神经网络设计_学习规则总结
学习规则,就修改神经网络的权值和偏置值的过程和方法,其目的是为了训练网络来完成某些工作。
学习规则主要有3种类型:有监督学习、无监督学习和增强学习。
1,有监督学习
根据输入和目标输出(注意区分目标输出和实际输出!)来调整权值和偏置值。
2,无监督学习
仅仅根据网络的输入调整网络的权值和偏值,没有目标输出。
3,感知机学习规则_有监督学习

4,Hebb学习规则_无监督学习
线性联想器:

Hebb假设:若一条突触两侧的两个神经元同时被激活,那么突触的强度将会增大!
Hebb假设的数学解析:如果一个正的输入 产生一个正的输出
产生一个正的输出 ,那么应该增加
,那么应该增加 的值,如下式表示:
的值,如下式表示:

或则写成矩阵的形式:

说明: 是一个称为学习速率的正常数;
是一个称为学习速率的正常数; 是输出向量中的第i个元素;
是输出向量中的第i个元素;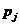 是输入向量的第j个元素。
是输入向量的第j个元素。
由于权值只是根据输入向量和输出向量来调整,与目标无关,因此这个规则是属于无监督的学习规则!
5,Hebb学习规则_有监督学习
将无监督的Hebb学习规则中的实际输出 替换为目标输出
替换为目标输出 ,并且令学习速度为0,则得到有监督的Hebb学习规则:
,并且令学习速度为0,则得到有监督的Hebb学习规则:

将上式用矩阵的形式表示为:

使用说明:利用这个规则来求权值矩阵时,要求将输入向量标准化(向量长度为1)!
6,仿逆规则

说明:这个规则是Hebb有监督学习规则的模仿版!使用 来模仿
来模仿 的逆
的逆 ,因此叫做仿逆。
,因此叫做仿逆。
使用说明:利用这个规则求权值矩阵,不用将输入向量标准化!
7,Hebb学习的变形_过滤学习

说明: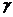 为小于1的正常数。如果趋于零,那么学习规则趋近于标准规则;如果趋近于1,那么学习规则将很快忘记旧的输入,而仅记忆最近的输入模式。这可以避免权值矩阵无限的增大。
为小于1的正常数。如果趋于零,那么学习规则趋近于标准规则;如果趋近于1,那么学习规则将很快忘记旧的输入,而仅记忆最近的输入模式。这可以避免权值矩阵无限的增大。
8,Hebb学习的变形_增量学习——Widrow-Hoff算法

说明:增量规则调整权值以使均方误差最小,因而它与仿逆规则得到的结果相同,仿逆规则使误差平方和最小化。
优点:每输入一个模式,它就能更新一次权值,而仿逆规则要等待所有输入/输出模式已知后才能计算一次权值。这中顺序的权值更新方法使得增量规则能适应变化的环境。
9,无监督Hebb学习规则Matlab实现
根据4的公式,可以编写Matlab实现代码如下:
- clear all
- clc
- %6输入,1输出,每行的第1个元素为目标,第2~7个元素为输入
- Ai=[1,1 0 1 1 1 0;
- 1,0 1 0 1 1 1;
- 1,1 1 1 1 0 0;
- 0,0 0 1 0 0 1;
- 0,1 0 0 1 0 0;
- 0,0 0 0 0 0 0];
- Iter=0; %实际迭代次数
- a=1; %学习速率
- MaxIter=3; %最大迭代次数
- Counter=0; %正确输出个数
- [m n]=size(Ai);
- b=0; % 偏置值
- W=ones(1, n-1)*0.1; %权值向量,初始化为0
- t=Ai(:,1); %正确结果,即是目标输出!
- A=Ai(:,2:n); %训练样本 ,每行为一个输入向量!
- y=zeros(1,m); %输出结果
- Stop=0;
- while ~Stop&&Iter
- for i=1:6
- x=A(i,:);
- net=W*x'+b;%根据权值和偏置值计算纯输入
- y(i)=net;
- %如果输出等于目标输出,则Counter加1,否则清零!
- Counter=(Counter+1)*(abs(y(i)-t(i))<0.0001);
- %如果实际输出都等于目标输出了,就可以停止了!
- if(Counter==m)
- Stop=1;
- break;
- %如果不能停止,就根据学习规则来调整权值和偏置值!
- else
- r=y(i);
- end
- W=W+a*r*x; %修改权值与阈值
- b=b+a*r;
- Iter=Iter+1;
- end
- end
- %输出结果
- fprintf(1,'迭代次数:');
- Iter
- fprintf(1,'权值:');
- W
- fprintf(1,'目标:');
- t=Ai(:,1)'
- fprintf(1,'输出:');
- y
运行结果:
迭代次数:
Iter = 6
权值:
W = 50.1000 8.5000 25.1000 51.7000 2.1000 19.5000
目标:
t = 1 1 1 0 0 0
输出:
y = 0.4000 1.6000 6.8000 17.8000 42.8000 69.4000
修改最大迭代次数:MaxIter=100,再次运行:
迭代次数:
Iter = 102
权值:
W =1.0e+46 *
5.4217 0.9041 2.7061 5.5918 0.2146 2.0978
目标:
t = 1 1 1 0 0 0
输出:
y = 1.0e+46 *
0.0444 0.1699 0.7328 1.9247 4.6361 7.5310
结论:
对比目标和结果,可以知道W的调整是不对的!对比两次的输出结果可以发现,当迭代次数增加时,W的值也会变大。经过测试发现,W会随着迭代次数的增加而趋向于无穷大!这是我们不愿看到的!
将 W=W+a*r*x改为W=W+a*t(i)*x,将b=b+a*t(i)改为b=b+a*r,即可将无监督学习改为有监督学习。经测试发现,结果还是不行!
10,有监督Hebb学习规则Matlab实现
根据5的公式,可以编程如下:
- clear
- clc
- %目标向量,每1列为一个目标
- T=[1 1;
- -1 1;
- 0 0];
- %输入向量,每1列为一个输入,它们是标准正交向量!
- P=[0.5 0.5
- -0.5 0.5
- 0.5 -0.5
- -0.5 -0.5];
- [m,n]=size(P);
- [m2,n2]=size(T);
- W=zeros(n, m); %权值向量,初始化为0
- y=zeros(m2,1); %输出结果
- %根据Hebb规则公式计算W
- W=T*P';
- %验证W的准确性
- y=W*P(:,2);
- %输出结果
- fprintf(1,'权值:');
- W
- fprintf(1,'输出:');
- y
输出结果:
权值:
W =
1 0 0 -1
0 1 -1 0
0 0 0 0
输出:
y =
1
1
0
对比输入结果和目标,发现结果是正确的!
参考资料
《神经网络设计》,机械工业出版社
Hebb学习规则http://baike.baidu.com/link?url=86us8PwMP-5muzobELOw7PynaRJM8gMWx31VvmfQYUBZ_hYPOtf0Mkn6BWdt62jZwMcoddc_8keEGbZ66WvYPq
learnhhttp://baike.baidu.com/link?url=86us8PwMP-5muzobELOw7PynaRJM8gMWx31VvmfQYUBZ_hYPOtf0Mkn6BWdt62jZwMcoddc_8keEGbZ66WvYPq