDD(rdd=>{
rdd.saveAsHadoopFile("/user/admin/test00000/",classOf[String],classOf[String],classOf[RDDMultipleTextOutputFormat])
})
//提交offset
Thread.sleep(1000)
commitOffset(kafkaDstream,param)
ssc.start()
ssc.awaitTermination()
}
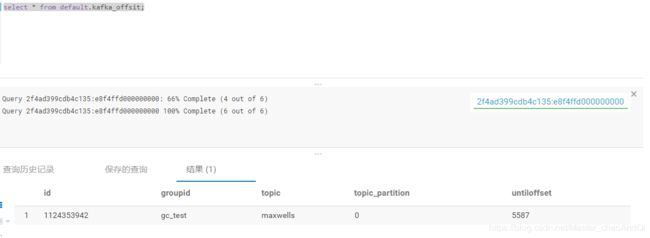
八 测试结果截图