GoogleNet、AleXNet、VGGNet、ResNet等总结
-
文章目录
- 一、经典的图像识别深度学习模型面世时间
- 1.1 VGG、AlexNet和Inception历史背景
- 1.2 DNN 和 CNN
- 1.3 LeNet
- 二、AleXNet (8层)
- 2.1 AlexNet介绍
- 2.2 AleXNet 网络结构
- 2.3 Relu 激活函数解释
- 2.4 防止过拟合
- 三、VGG
- 3.1 VGG 的配置
- 3.2 VGG 配置比较
- 3.3 VGG 的block组成
- 3.4 VGG 特点相同卷积核
- 四、GoogleNet 即 Inception 结构
- 4.1 GoogleNet介绍
- 4.2 Inception 架构解释
- 4.3 inception
- 4.3.1 inception V1 总结
- 4.3.2 inception V2 总结
- 4.3.3 inception V3 总结
- 4.3.4 inception V4 总结
- 4.3.5 Xception 总结
- 4.3.6 Inception V3 和 Xception 架构区别
- 4.4 Inception 详情
- 五 ResNet 之Residual 残差网络和dentity mapping(恒等映射)
- 5.1 ResNet 介绍
- 5.2 ResNet 架构特点Residual
- 5.3 ResNet 和 Inception 相结合
- 5.4 ResNeXt 是ResNet的极限版本
- 六、DenseNet
- 6.1 DenseNet 介绍
- 6.2 DenseNet 特点
- 6.3 DenseNet 密集连接
- 总结
- 有趣的事,Python永远不会缺席
- 证书说明
数据和模型 https://blog.csdn.net/u010986753/article/details/98526886
一、经典的图像识别深度学习模型面世时间
1.1 VGG、AlexNet和Inception历史背景
VGG-Net 的泛化性能非常好,常用于图像特征的抽、目标检测候选框生成等。VGG 最大的问题就在于参数数量,VGG-19 基本上是参数量最多的卷积网络架构。这一问题也是第一次提出 Inception 结构的 GoogLeNet 所重点关注的,它没有如同 VGG-Net 那样大量使用全连接网络,因此参数量非常小。
AlexNet,它本质上就是扩展 LeNet 的深度,并应用一些 ReLU、Dropout 等技巧。AlexNet 有 5 个卷积层和 3 个最大池化层,它可分为上下两个完全相同的分支,这两个分支在第三个卷积层和全连接层上可以相互交换信息。与 Inception 同年提出的优秀网络还有 VGG-Net,它相比于 AlexNet 有更小的卷积核和更深的层级。
GoogLeNet 最大的特点就是使用了 Inception 模块,它的目的是设计一种具有优良局部拓扑结构的网络,即对输入图像并行地执行多个卷积运算或池化操作,并将所有输出结果拼接为一个非常深的特征图。因为 1*1、3*3 或 5*5 等不同的卷积运算与池化操作可以获得输入图像的不同信息,并行处理这些运算并结合所有结果将获得更好的图像表征。
总结:
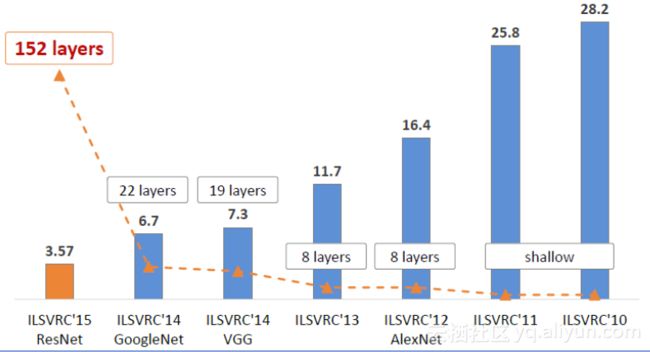
ILSVRC(ImageNet大规模视觉识别挑战赛)每年都不断被深度学习刷榜,随着模型变得越来越深,Top-5的错误率也越来越低,目前降低到了3.5%附近,而人类在ImageNet数据集合上的辨识错误率大概在5.1%,也就是目前的深度学习模型识别能力已经超过了人类。
