【转】Zookeeper的前世今生
原文链接:https://www.imooc.com/article/45213
到底发生了什么?
在电商架构中,早期是单体架构,可以很快的解决交互问题和产品初期的迭代。但是随着架构的发展,后端无法支撑大流量。一开始的解决办法是增加服务器等垂直解决方法,但是这样的效率太低并且成本太高。因此开发者开始考虑水平伸缩来提高整体的性能。
首先是对产品的拆分:按照类型拆分成不同的模块,那么模块之间的交互就需要实现远程调用,比如webservice。这样其实就简单的形成了一个分布式架构。服务越来越多,我们就拆分的越来越细,随着流量不断提升,后端规模越来越大。举个例子:用户调用订单服务,它是通过http协议来调用,那么首先订单服务那必须给用户一个地址。如果说订单系统是一个大的集群,那么可能我们就需要维护多个这样的地址。那么应该如何解决大规模地址管理?集群里的地址如何去转发?如果其中一个节点down机了怎么办,怎么去管理服务动态上下线感知?
那我们就通过解决以上三个问题来引出本文的主角---Zookeeper
我们可以考虑设置一个中间件,它的存在可以让我们的服务发布的时候注册上去,充当一个电话本,记住你所有的地址,并且及时了解你是不是断开。用户服务只需要拿到中间件的地址,就可以获得对应的相关的调用的目标服务的信息,拿到这个信息,根据负载均衡算法,就可以做一个转发。
Zookeeper是一个什么东西呢?它是一个文件存储类似的树型结构,entry是key-value。每个子节点由父节点管理,子节点是父节点详细的分类。比如说,对于订单服务系统,它的子节点存放着各种地址。Zookeeper适不适合作为一个注册中心?很多人说不是很合适,但是目前大部分企业仍然用它来做注册中心的功能。Zookeeper的学术名称为分布式协调服务,它的本意是解决分布式锁的,比如说几个服务访问共享资源,就会出现资源竞争的问题,这时候就会需要一个协调者来解决这个问题,Zookeeper就是用来解决这个问题的,可以看作一个交警。这样一来共享资源就变成了一个单点访问资源,你先来我中间件里来,我再判断让不让你去访问。当然为了保持单点的特点,Zookeeper一般是以集群出现,在满足单点的功能,提高其可用性。集群的出现带来的问题众所周知,那就是数据同步。Zookeeper内部角色分为Leader、Follower、observer,数据提交方式基于二阶提交,写数据写在follower上,其他的follower去同步数据。请求命令放在leader上,然后让其他的节点知道,这里满足一个CAP原则。
Zookeeper作为一个分布式协调服务,目标是为了解决分布式架构中一致性问题。
Zookeeper客户端可以提供增删改查节点的功能,删除的时候必须一层一层的删除。而且节点具有唯一性,可以参考电脑文件结构。同时节点还分为临时节点 -e和持久化节点、有序节点 -s和无序节点。
Zookeeper应用场景
注册中心、配置中心(和注册中心大同小异,类似于application.properties,用来统一维护配置信息)、负载均衡(知道机器的状态以及选举leader)和分布式锁。
[zk: localhost:2181(CONNECTED) 0] create /userservice 0Created /userservice
[zk: localhost:2181(CONNECTED) 2] ls /[zookeeper, userservice]
[zk: localhost:2181(CONNECTED) 3] ls /userservice
[]配置zoo.cfg文件,将三个服务器的ip、访问Zookeeper的端口以及选举的端口配置好
server.1=10.10.101.7:2888:3888server.2=10.10.101.104:2888:3888server.3=10.10.101.108:2888:3888
server.n=ip:prot:prot
其中n在 /tmp/zookeeper/myid里配置除了Leader和Follower之外,还有一个Observer的节点,它的作用是用来监控整个集群的状态。
Zookeeper特性分析
ACL
ACL属于一种权限控制,控制你创建的文件夹(节点)的0访问权限。它提供了create、write、read、delete和admin五种权限。
角色
leader用来处理事务请求的,就是所有的添加修改删除都会去leader那,非事务请求(查询)可能会落到任一节点上。
数据模型
数据模型是Zookeeper里较为核心的东西,它的结构类似于树,也类似于电脑的文件管理系统。节点特性分为持久化和有序性,每个znode可以保存少量数据。
会话
客户端和服务端连接会建立会话
进阶
Zookeeper的技术层面由来
假设分布式系统中有三个节点作为一个集群,在这个集群里运行一个任务,所以每个节点都有权限去执行这个任务。那我我有几个问题想问:
(1)怎么保证各个节点数据一致?
(2)怎么保证任务只在一个节点执行?
(3)如果在执行任务的1节点挂了,那么其他的节点如何发现并接替任务?
(4)它们对于共享资源是怎么处理的?
我们可以先将节点注册到Zookeeper中,然后因为节点有顺序性,所以说我们第一个看到的节点就认为他是最具优先权的,那么它就可以去做这个操作,这就是Zookeeper起到的能够给集群节点进行一个协调的作用。
那么按照上面的几个问题,如果我们想设计一个中间件,那么应该注意哪些事情呢?
