XPath表达式
目录
选取节点
谓语(Predicates)
选取未知节点
选取若干路径
实战:
/bookstore或bookstore:根节点
/bookstore/book[3]/year/text()
//book:所有的book元素
//book[1]/price
//book[1]/price/.:当前节点
//book[1]/price/..:当前节点的父节点
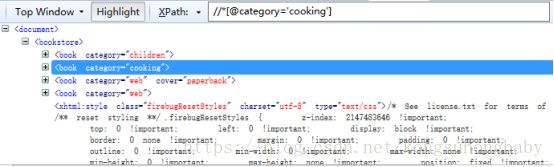
//*[@category='cooking']:属性为cooking的元素
//*[@category='web' and @cover='paperback'] :属性为web的有两个,可以用and加限定条件继续匹配
//*[@category='web' or @cover='paperback']
//*[not(@category='web')]
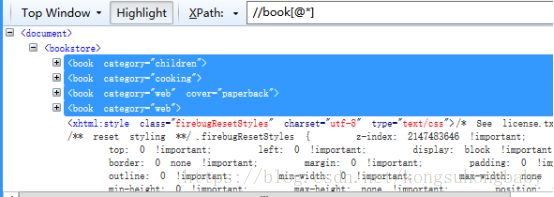
//book[@*]:所有有属性的book节点
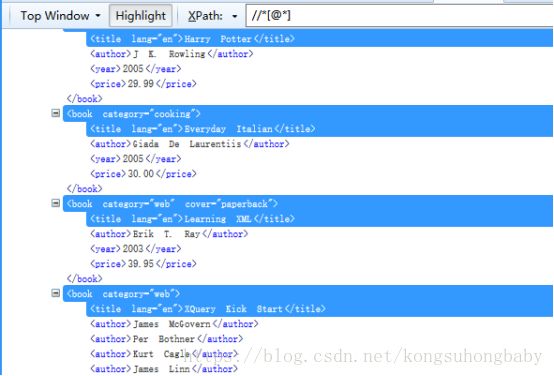
//*[@*]:所有有属性的元素
/bookstore//price:绝对和相对的结合,找到所有的price
//@cover:相对查找属性cover
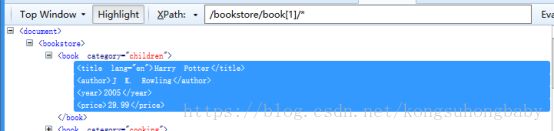
/bookstore/book[1]/*:第一个book下的全部内容
/bookstore/book[1]/title[@*]:第一个book的title属性
/bookstore//price[text()>30]或者/bookstore//price[.>30]:所有price大于30的元素亲属关系匹配
//book[1]/year[.=2005] 或者//book[1]/year[.=2005]/following-sibling::*:找到year节点的下一级price
//book[1]/year[.=2005]/following-sibling::*:找到year节点的上一级(有两个,可以限定一下)
//book[1]/year[.=2005]/preceding-sibling::title
//book[1]/year[.=2005]/parent::*:找到父级元素
基于最后一个book找到上一个book的year节点:
//*[text()='Per Bothner']/parent::*:基于文本Per Bothner找到父元素
xpath常用函数
定位原则
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档节点(或称为根节点)。具体还可参考W3C的课程:http://www.w3school.com.cn/xpath/index.asp
选取节点:
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选的。路径表达式:
| 表达式 |
描述 |
| nodename |
选取此节点的所有子节点。 |
| / |
从根节点选取。 |
| // |
从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . |
选取当前节点。 |
| .. |
选取当前节点的父节点。 |
| @ |
选取属性。 |
谓语(Predicates)
放在方括号[]中,相当于筛选条件,用来查找[]中指定的特定节点或者包含某个指定的值的节点。
例子
一些带有谓语的路径表达式和结果:
| 路径表达式 |
结果 |
| /bookstore/book[1] |
选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] |
选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] |
选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] |
选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] |
选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang='eng'] |
选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] |
选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title |
选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 |
描述 |
| * |
匹配任何元素节点。 |
| @* |
匹配任何属性节点。 |
| node() |
匹配任何类型的节点。 |
例子
| 路径表达式 |
结果 |
| /bookstore/* |
选取 bookstore 元素的所有子元素。 |
| //* |
选取文档中的所有元素。 |
| //title[@*] |
选取所有带有属性的 title 元素。 |
选取若干路径
在路径表达式中使用“|”运算符可以选取若干个路径。
例子
| 路径表达式 |
结果 |
| //book/title | //book/price |
选取 book 元素的所有 title 和 price 元素。 |
| //title | //price |
选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price |
选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
实战:
xml例子:http://www.w3school.com.cn/example/xmle/books.xml
火狐浏览器:47版本
/bookstore或bookstore:根节点