1.2 DNN 和 CNN
CNN:在卷积神经网络中,卷积操作和池化操作有机的堆叠在一起,一起组成了CNN的主干;
DNN:DNN其实是一种架构,是指深度超过几个相似层的神经网络结构,一般能够达到几十层,或者由一些复杂的模块组成。
1.3 LeNet
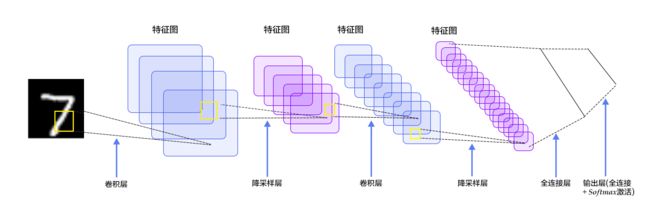
LeNet是卷积神经网络的祖师爷LeCun在1998年提出,LeNet-5(-5表示具有5个层)是一种用于手写体字符识别的非常高效的卷积神经网络。其结构:输入的二维图像,先经过两次卷积层到池化层,再经过全连接层,最后使用softmax分类作为输出层,LeNet-5包含七层。LeNet-5跟现有的conv->pool->ReLU的套路不同,它使用的方式是conv1->pool->conv2->pool2再接全连接层,但是不变的是,卷积层后紧接池化层的模式依旧不变。
手写数字识别 CNN MNIST_data LeNet https://blog.csdn.net/u010986753/article/details/96894733
各层参数详解:
- INPUT层-输入层:首先是数据 INPUT 层,输入图像的尺寸统一归一化为32*32。
注意:本层不算LeNet-5的网络结构,传统上,不将输入层视为网络层次结构之一。 - C1层-卷积层
详细说明:对输入图像进行第一次卷积运算(使用 6 个大小为 5*5 的卷积核),得到6个C1特征图(6个大小为28*28的 feature maps, 32-5+1=28)。我们再来看看需要多少个参数,卷积核的大小为5*5,总共就有6*(5*5+1)=156个参数,其中+1是表示一个核有一个bias。对于卷积层C1,C1内的每个像素都与输入图像中的5*5个像素和1个bias有连接,所以总共有156*28*28=122304个连接(connection)。有122304个连接,但是我们只需要学习156个参数,主要是通过权值共享实现的。 - S2层-池化层(下采样层)
详细说明:第一次卷积之后紧接着就是池化运算,使用 2*2核 进行池化,于是得到了S2,6个14*14的 特征图(28/2=14)。S2这个pooling层是对C1中的2*2区域内的像素求和乘以一个权值系数再加上一个偏置,然后将这个结果再做一次映射。于是每个池化核有两个训练参数,所以共有2x6=12个训练参数,但是有5x14x14x6=5880个连接。 - C3层-卷积层
详细说明:第一次池化之后是第二次卷积,第二次卷积的输出是C3,16个10x10的特征图,卷积核大小是 5*5. 我们知道S2 有6个 14*14 的特征图,怎么从6 个特征图得到 16个特征图了? 这里是通过对S2 的特征图特殊组合计算得到的16个特征图。 - S4层-池化层(下采样层)
详细说明:S4是pooling层,窗口大小仍然是2*2,共计16个feature map,C3层的16个10x10的图分别进行以2x2为单位的池化得到16个5x5的特征图。这一层有2x16共32个训练参数,5x5x5x16=2000个连接。连接的方式与S2层类似。 - C5层-卷积层
详细说明:C5层是一个卷积层。由于S4层的16个图的大小为5x5,与卷积核的大小相同,所以卷积后形成的图的大小为1x1。这里形成120个卷积结果。每个都与上一层的16个图相连。所以共有(5x5x16+1)x120 = 48120个参数,同样有48120个连接。 - F6层-全连接层
