Pytorch搭建CNN(重复元素的网络VGG)实现cifar-10分类:20轮近74%准确率
参考书目:动手学深度学习(pytorch版)原书链接
import torch
from torch import nn
from torch.nn import init
import torchvision
import torchvision.transforms as transforms
import sys
import d2lzh_pytorch as d2l
import time
trainset = torchvision.datasets.CIFAR10(root="D:/pythonlearning",train=True,transform=transforms.Compose([
transforms.Resize([32,32]),
transforms.ToTensor(),
#transforms.Normalize(mean=[0.485,0.456,0.406],
# std=[0.229,0.224,0.225]),
]))
testset = torchvision.datasets.CIFAR10(root="D:/pythonlearning",train=False,transform=transforms.Compose([
transforms.Resize([32,32]),
transforms.ToTensor(),
#transforms.Normalize(mean=[0.485,0.456,0.406],
# std=[0.229,0.224,0.225]),
]))
batch_size=128
trainloader = torch.utils.data.DataLoader(dataset=trainset,batch_size=batch_size,shuffle=True)
testloader = torch.utils.data.DataLoader(dataset=testset,batch_size=batch_size,shuffle=True)
lr = 0.003
num_epochs = 20
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv = nn.Sequential(
#32-3+2+1-->32
nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
#32-3+2+1-->32
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
#32/2-->16
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
#16-3+2+1-->16
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
#16/2-->8
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
#8-3+2+1-->8
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
#8/2-->4
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
)
self.fc = nn.Sequential(
nn.Linear(256*4*4, 256),
nn.ReLU(),
nn.Dropout(0.5),#丢弃法
nn.Linear(256, 256),
nn.ReLU(),
nn.Linear(256,84),
nn.ReLU(),
nn.Linear(84, 10)
)
def forward(self, x):
feature = self.conv(x)
output = self.fc(feature.view(x.shape[0],-1))
return output
net = Net()
#print(net)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)#Adam算法优化
d2l.train_ch5(net, trainloader, testloader, batch_size,optimizer, device, num_epochs)#训练模型
CNN网络模型:

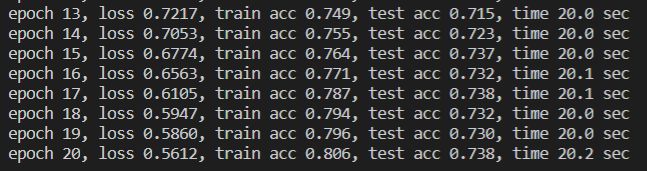
运行部分结果:
贴上训练模型代码(d2l包中):
# 该函数已保存在d2lzh_pytorch包中
def evaluate_accuracy(data_iter, net, device=None):
if device is None and isinstance(net, torch.nn.Module):
# 如果没指定device就使用net的device
device = list(net.parameters())[0].device
acc_sum, n = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
if isinstance(net, torch.nn.Module):
net.eval() # 评估模式, 这会关闭dropout
acc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()
net.train() # 改回训练模式
else: # 自定义的模型, 3.13节之后不会用到, 不考虑GPU
if('is_training' in net.__code__.co_varnames): # 如果有is_training这个参数
# 将is_training设置成False
acc_sum += (net(X, is_training=False).argmax(dim=1) == y).float().sum().item()
else:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
# 该函数已保存在d2lzh_pytorch包中
def train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs):
net = net.to(device)
print("training on ", device)
loss = torch.nn.CrossEntropyLoss()
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, batch_count, start = 0.0, 0.0, 0, 0, time.time()
for X, y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec'
% (epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))