(1)单点故障
存在leader、follower节点。同时也会分担请求(高可用、高性能)。
(2)为啥集群要有master
(3)如果集群中的maser挂了怎么办?数据如何恢复?如何选举?
Zookeeper选举使用了ZAB协议
(4)如何保证数据一致性?(分布式事务)
2PC(二阶提交):当一个事务涉及多个节点提交,为了保证进行,引入一个协调者,通过协调者控制整个集群工作的顺利进行。当一个事务开始时,由协调者将请求发给所有节点,然后节点若能执行,则向协调者发起可以执行请求。如果一个参与者失败,不能进行事务执行,那么其他节点都将发起回滚提交。否则,所有节点顺利提交,这个事务顺利完成。
Zookeeper集群内部成员介绍:
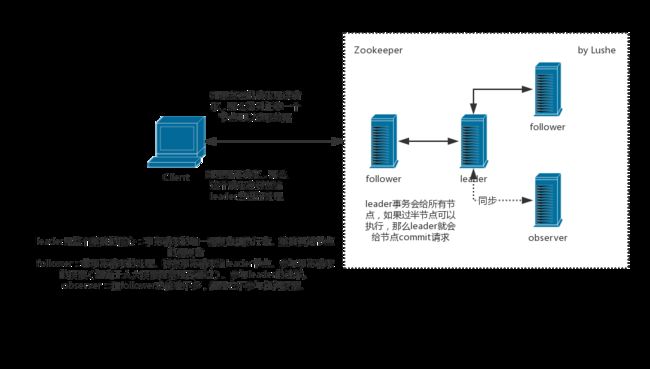
为什么Zookeeper集群是2*n+1的数量?
因为Zookeeper集群如果正常对外服务,必须有投票机制,集群内部有过半节点正常服务,保证投票能够有结果。而且能够保证对n个服务器的容灾处理。
ZAB协议
它是Zookeeper里面专门用来处理崩溃恢复的原子广播协议,依赖ZAB协议实现分布式数据一致性。如果集群中leader出现了问题,ZAB协议就会进行恢复模式并选举产生新的leader,选举产生之后,并且集群中有过半节点与leader数据同步之后,ZAB就会退出恢复模式。
消息广播:属于一个简化的二阶提交机制,leader收到请求后,会给事务请求赋予一个zxid,可以通过zxid的大小去比较生成因果有序这个特性。leader会给每个follower给一个FIFO队列,然后将带有zxid的消息作为一个提案分发给所有的leader,follower收到请求后,将提案写入磁盘,并给leader发送ack。如果leader收到半数以上的ack,就确定这个消息要执行,然后给所有的follower发送commit指令,同时也会在本地执行这个请求。如果没有通过,所有节点执行回滚。
崩溃恢复:leader挂掉之后,那么就需要恢复选举和数据。当leader失去了过半节点联系、leader挂了这两种情况发生,集群就会进入崩溃恢复阶段。对于数据恢复来说:(1)已经被处理的消息不能丢失,也就是来个栗子:当follower收到commit之前,leader挂掉了,怎么办?这时部分节点收到commit,部分节点没有收到,这时ZAB协议保证已经处理的消息不能被丢失,被丢弃的消息不能再次出现(当leader节点收到事务请求之后,在生成提案时挂了,那么新选举的leader节点要跳过这个消息)。
ZAB协议需要满足这两个要求,必须设计出算法。
ZAB协议中保证选举出来的leader有着整个集群zxid最大的提案,这样第一是保证新的leader之前是正常工作的,第二是因为zxid是64位的,高32为epoch编号,每当leader选举产生一个新的leader,新的leader的epoch号就+1,低32位是消息计数器,每当接受一条消息,就+1。新的leader被选举之后就会清空。这样可以保证老的leader挂掉之后,不可能被再次选举。可以把epoch看做成皇帝的年号,现在统治的事哪个皇帝。
zxid在上面已经简单介绍了,下面说一下它的简单特性:Zookeeper中所有提议在被提出时都会加上zxid。
leader选举
基于fast leader选举,基于几个方面:zxid最大会设置成leader,epoch;myid(服务器id),myid越大,在leader选举权重中越大;事务id,事务id越大,表示事务越新;epoch(逻辑时钟)每一次投票,epoch都会递增;选举状态:LOOKING->LEADING(FOLLOWING、OBSERVING)
启动的时候:每个Server都会发起一个投票,每个节点都会先将自己作为一个leader,并将自己的zxid、myid等信息发给其他节点。其他节点会进行比较:zxid相同就检查myid,myid大的会作为leader,之后开始进行统计投票,最后选出leader。
前一个leader挂掉:所有节点编程looking状态,然后会查看其他节点的信息,来做出投票。
看一下源码理解一下
protected void initializeAndRun(String[] args) throws ConfigException, IOException
{
org.apache.zookeeper.server.quorum.QuorumPeerConfig config = new org.apache.zookeeper.server.quorum.QuorumPeerConfig(); if (args.length == 1) {
config.parse(args[0]);
} // Start and schedule the the purge task
DatadirCleanupManager purgeMgr = new DatadirCleanupManager(config
.getDataDir(), config.getDataLogDir(), config
.getSnapRetainCount(), config.getPurgeInterval());
purgeMgr.start(); //判断是单机还是集群模式
if (args.length == 1 && config.servers.size() > 0) {
runFromConfig(config);
} else {
LOG.warn("Either no config or no quorum defined in config, running "
+ " in standalone mode"); // there is only server in the quorum -- run as standalone ZooKeeperServerMain.main(args);
}
}
因为只有集群模式才会有选举,这时候我们会进入到runFromConfig方法中:
public void runFromConfig(org.apache.zookeeper.server.quorum.QuorumPeerConfig config) throws IOException { try {
ManagedUtil.registerLog4jMBeans();
} catch (JMException e) {
LOG.warn("Unable to register log4j JMX control", e);
}
LOG.info("Starting quorum peer"); try {
ServerCnxnFactory cnxnFactory = ServerCnxnFactory.createFactory();
cnxnFactory.configure(config.getClientPortAddress(),
config.getMaxClientCnxns());
quorumPeer = new org.apache.zookeeper.server.quorum.QuorumPeer();