详细说明:6层是全连接层。F6层有84个节点,对应于一个7x12的比特图,-1表示白色,1表示黑色,这样每个符号的比特图的黑白色就对应于一个编码。该层的训练参数和连接数是(120 + 1)x84=10164。 - Output层-全连接层
二、AleXNet (8层)
2.1 AlexNet介绍
AleXNet使用了ReLU方法加快训练速度,并且使用Dropout来防止过拟合,通过多GPU的训练降低训练时间。
AleXNet (8层) 是首次把卷积神经网络引入计算机视觉领域并取得突破性成绩的模型。获得了ILSVRC 2012年的冠军,再top-5项目中错误率仅仅15.3%,相对于使用传统方法的亚军26.2%的成绩优良重大突破。
和之前的LeNet相比,AlexNet通过堆叠卷积层使得模型更深更宽,同时借助GPU使得训练再可接受的时间范围内得到结果,推动了卷积神经网络甚至是深度学习的发展。
AlexNet的论文中着重解释了Tanh激活函数和ReLu激活函数的不同特点,解释了多个GPU是如何加速训练网络的,也说明了防止过拟合的一些方法。
2.2 AleXNet 网络结构
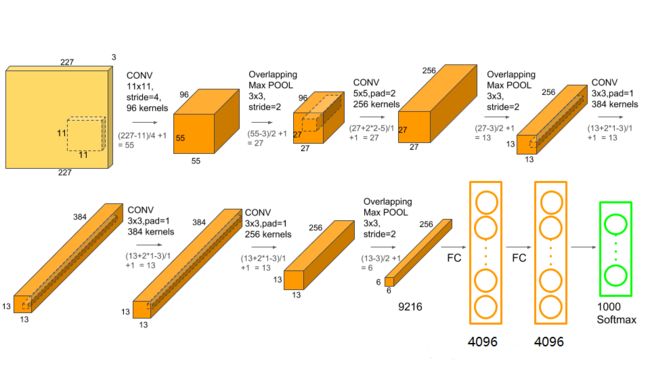
5个卷积层和3个全连接层组成的,深度总共8层的AleXNet网络。AlexNet针对的是ILSVRC2012的比赛图像,共有1000个类别。与LeNet-5不同的是,AlexNet输入的图像不再是灰度图像,而是具有RGB三个通道的彩色图片,且大小是256x256。对于不符合要求的需要重新剪裁转换。
AlexNet的网络结构:
- Input:256x256的RGB三通道图像。因此输入维度是training_numx256x256x3。
- Layer1:卷积层,96个11x11大小的卷积核扫描,步长为4。使用ReLU激活函数。采用maxpooling池化,3x3,步长为2。然后做了一次局部正规化。
- Layer2:卷积层,256个5x5的卷积核,步长为1,但是做了padding,padding长度为2。使用ReLU激活函数。采用maxpooling池化,3x3,步长为2。然后做了一次局部正规化。
- Layer3:卷积层,384个3x3的卷积核,步长为1,使用ReLU激活函数。做了padding,padding长度为1。
- Layer4:卷积层,384个3x3的卷积核,步长为1,使用ReLU激活函数。做了padding,padding长度为1。
- Layer5:卷积层,256个3x3的卷积核,步长为1,使用ReLU激活函数。做了padding,padding长度为1。采用maxpooling池化,3x3,步长为2。然后做了一次Dropout(rate=0.5)。
- Layer6:全连接层,加上ReLU激活函数,4096个神经元。然后做了一次Dropout(rate=0.5)。
- Layer7:全连接层,加上ReLU激活函数,4096个神经元。
- Layer8:全连接层,加上ReLU激活函数,1000个神经元。这一层也就是输出层了。
AlexNet总共有6230万个参数(大约),一次前馈计算需要11亿的计算。这里的卷积参数实际只有370万,只占6%左右,但是消耗了95的计算量。这个发现也使得Alex发了另一篇论文来解决这个问题。
2.3 Relu 激活函数解释
- 非饱和函数的含义是指,当自变量趋于无穷大的时候,其值也趋向无穷大。这个函数如果不是非饱和函数,那么它就是饱和函数了。例如Tanh函数的值域是[-1,1],显然不符合非饱和函数的定义,因此它就是饱和函数。
