【深度学习】VGGNet解读及代码实现
这篇文章不仅仅关注于VGGNet的网络结构,重点在于分析VGGNet设计者当时的出发点,以及能带给我们什么启发。
简介
VGGNet由牛津大学的视觉几何组(Visual Geometry Group)提出,获得了2014年ILSVRC竞赛的分类任务第二名和定位任务第一名,主要贡献在于证明了使用3x3小卷积核,增加网络深度可以有效提升模型性能,并且对于其他数据集也有很好的泛化性能。
论文链接:Very deep convolutional networks for large-scale image recognition
网络结构
论文中一共提供了6种网络配置,层数从浅到深分别为11层、13层、16层和19层。其中11层时,主要比较了Local Response Normalisation(LRN)的作用,结果是LRN并没有提升网络性能。除了网络结构的变化,VGGNet从原理上和传统的CNN模型并没有太大区别,都是采用同样的训练Pipeline。
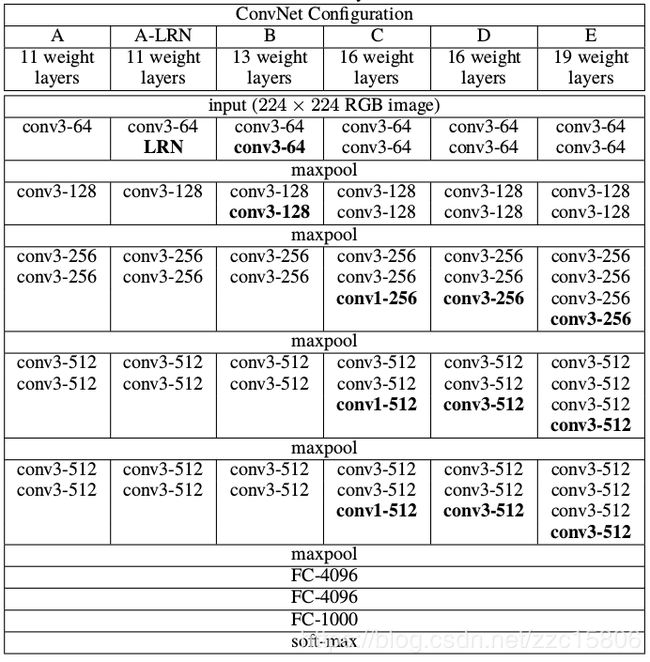
主要贡献
1. 使用3x3小卷积核。首先我们先了解这样一个知识:两个3x3卷积堆叠在一起(中间没有池化层)的感受野相当于一个5x5的卷积,三个3x3卷积堆叠在一起的感受野相当于一个7x7的卷积。为了更形象的理解这一点,我们看下图,两个3x3堆叠在一起的效果,

以7x7卷积为例,为什么要采用三个3x3卷积,而不直接使用一个7x7卷积呢?主要有两个好处:
1)三个卷积可以进行三次非线性变换,而这种非线性变换能有效提升不同信息的判别性(差异);
2)减小网络参数量。假设卷积层的通道数为C,则三个3x3卷积参数量:![]() ,一个7x7卷积参数量:
,一个7x7卷积参数量:![]()
2. 增加网络深度。增加网络深度的好处就是能够增加网络的非线性映射次数,使得网络能够提取具有更好的判决信息的特征,从而提升网络性能。因为使用了3x3卷积,使得网络参数量并不会随着网络的深度增加而急剧上升。除此之外,VGGNet还使用了1x1卷积,目的也是增加非线性映射次数。
代码实现
本文使用Keras构建VGG13模型。
from keras.layers import Input
from keras.layers import Conv2D, MaxPool2D, Dense, Flatten, Dropout
from keras.models import Model
from keras import optimizers
from keras.utils import plot_model
def vgg13(input_shape=(224,224,3), nclass=1000):
"""
build vgg13 model using keras with TensorFlow backend.
:param input_shape: input shape of network, default as (224,224,3)
:param nclass: numbers of class(output shape of network), default as 1000
:return: vgg13 model
"""
input_ = Input(shape=input_shape)
x = Conv2D(64, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')(input_)
x = Conv2D(64, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')(x)
x = MaxPool2D(pool_size=(2, 2), strides=(2, 2), padding='same')(x)
x = Conv2D(128, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')(x)
x = Conv2D(128, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')(x)
x = MaxPool2D(pool_size=(2, 2), strides=(2, 2), padding='same')(x)
x = Conv2D(256, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')(x)
x = Conv2D(256, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')(x)
x = MaxPool2D(pool_size=(2, 2), strides=(2, 2), padding='same')(x)
x = Conv2D(512, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')(x)
x = Conv2D(512, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')(x)
x = MaxPool2D(pool_size=(2, 2), strides=(2, 2), padding='same')(x)
x = Conv2D(512, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')(x)
x = Conv2D(512, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')(x)
x = MaxPool2D(pool_size=(2, 2), strides=(2, 2), padding='same')(x)
x = Flatten()(x)
x = Dense(4096, activation='relu')(x)
x = Dropout(0.5)(x)
x = Dense(4096, activation='relu')(x)
x = Dropout(0.5)(x)
output_ = Dense(nclass, activation='softmax')(x)
model = Model(inputs=input_, outputs=output_)
model.summary()
opti_sgd = optimizers.sgd(lr=0.01, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=opti_sgd, metrics=['accuracy'])
return model
if __name__ == '__main__':
model = vgg13()
plot_model(model, 'vgg13.png') # 保存模型图顺便提一下,当我们在使用VGGNet时,不必要拘泥于文中提出来6中网络结构,卷积核数量、尺寸,全连接层的神经元数量以及要不要使用池化层都可根据我们具体的任务进行修改。我们使用的是VGG的思想。