CNN经典算法AlexNet介绍(论文详细解读)
本文是深度学习经典算法解读的一部分,原文发之:https://www.datalearner.com/blog/1051558603213207
来源论文:Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks.” Advances in neural information processing systems. 2012.
2012年发表的AlexNet可以算是开启本轮深度学习浪潮的开山之作了。由于AlexNet在ImageNet LSVRC-2012(Large Scale Visual Recognition Competition)赢得第一名,并且错误率只有15.3%(第二名是26.2%),引起了巨大的反响。相比较之前的深度学习网络结构,AlexNet主要的变化在于激活函数采用了Relu、使用Dropout代替正则降低过拟合等。本篇博客将根据其论文,详细讲述AlexNet的网络结构及其特点。
AlexNet的论文中着重解释了Tanh激活函数和ReLu激活函数的不同特点,解释了多个GPU是如何加速训练网络的,也说明了防止过拟合的一些方法。都是值得学习的很好的内容。
一、背景介绍
在数据量不大的情况下,目前的算法已经能很好地处理识别任务。例如,在MINST的数字识别任务中,目前算法的错误率已经低于0.3%,接近人类的水平了。但是现实世界中的对象有很大的可变性,识别这些对象需要更大的训练数据。由于LabelMe、ImageNet的发展,目前已经有数以百万的标注图像可以使用。
很大的数据集导致训练异常困难。而卷积神经网络(Convolutional Neural Networks,CNN)可以通过改变其结构而控制其大小,并且CNN符合自然界的图像识别的规律导致了其非常有效。相比较同规模的前馈神经网络,CNN的参数却小很多,而性能并不会下降。
这篇论文的主要贡献包括两点:1)训练了一个很大的CNN来处理大规模数据并取得了目前最好的成绩。2)公开了一个基于GPU优化的二维CNN。
二、AlexNet结构的特点
1.ReLu的非线性问题
激活函数Tanh是属于饱和非线性,使用梯度下降训练Tanh这种激活函数会比非饱和非线性激活函数如ReLU要慢。函数是否是饱和函数主要看定义域和值域的范围。非饱和函数的含义是指,当自变量趋于无穷大的时候,其值也趋向无穷大。这个函数如果不是非饱和函数,那么它就是饱和函数了。例如Tanh函数的值域是[-1,1],显然不符合非饱和函数的定义,因此它就是饱和函数。而ReLU函数则是非饱和函数。
下图就是ReLU激活函数的训练速度和Tanh的对比,ReLU要比Tanh快6倍。
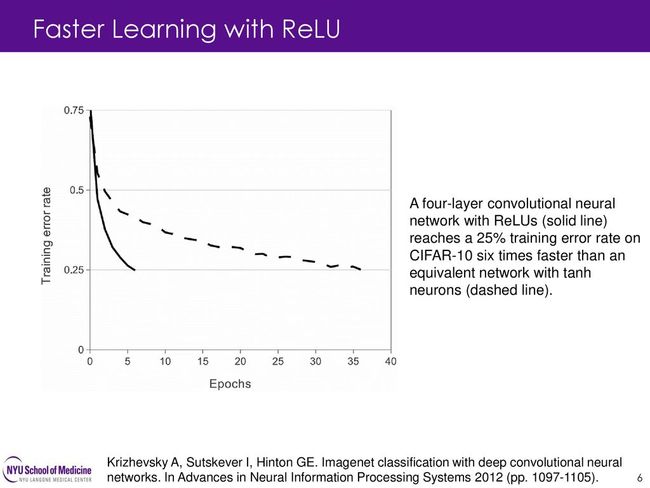
当然,作者也不是第一个考虑更换传统的激活函数,也有人曾经使用|tanh(x)|来处理Caltech-101数据集,但是他们最主要的目的是防止过拟合。而作者主要考虑的是加快训练速度,这在大的网络训练中很重要。
2.在多个GPU上训练
作者使用了两个GPU并行计算。当前的GPU可以很容易实现并行,因为GPU之间可以互相直接读取内存,而不需要通过主机内存实现。在作者实现的并行方法中,他们将一半的kernels(或者是神经元)放到一颗GPU上,但是用了一个技巧,即GPU之间的通信仅仅在某些层上。举个例子,第3层的kernel从第2层直接读取所有的kernel结果。但是第4层仅仅从相同的GPU中读取第3层的kernel。但是,在交叉验证的时候选择连接的模式可能有点问题,但是这允许我们精确调整通信量以至于达到一个适合的计算量。
3.局部响应的正规化 Local Response Normalization
ReLU有个很好的特性是它不需要输入正化来防止它变得饱和。前面说过了,不饱和的函数在梯度下降求解时速度更快。只要某些样本上能对ReLU产生正值的输入,那个神经元就可以学习(敲黑板,记住ReLU的形状)。然而,作者发现,遵从局部响应的正规化有助于泛化能力。作者提出了一种正规化方法,效果很好,但是这个方法看起来稍微有点复杂,而且和GPU编程有关,这里不详细看了。
4.Overlapping Pooling
CNN的池化层在之前用的都是不重叠的,在这里作者发现带重叠的池化层效果更好。重叠的意思就是步长小于kernel的长,这样就产生重叠了。作者观察发现:训练带有重叠池化的模型要更加难以过拟合。至于这个为啥,并没有很清晰的结论。大家可以看下面的一个讨论:
https://www.quora.com/Why-do-training-models-with-overlapping-pooling-make-it-harder-to-overfit-CNNs-in-Krizhevsky-2012
三、AlexNet模型架构
AlexNet总共有8层网络。AlexNet针对的是ILSVRC2012的比赛图像,共有1000个类别。与LeNet-5不同的是,AlexNet输入的图像不再是灰度图像,而是具有RGB三个通道的彩色图片,且大小是256x256。对于不符合要求的需要重新剪裁转换。AlexNet的每一层如下:
Input:256x256的RGB三通道图像。因此输入维度是training_numx256x256x3。
Layer1:卷积层,96个11x11大小的卷积核扫描,步长为4。使用ReLU激活函数。采用maxpooling池化,3x3,步长为2。然后做了一次局部正规化。
Layer2:卷积层,256个5x5的卷积核,步长为1,但是做了padding,padding长度为2。使用ReLU激活函数。采用maxpooling池化,3x3,步长为2。然后做了一次局部正规化。
Layer3:卷积层,384个3x3的卷积核,步长为1,使用ReLU激活函数。做了padding,padding长度为1。
Layer4:卷积层,384个3x3的卷积核,步长为1,使用ReLU激活函数。做了padding,padding长度为1。
Layer5:卷积层,256个3x3的卷积核,步长为1,使用ReLU激活函数。做了padding,padding长度为1。采用maxpooling池化,3x3,步长为2。然后做了一次Dropout(rate=0.5)。
Layer6:全连接层,加上ReLU激活函数,4096个神经元。然后做了一次Dropout(rate=0.5)。
Layer7:全连接层,加上ReLU激活函数,4096个神经元。
Layer8:全连接层,加上ReLU激活函数,1000个神经元。这一层也就是输出层了。
AlexNet总共有6230万个参数(大约),一次前馈计算需要11亿的计算。这里的卷积参数实际只有370万,只占6%左右,但是消耗了95的计算量。这个发现也使得Alex发了另一篇论文来解决这个问题。
参考:https://medium.com/@smallfishbigsea/a-walk-through-of-alexnet-6cbd137a5637
四、防止过拟合
如前所述,AlexNet有六千多万个参数,过拟合是很可能发生的事情。为了防止过拟合,Alex做了如下工作。
1.数据增强
数据增强是计算机视觉中最常用的防止过拟合的方法。作者在这里主要使用了两种方法,一个是水平翻转,第二个是更改RGB通道的密集度。
2.丢弃法Dropout
Dropout就是随机删除隐藏层中的神经元,被删除的神经元不会在本次迭代中传递值。因此,每一次迭代都有一个不太一样的网络架构,但是他们都共享权重。这种技术降低了神经元的co-adaptions的复杂性,因此某个神经元不能只依靠某些特定的神经元来计算,这强制整个网络学习更加具有鲁棒性的特征。在测试的时候不会使用Dropout。但是会把结果乘以0.5,近似模仿这种行为。如前面所述,在第5层的卷几层结束做了Dropout,在第6层的全连接层做了Dropout,所以这影响的是最开始的两个全连接层。最后一层输出没有收到影响。
Dropout大约使得收敛的迭代次数翻倍了。这要记住。
五、AlexNet网络特点及问题
作者使用了ReLU方法加快训练速度,并且使用Dropout来防止过拟合,通过多GPU的训练降低训练时间,尽管这些都不是作者自己提出的技巧,但是,作者的工作引起来大家的广泛关注,使得很多人开始利用GPU来训练大型的CNN网络。当然,作者提出的局部响应正规化也在后来被证明没啥效果(看VGG的论文)。但不管如何,这篇论文引起了很多人对深度学习和GPU训练的重视,也算是非常有影响的工作了。
六、代码实现
PyTorch最简单:https://github.com/pytorch/vision/blob/master/torchvision/models/alexnet.py
预训练的模型:
https://github.com/onnx/models/tree/master/bvlc_alexnet