- 而ReLU函数则是非饱和函数。非饱和函数的含义是指 , 当自变量趋于无穷大的时候,其值也趋向无穷大。这个函数如果不是非饱和函数,那么它就是饱和函数了。例如Tanh函数的值域是[-1,1],显然不符合非饱和函数的定义,因此它就是饱和函数。而ReLU函数则是非饱和函数。
- ReLU激活函数的训练速度和Tanh的对比,ReLU要比Tanh块6倍。
使用Relu激活函数的原因
- Relu函数为f(x)= max(0,x)
- sigmoid与tanh有饱和区,Relu函数在x>0时导数一直是1,因为梯度的连乘表达式包括各层激活函数的导数以及各层的权重,reLU解决了激活函数的导数问题,所以有助于缓解梯度消失,也能在一定程度上解决梯度爆炸,从而加快训练速度。
- 无论是正向传播还是反向传播,计算量显著小于sigmoid和tanh。
2.4 防止过拟合
- 数据增强是计算机视觉中最常用的防止过拟合的方法。在这里主要使用了两种方法,一个是水平翻转,第二个是更改RGB通道的密集度。
- Dropout就是随机删除隐藏层中的神经元,被删除的神经元不会在本次迭代中传递值。因此,每一次迭代都有一个不太一样的网络架构,但是他们都共享权重。这种技术降低了神经元的co-adaptions的复杂性,因此某个神经元不能只依靠某些特定的神经元来计算,这强制整个网络学习更加具有鲁棒性的特征。在测试的时候不会使用Dropout。但是会把结果乘以0.5,近似模仿这种行为。如前面所述,在第5层的卷几层结束做了Dropout,在第6层的全连接层做了Dropout,所以这影响的是最开始的两个全连接层。最后一层输出没有收到影响。
Dropout大约使得收敛的迭代次数翻倍了。
三、VGG
VGG中根据卷积核大小和卷积层数目的不同,可分为A,A-LRN,B,C,D,E共6个配置(ConvNet Configuration),其中以D,E两种配置较为常用,分别称为VGG16和VGG19。
3.1 VGG 的配置
VGG有A,A-LRN,B,C,D,E6种配置
- A:是最基本的模型,8个卷基层,3个全连接层,一共11层。
- A-LRN:忽略
- B:在A的基础上,在stage1和stage2基础上分别增加了1层3X3卷积层,一共13层。
- C:在B的基础上,在stage3,stage4和stage5基础上分别增加了一层1X1的卷积层,一共16层。
- D:在B的基础上,在stage3,stage4和stage5基础上分别增加了一层3X3的卷积层,一共16层。
- E:在D的基础上,在stage3,stage4和stage5基础上分别增加了一层3X3的卷积层,一共19层。
3.2 VGG 配置比较
VGG各种配置比较
- A 与 A-LRN 比较:A-LRN 结果没有 A 好,说明 LRN 作用不大;
- A 与 B, C, D, E 比较:A 是这当中层数最少的,相比之下 A 效果不如 B,C,D,E,说明层数越深越好;
- B 与 C 比较:增加 1x1 卷积核,增加了额外的非线性提升效果;
- C与D比较:3x3 的卷积核(结构D)比 1x1(结构C)的效果好。
3.3 VGG 的block组成
VGG由Block1~block5组成

以VGG16为例
- 13个卷积层(Convolutional Layer),分别用conv3-XXX表示
- 3个全连接层(Fully connected Layer),分别用FC-XXXX表示
- 5个池化层(Pool layer),分别用maxpool表示