/bookstore/book[3]/year/text()
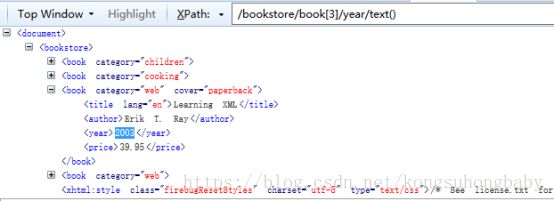
//book:所有的book元素
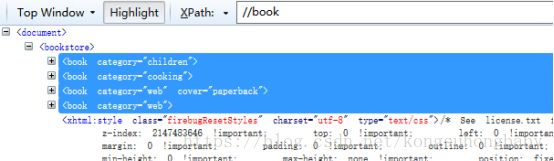
//book[1]/price
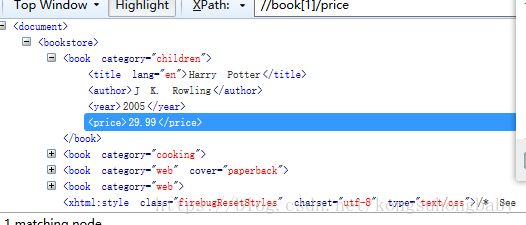
//book[1]/price/.:当前节点

//book[1]/price/..:当前节点的父节点
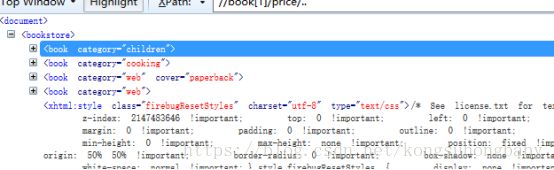
//*[@category='cooking']:属性为cooking的元素
//*[@category='web' and @cover='paperback'] :属性为web的有两个,可以用and加限定条件继续匹配

//*[@category='web' or @cover='paperback']

//*[not(@category='web')]

//book[@*]:所有有属性的book节点
//*[@*]:所有有属性的元素
/bookstore//price:绝对和相对的结合,找到所有的price

//@cover:相对查找属性cover

/bookstore/book[1]/*:第一个book下的全部内容
/bookstore/book[1]/title[@*]:第一个book的title属性

/bookstore//price[text()>30]或者/bookstore//price[.>30]:所有price大于30的元素
.和text()作用一样
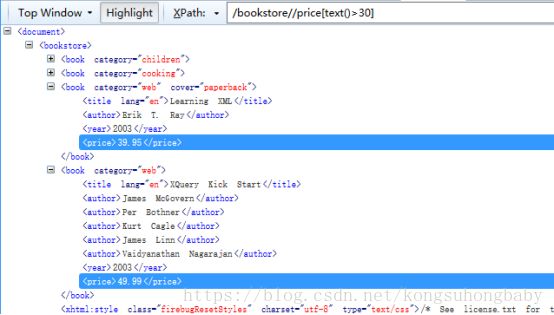
/bookstore/*[price>30]:所有price大于30的book元素

/bookstore//price[.!=49.99]:找到了不等于49.99的price

亲属关系匹配
| 例子 |
结果 |
| child::book |
选取所有属于当前节点的子元素的 book 节点。 |
| attribute::lang |
选取当前节点的 lang 属性。 |
| child::* |
选取当前节点的所有子元素。 |
| attribute::* |
选取当前节点的所有属性。 |
| child::text() |
选取当前节点的所有文本子节点。 |
| child::node() |
选取当前节点的所有子节点。 |
| descendant::book |
选取当前节点的所有 book 后代。 |
| ancestor::book |
选择当前节点的所有 book 先辈。 |
| ancestor-or-self::book |
选取当前节点的所有 book 先辈以及当前节点(如果此节点是 book 节点) |
| child::*/child::price |
选取当前节点的所有 price 孙节点。 |
| parent::* |
找到父级元素 |
| following::* |
选取文档中当前节点的结束标签之后的所有节点 |
| preceding::* |
选取文档中当前节点的开始标签之前的所有节点。 |
| preceding-sibling::* |
选取当前节点之前的所有同级节点 |
| following-sibling::* |
选取当前节点之后的所有同级节点 |
| descendant::* |
选取当前节点的所有后代元素(子、孙等) |
//book[1]/year[.=2005] 或者//book[1]/year[.=2005]/following-sibling::*:找到year节点的下一级price

