常见损失函数小结
摘要
本文主要总结一下常见的损失函数,包括:MSE均方误差损失函数、SVM合页损失函数、Cross Entropy交叉熵损失函数、目标检测中常用的Smooth L1损失函数。
其中还会涉及到梯度消失、梯度爆炸等问题:MSE均方误差+Sigmoid激活函数会导致学习缓慢;Smooth L1损失是为了解决梯度爆炸问题。仅供参考。
一、均方误差损失(Mean Squared Error,MSE)
1、均方误差损失定义:
均方差损失函数常用在最小二乘法中。它的思想是使得各个训练点到最优拟合线的距离最小(平方和最小)。均方差损失函数也是我们最常见的损失函数了,相信大很熟悉了,我们用神经网络中激活函数的形式表达一下,定义如下:
其中, :x是输入、w和b是网络的参数、 是激活函数。
2、MSE均方误差+Sigmoid激活函数:输出层神经元学习率缓慢
(1)Sigmoid激活函数:
这个激活函数再熟悉不过了,该函数能将负无穷到正无穷的数映射到0和1之间。先来看一下表达式以及函数图像:

Sigmoid的导数推导以及图像:
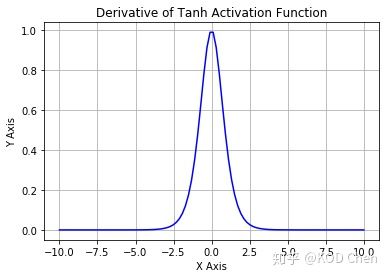
从sigmiod的导数图像中可以看到,除了中间比较小的区域,其他区域的十分值接近于0。
神经网络的反向传播是逐层对函数偏导相乘,因此当神经网络层数非常深的时候,最后一层产生的偏差(网络输出和标签之间的偏差)因为乘了很多的小于1的数而越来越小,最终就会变为0,从而导致层数比较浅的权重w没有更新,即梯度消失。可以看出,sigmoid函数作为激活函数本身就存在梯度消失的问题。
(2)MSE均方误差+Sigmoid激活函数:输出层神经元学习率缓慢
先以一个故事来进入主题:“我们大多数人不喜欢被指出错误。在开始学习弹奏钢琴不久后,我在⼀个听众前做了首秀。我很紧张,开始时将八度音阶的曲段演奏得很低。我很困惑,因为不能继续演奏下去了,直到有个人指出了其中的错误。当时,我非常尴尬。不过,尽管不开心,我们却能够因为明显的犯错快速地学习到正确的东西。你应该相信下次我再演奏肯定会是正确的!相反,在我们的错误不是很好地定义的时候,学习的过程会变得更加缓慢。”理想地,我们也希望和期待神经网络可以从错误中快速地学习。
我们以一个神经元,MSE均方误差损失 ,Sigmoid激活函数 (其中 )为例,计算一下最后一层的反向传播过程,可得:
可以看到最后一层反向传播时,所求的梯度中都含有 。经过上面的分析,当神经元输出接近1时候,Sigmoid的导数 变很小,这样 、 很小,这就导致了MSE均方误差+Sigmoid激活函数使得神经网络反向传播的起始位置——输出层神经元学习率缓慢。
→想要解决这个问题,需要引入接下来介绍的交叉熵损失函数。这里先给出结论:交叉熵损失+Sigmoid激活函数可以解决输出层神经元学习率缓慢的问题,但是不能解决隐藏层神经元学习率缓慢的问题。具体的推导和总结在下面部分中介绍。
二、交叉熵损失(Cross Entropy,CE)
多用于分类的损失函数。
1、交叉熵损失定义:
交叉熵损失的计算分为两个部分。
(1)softmax多分类器:
交叉熵损失是基于softmax计算来的,softmax将网络最后输出z通过指数转变成概率形式。首先看一下softmax计算公式:
其中, 分子 是要计算的类别 的网络输出的指数;分母是所有类别网络输出的指数和,共k个类别。这样就得到了类别i的输出概率 。
→这里说点题外话,实际上,softmax是由逻辑斯的回归模型(用于二分类)推广得到的多项逻辑斯蒂回归模型(用于多分类)。具体可以参考李航大神的《统计学方法》第六章,这里给一个大致的过程。