其中,卷积层和全连接层具有权重系数,因此也被称为权重层,总数目为13+3=16,这即是VGG16中16的来源。(池化层不涉及权重,因此不属于权重层,不被计数)。
3.4 VGG 特点相同卷积核
此处相同的卷积核仅针对 VGG-16 与 VGG-19 来分析。所有的卷积核尺寸都是 3x3 ,卷积步长为1,填充 padding 为1。
这样做的原因如下:
- 3x3 是最小的能够捕获左、右、上、下和中心概念的尺寸;
- 两个连续的 3x3 的卷积相当于 5x5 的感受野,三个相当于 7x7
使用三个 3x3 卷积而不是一个 7x7 的卷积的优势有两点:
- 包含三个 ReLU 层而不是一个,使决策函数更有判别性;
- 减少了参数。比如输入输出都是C个通道,使用 3x3 的3个卷积层需要3x(3x3xCxC)=27xCxC,使用 7x7 的1个卷积层需要7x7xCxC=49CxC)。
注:C结构中的 1x1 卷积核
1x1 卷积核主要是为了增加决策函数的非线性,而不影响卷积层的感受野。虽然 1x1 的卷积操作是线性的,但是 ReLU 增加了非线性。
四、GoogleNet 即 Inception 结构
4.1 GoogleNet介绍
GoogleNet参数为500万个 ,AlexNet参数个数是GoogleNet的12倍,VGGNet参数又是AlexNet的3倍。
GoogLeNet在2014的ImageNet分类任务上击败了VGG-Nets夺得冠军,其实力肯定是非常深厚的,GoogLeNet跟AlexNet,VGG-Nets这种单纯依靠加深网络结构进而改进网络性能的思路不一样,它另辟幽径,在加深网络的同时(22层),也在网络结构上做了创新,引入Inception结构代替了单纯的卷积+激活的传统操作(这思路最早由Network in Network提出)。GoogLeNet进一步把对卷积神经网络的研究推上新的高度。
4.2 Inception 架构解释
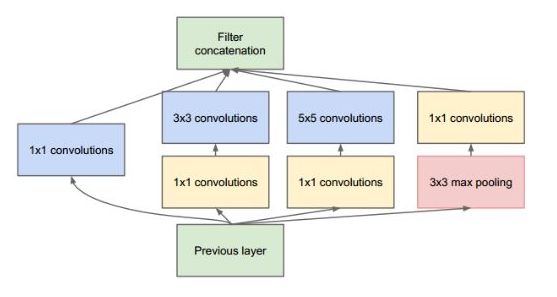
Inception网络即是Inception模块的重复拼接,其中插有额外的有池化层来改变模型的宽度和高度。 所有卷积和池化操作均使用Padding=”SAME”卷积/池化方式 。
结构就是Inception,结构里的卷积stride都是1,另外为了保持特征响应图大小一致,都用了零填充。最后每个卷积层后面都立刻接了个ReLU层。在输出前有个叫concatenate的层,直译的意思是“并置”,即把4组不同类型但大小相同的特征响应图一张张并排叠起来,形成新的特征响应图。
Inception结构里主要做了两件事:
- 通过3×3的池化、以及1×1、3×3和5×5这三种不同尺度的卷积核,一共4种方式对输入的特征响应图做了特征提取。
- 为了降低计算量。同时让信息通过更少的连接传递以达到更加稀疏的特性,采用1×1卷积核来实现降维。
4.3 inception
4.3.1 inception V1 总结
- inception V1 具有22层。包括池化层的话是 27 层,该模型在最后一个 inception 模块处使用全局平均池化。
详细:Inception V1架构详情和卷积池化概念https://blog.csdn.net/u010986753/article/details/99405667#13__23
4.3.2 inception V2 总结
- inception V2 具有 层。Inception V2最主要的贡献就是提出了batch normalization,目的主要在于加快训练速度。用两层堆叠3*3或者5*5,比起V1来说参数量少了,计算量少了,但层数增加,效果更好。