//book[1]/year[.=2005]/following-sibling::*:找到year节点的上一级(有两个,可以限定一下)

//book[1]/year[.=2005]/preceding-sibling::title
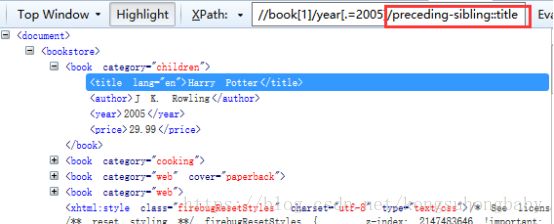
//book[1]/year[.=2005]/parent::*:找到父级元素

//book[1]/year[.=2005]/parent::*/descendant::price:找到

基于最后一个book找到上一个book的year节点:
//book[last()]/preceding-sibling::*[1]/year
//book[last()]/preceding::year[1]

基于属性cover再找到下一book的最后一个author
//*[@cover]/following::*[1]/author[last()]:
//*[@cover]/following::author[last()]
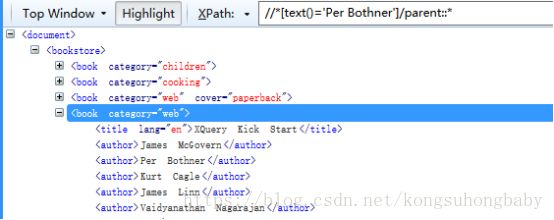
//*[text()='Vaidyanathan Nagarajan']

//*[text()='Per Bothner']/parent::*:基于文本Per Bothner找到父元素
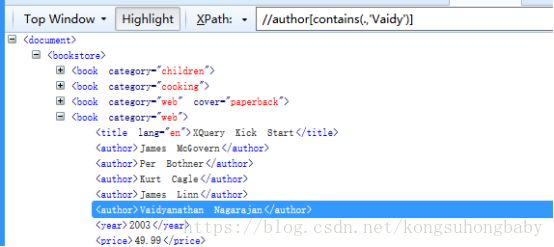
//author[contains(.,'Vaidy')]:文本中包含'Vaidy'的元素,前面的点代表的是文本,也可是写text()
xpath常用函数
| 实例 |
返回值 |
| last() |
返回当前上下文中的最后一个节点的位置号码数 |
| position() |
返回当前节点的位置的数字,位于第多少个 |
//book[position()=2]等价于//book[2]

例子:
| 路径表达式 |
结果 |
| //div[last()] |
最后一个div |
| //div[last()-1] |
倒数第二个div |
| //div[position()<3] |
前两个div |
| //div[@id='id3']//p[last()] |
第三个div中最后一个p标签对象 |
| //div[@href='http://www.baidu.com'] |
选取连接为http://www.baidu.com的属性 |
| //*[@id='id3']//p[contain(.,'20')] |
在第3个div中找包含20的文本节点 |
| //*[@id='id3']//p[contain(.,'20')]//fowing-sibiling::p |
选取包含字符串20文本节点的下一个节点的p节点 |
定位原则:
- 用id定位
- 用元素文本
- 用元素的唯一属性
- 用元素的多个属性组合
- 找到已查找的元素,然后基于此元素的相对位置定位
练习:
1.定位百度输入框、按钮、更多产品
先选择元素
//input[@id='kw']
//input[@id='su']或者//input[@value='百度一下']
//div[.='更多产品']
2.定位hao123的连接
//a[@href="https://www.hao123.com"]或者
//a[.='hao123']
3.定位京东账号登录时的用户名、密码和登录按钮
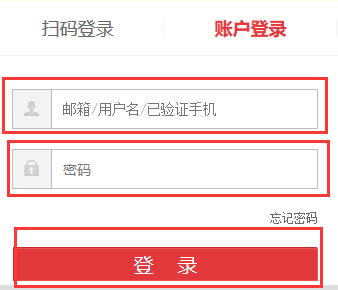
//input[@id='loginname']或者//input[@name="loginname"]
//input[@id='nloginpwd']
//a[@id='loginsubmit']或者//div[@class="login-btn"]/a[contains(.,'登')]
4.定位搜狐邮箱的写邮件按钮
//li[.='写邮件']
5.定位搜狐邮箱写邮件的相关内容
收件人:
找到大的输入框
//div[@arr="mail.to_render"]

找到小的输入框:
//span[.='收件人']/following-sibling::div//span/input[@maxlength="200"])

主题://input[@ng-model="mail.subject"]或者//span[.='主 题']/following-sibling::input
添加附件://span[.='添加附件(50M)']
14px://div[@title="字号"]/div/div[1]
邮件正文://p
发送按钮://span[.='发送']