quorumPeer.setClientPortAddress(config.getClientPortAddress());
quorumPeer.setTxnFactory(new FileTxnSnapLog( new File(config.getDataLogDir()), new File(config.getDataDir())));
quorumPeer.setQuorumPeers(config.getServers());
quorumPeer.setElectionType(config.getElectionAlg());
quorumPeer.setMyid(config.getServerId());
quorumPeer.setTickTime(config.getTickTime());
quorumPeer.setMinSessionTimeout(config.getMinSessionTimeout());
quorumPeer.setMaxSessionTimeout(config.getMaxSessionTimeout());
quorumPeer.setInitLimit(config.getInitLimit());
quorumPeer.setSyncLimit(config.getSyncLimit());
quorumPeer.setQuorumVerifier(config.getQuorumVerifier());
quorumPeer.setCnxnFactory(cnxnFactory);
quorumPeer.setZKDatabase(new ZKDatabase(quorumPeer.getTxnFactory()));
quorumPeer.setLearnerType(config.getPeerType());
quorumPeer.setSyncEnabled(config.getSyncEnabled());
quorumPeer.setQuorumListenOnAllIPs(config.getQuorumListenOnAllIPs());
quorumPeer.start();
quorumPeer.join();
} catch (InterruptedException e) { // warn, but generally this is ok
LOG.warn("Quorum Peer interrupted", e);
}
}
可以看到,它会从配置文件中加载一些信息,最后启动start来开始进行选举。
@Override
public synchronized void start() {
loadDataBase();
cnxnFactory.start();
//开始进行选举Leader startLeaderElection(); super.start();
}
synchronized public void startLeaderElection() { try {
currentVote = new org.apache.zookeeper.server.quorum.Vote(myid, getLastLoggedZxid(), getCurrentEpoch());
} catch(IOException e) {
RuntimeException re = new RuntimeException(e.getMessage());
re.setStackTrace(e.getStackTrace()); throw re;
} for (QuorumServer p : getView().values()) { if (p.id == myid) {
myQuorumAddr = p.addr; break;
}
} if (myQuorumAddr == null) { throw new RuntimeException("My id " + myid + " not in the peer list");
} if (electionType == 0) { try {
udpSocket = new DatagramSocket(myQuorumAddr.getPort());
responder = new ResponderThread();
responder.start();
} catch (SocketException e) { throw new RuntimeException(e);
}
} this.electionAlg = createElectionAlgorithm(electionType);
}
从上段代码的一开始,表示它会存储三个信息:myid、zxid和epoch,然后配置选举类型来使用选举算法,
protected org.apache.zookeeper.server.quorum.Election createElectionAlgorithm(int electionAlgorithm){
org.apache.zookeeper.server.quorum.Election le=null;
//TODO: use a factory rather than a switch
switch (electionAlgorithm) { case 0:
le = new org.apache.zookeeper.server.quorum.LeaderElection(this); break; case 1:
le = new org.apache.zookeeper.server.quorum.AuthFastLeaderElection(this); break; case 2:
le = new org.apache.zookeeper.server.quorum.AuthFastLeaderElection(this, true); break; case 3:
qcm = new org.apache.zookeeper.server.quorum.QuorumCnxManager(this);
org.apache.zookeeper.server.quorum.QuorumCnxManager.Listener listener = qcm.listener; if(listener != null){
listener.start();
le = new org.apache.zookeeper.server.quorum.FastLeaderElection(this, qcm);
} else {
LOG.error("Null listener when initializing cnx manager");
} break; default: assert false;
} return le;
}
这里面提供着一些选举算法,最后会设置一个负责选举的IO类,然后启动来进行选举。
本文思路来源于《从Paxos到Zookeeper:分布式一致性原理与实践》一书
作者:慕仙森
链接:https://www.imooc.com/article/45213
来源:慕课网