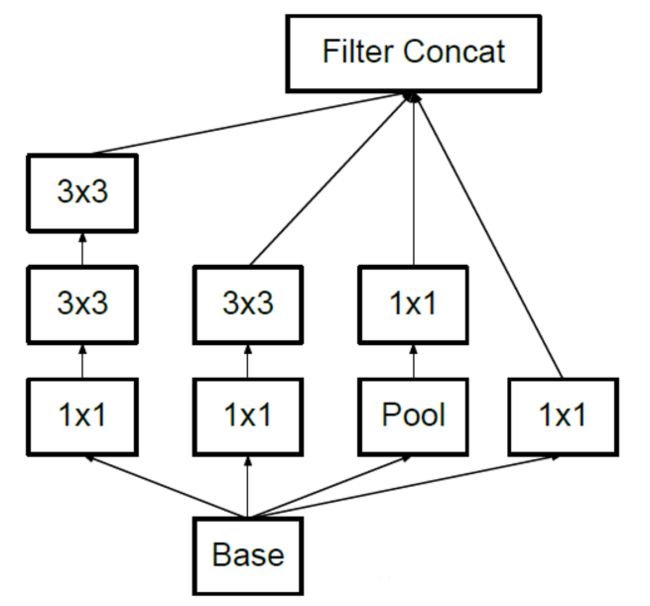
4.3.3 inception V3 总结
- inception V3 具有 层,网络结构最大的变化则是用了1n结合n1来代替n*n的卷积。

4.3.4 inception V4 总结
- inception V4 具有 层。Inception V4主要利用残差连接(Residual Connection),也就是ResNet的核心思想来改进V3结构。证明了Inception模块结合Residual Connection可以极大地加速训练,同时性能也有提升,得到一个Inception-ResNet V2网络,同时还设计了一个更深更优化的Inception v4模型,能达到与Inception-ResNet V2相媲美的性能。

4.3.5 Xception 总结
- Xception,Xception是Inception系列网络的极限版本,先进行空间的33卷积,再进行通道的11卷积
4.3.6 Inception V3 和 Xception 架构区别
- Inception V3 和 Xception 架构区别
Inception V3 是先做1*1的卷积,再做3*3的卷积,这样就先将通道进行了合并,即通道卷积,然后再进行空间卷积,
而Xception则正好相反,先进行空间的3*3卷积,再进行通道的1*1卷积
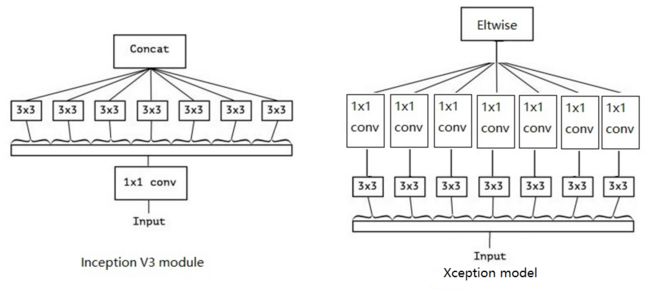
4.4 Inception 详情
详情1 Inception V1架构详情和卷积池化概念https://blog.csdn.net/u010986753/article/details/99405667#13__23
详情2 GoogLeNet (二) Inception 相关概念 https://blog.csdn.net/u010986753/article/details/99172414
详情3
GoogLeNet (一)GoogLeNet的Inception v1到v4的演进
https://blog.csdn.net/u010986753/article/details/98980390
五 ResNet 之Residual 残差网络和dentity mapping(恒等映射)
ResNet是在Inception v3和 Inception v4 之间产生的。
5.1 ResNet 介绍
2015年何恺明推出的ResNet在ISLVRC和COCO上横扫所有选手,获得冠军。ResNet在网络结构上做了大创新,而不再是简单的堆积层数,ResNet在卷积神经网络的新思路,绝对是深度学习发展历程上里程碑式的事件。
通过使用Residual Unit成功训练152层深的神经网络,在ILSVRC2015比赛中获得了冠军,top-5错误率为3.57%,同时参数量却比VGGNet低很多。
ResNet主要解决的问题,就是在深度网络中的退化的问题。在深度学习的领域中,常规网络的堆叠并不会是越深效果则越好,在超过一定深度以后,准确度开始下降,并且由于训练集的准确度也在降低,证明了不是由于过拟合的原因。
在ResNet中增加一个identity mapping(恒等映射),将原始所需要学的函数H(x)转换成F(x)+x,而作者认为这两种表达的效果相同,但是优化的难度却并不相同,作者假设F(x)的优化 会比H(x)简单的多。这一想法也是源于图像处理中的残差向量编码,通过一个reformulation,将一个问题分解成多个尺度直接的残差问题,能够很好的起到优化训练的效果。具体论文笔记在此博客论文笔记中有详细解释。
5.2 ResNet 架构特点Residual
ResNet的残差结构如下:


5.3 ResNet 和 Inception 相结合
将该结构与Inception相结合,变成下图:
通过20个类似的模块组合,Inception-ResNet构建如下:
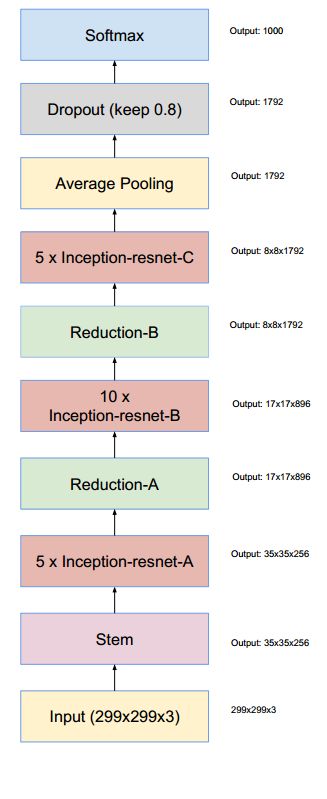
5.4 ResNeXt 是ResNet的极限版本
ResNeXt 是 ResNet 的极限版本,代表着the next dimension。ResNeXt的论文证明了增大Cardinality(即ResNeXt中module个数)比增大模型的width或者depth效果更好,与ResNet相比参数更少,效果也更好,结构简单方便设计。
六、DenseNet
6.1 DenseNet 介绍
DenseNet(Dense Convolutional Network) 主要还是和ResNet及Inception网络做对比,思想上有借鉴,但却是全新的结构,网络结构并不复杂,却非常有效,在CIFAR指标上全面超越ResNet。可以说DenseNet吸收了ResNet最精华的部分,并在此上做了更加创新的工作,使得网络性能进一步提升。
6.2 DenseNet 特点
缓解梯度消失问题,加强特征传播,鼓励特征复用,极大的减少了参数量。
DenseNet 是一种具有密集连接的卷积神经网络。在该网络中,任何两层之间都有直接的连接,也就是说,网络每一层的输入都是前面所有层输出的并集,而该层所学习的特征图也会被直接传给其后面所有层作为输入。下图是 DenseNet 的一个dense block示意图,一个block里面的结构如下,与ResNet中的BottleNeck基本一致:BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3) ,而一个DenseNet则由多个这种block组成。每个DenseBlock的之间层称为transition layers,由BN−>Conv(1×1)−>averagePooling(2×2)组成。
在同层深度下获得更好的收敛率,自然是有额外代价的。其代价之一,就是其恐怖如斯的内存占用。
6.3 DenseNet 密集连接
密集连接不会带来冗余吗?不会!密集连接这个词给人的第一感觉就是极大的增加了网络的参数量和计算量。但实际上 DenseNet 比其他网络效率更高,其关键就在于网络每层计算量的减少以及特征的重复利用。DenseNet则是让l层的输入直接影响到之后的所有层,它的输出为:xl=Hl([X0,X1,…,xl−1]),其中[x0,x1,…,xl−1]就是将之前的feature map以通道的维度进行合并。并且由于每一层都包含之前所有层的输出信息,因此其只需要很少的特征图就够了,这也是为什么DneseNet的参数量较其他模型大大减少的原因。这种dense connection相当于每一层都直接连接input和loss,因此就可以减轻梯度消失现象,这样更深网络不是问题
需要明确一点,dense connectivity 仅仅是在一个dense block里的,不同dense block 之间是没有dense connectivity的,比如下图所示。
总结
(1)Inception-V4,准确率最高,结合了ResNet和Inception;
(2)GoogLeNet,效率高,相对少的内存和参数;
(3)VGG,准确率可以,但效率低,高内存占用+多的参数;
(4)AlexNet,计算量小,但占内存且准确率低;
(5)ResNet,效率依赖于模型,准确率较高。
(6)VGG, GoogLeNet, ResNet用的最多,其中ResNet默认效果最好;
(7)设计网络注重层数、跨层连接、提高梯度流通;
'''
【干货来了|小麦苗IT资料分享】
★小麦苗DB职场干货:https://mp.weixin.qq.com/s/Vm5PqNcDcITkOr9cQg6T7w
★小麦苗数据库健康检查:https://share.weiyun.com/5lb2U2M
★小麦苗微店:https://weidian.com/s/793741433?wfr=c&ifr=shopdetail
★各种操作系统下的数据库安装文件(Linux、Windows、AIX等):链接:https://pan.baidu.com/s/19yJdUQhGz2hTgozb9ATdAw 提取码:4xpv
★小麦苗分享的资料:https://share.weiyun.com/57HUxNi
★小麦苗课堂资料:https://share.weiyun.com/5fAdN5m
★小麦苗课堂试听资料:https://share.weiyun.com/5HnQEuL
★小麦苗出版的相关书籍:https://share.weiyun.com/5sQBQpY
★小麦苗博客文章:https://share.weiyun.com/5ufi4Dx
★数据库系列(Oracle、MySQL、NoSQL):https://share.weiyun.com/5n1u8gv
★公开课录像文件:https://share.weiyun.com/5yd7ukG
★其它常用软件分享:https://share.weiyun.com/53BlaHX
★其它IT资料(OS、网络、存储等):https://share.weiyun.com/5Mn6ESi
★Python资料:https://share.weiyun.com/5iuQ2Fn
★已安装配置好的虚拟机:https://share.weiyun.com/5E8pxvT
★小麦苗腾讯课堂:https://lhr.ke.qq.com/
★小麦苗博客:http://blog.itpub.net/26736162/
'''

有趣的事,Python永远不会缺席
欢迎关注小婷儿的博客
文章内容来源于小婷儿的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解!!!
如需转发,请注明出处:小婷儿的博客python https://blog.csdn.net/u010986753
CSDN https://blog.csdn.net/u010986753
博客园 https://www.cnblogs.com/xxtalhr/
有问题请在博客下留言或加作者:
微信:tinghai87605025 联系我加微信群
QQ :87605025
QQ交流群:py_data 483766429
公众号:DB宝
证书说明
OCP证书说明连接 https://mp.weixin.qq.com/s/2cymJ4xiBPtTaHu16HkiuA
OCM证书说明连接 https://mp.weixin.qq.com/s/7-R6Cz8RcJKduVv6YlAxJA
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。重要的事多说几遍。。。。。。