(2)交叉熵损失:
公式定义如下:
其中, 是类别 的真实标签;是上面softmax计算出的类别 的概率值;k是类别数,N是样本总数。
→这里看一个计算交叉熵损失的小例子:
假设共有三个类别cat、dog、bird,那么一张cat的图片标签应该为 。并且训练过程中,这张cat的图片经过网络后得到三个类别网络的输出分别为3、1、-3。那么经过softmax可以得到对应的概率值,如下图:
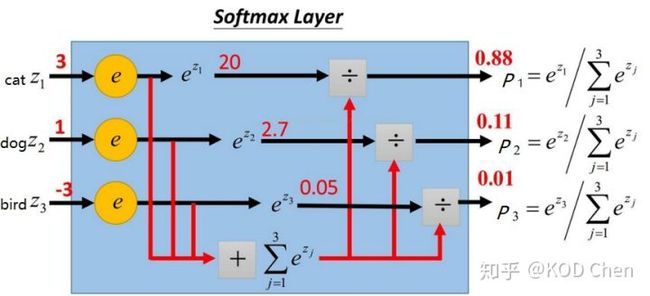
则该图片的交叉熵损失为:
(默认 )
2、关于交叉熵损失两个部分的图像:
这里想通过分析一下函数图像,加入自己的一点理解。
(1)指数图像:
softmax分类器将各个类别的“得分”(网络输出)转变成概率值。并取e指数使得“得分”高的类别对应的概率更大,使得损失函数对网络输出“更敏感”,更有利于分类。

(2)对数图像:
网络输出转化为概率后,范围必然是0-1,又取负对数得到最后的损失值。根据下面的负对数图像,这样做扩大低概率高损失、高概率低损失的差距,同样使得损失函数对网络输出“更敏感”,更有利于分类。

3、交叉熵损失+Sigmoid激活函数:
(1)推导:
接着上一部分留下的问题,我们仍然以Sigmoid激活函数 (其中 )为例。这次我们引入交叉熵损失,并以二分类为例,那么s损失函数公式为:
其中,
那么可以计算一下最后一层的反向传播过程,可得:
根据之前的推导已知 ,那么上式可以化简为:
同理得:
可以看到sigmoid的导数被约掉,这样最后一层的梯度中就没有。然而这只是输出层的推导,如果变成隐藏层的梯度sigmoid的导数不会被约掉,仍然存在。所以交叉熵损失+Sigmoid激活函数可以解决输出层神经元学习率缓慢的问题,但是不能解决隐藏层神经元学习率缓慢的问题。
(2)小结梯度消失问题:
其实损失函数包含两个部分:①计算方法(均方差、交叉熵等)②激活函数。
而之前我们遇到的是均方差损失+sigmoid激活函数造成了输出层神经元学习率缓慢,其实我们破坏任意一个条件都有可能解决这个问题:
①均方误差损失→交叉熵损失;
②sigmoid函数→不会造成梯度消失的函数,例如ReLU函数,不仅能解决输出层学习率缓慢,还能解决隐藏层学习率缓慢问题。
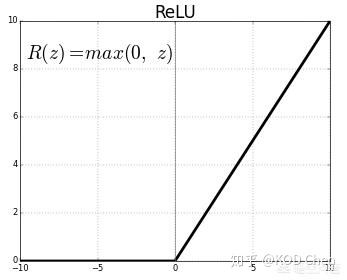
→这里也小结一下ReLU函数相对于tanh和sigmoid函数好在哪里:
·第一,采用sigmoid等函数,算激活函数是(指数运算),计算量大;反向传播求误差梯度时,求导涉及除法,计算量相对大。而采用Relu激活函数,整个过程的计算量节省很多。
·第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0),这种情况会造成信息丢失,梯度消失在网络层数多的时候尤其明显,从而无法完成深层网络的训练。
·第三,ReLU会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
三、SVM合页损失
1、定义:
合页损失函数想让正确分类的“得分”比其他错误分类的“得分”高出至少一个边界值。
如果正确分类的得分与错误分类的得分差值比边界值还要高,就会认为损失值是0;如果没有
就要计算损失了。看一下计算公式和示意图:
其中, 是正确分类的得分、 是其他错误分类的得分; 是指想要正确类别的分类得分比其他错误分类类别的得分要高且至少高出 的边界值;k是类别数(对应other错误类别数),N是样本总数。
示意图如下:

→这里看一个计算合页损失的小例子:
仍然假设共有三个类别cat、dog、bird,那么一张cat的图片标签应该为 。并且训练过程中,这张cat的图片经过网络后得到三个类别网络的输出分别为3、1、-3。我们取 。此时: 。
其实直观上也很好理解,分类正确的得分是3,其他错误类别得分是1和-3,而我们希望分类正确的得分比其他分类错误的得分高 的边界值。显然错误分类得分为1的没有符合条件,则计算损失。
2、合页损失的特点:
(1)本质:
合页损失函数其实就是线性支持向量机中,对于一些线性不可分的数据,引入了松弛变量 。这样,目标函数和约束条件就变成了:

整理一下就是:
其中前面的就是合页损失函数。后面的 是正则项。
线性支持向量机也是希望不仅仅可以求出分类超平面,同时也希望正确分类比其他错误分类多出一个边界值,即分类间隔,SVM目的也就是最大化分类间隔。而引入的 松弛因子其实就是计算的合页损失项。
(2)缺点:
尽管合页损失函数希望正确分类的得分比其他错误分类的得分高出至少一个边界值 ,但是
对于得分数字的细节是不关心的,看一个小例子:
如果两个分类器最后得分是[3,-10, -10]和[3,-2, -2],且 ,那么对于合页损失来讲没什么不同,只要满足超过边界值5,那么损失值就都等于0。然而,显然第一个分类器比第二个分类器效果更好,因为高出边界更大,但是合页损失都是0,这就是合页损失对于得分数字的细节是不关心的造成的缺点。
想要解决这一问题,其实上面的交叉熵损失很好的解决这一问题,因为交叉熵将得分转变成概率,就不会造成上面说的情况;并且交叉熵损失也扩大了正确分类和错误分类得分的差距,对分数敏感,同样能得到较好的分类效果。
(其实应该把合页损失放在交叉熵损失前面介绍,更有递进效果,但是因为要介绍交叉熵引入解决输出层神经元学习率缓慢问题,只能这样了- -、)
四、Smooth L1损失
Smooth L1损失是为了解决梯度爆炸问题的。在看Smooth L1损失之前,先看一下梯度爆炸。
1、梯度爆炸:
在深层神经网络或循环神经网络中,误差的梯度可在更新中累积相乘。如果网络层之间的梯度值大于 1.0,那么重复相乘会导致梯度呈指数级增长,梯度变的非常大,然后导致网络权重的大幅更新,并因此使网络变得不稳定。
梯度爆炸会伴随一些细微的信号,如:
①模型不稳定,导致更新过程中的损失出现显著变化;
②训练过程中,在极端情况下,权重的值变得非常大,以至于溢出,导致模型损失变成 NaN等等。
2、Smooth L1损失:
Smooth L1损失函数是在Fast R-CNN中被提出,主要目的是为了防止梯度爆炸。
对于目标检测中的回归问题,最初大多采用均方误差损失 ,这样反向传播对w或者b求导时仍存在 。那么当预测值和目标值相差很大时,就容易造成梯度爆炸。
所以我们将 这种均方误差形式,转变成 这种形式,其中:
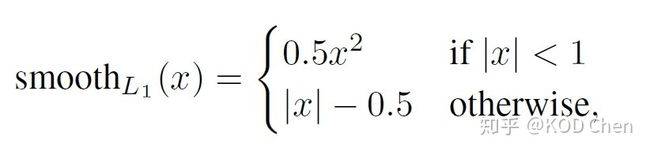
通过上式可以看出:
①当 时,即预测值和目标值相差小于1,不易造成梯度爆炸,此时还原成均方误差损失形式并给一个0.5的平滑系数,即 ;
②当 时,即预测值和目标值相差大于等于1,易造成梯度爆炸,此时降低损失次幂数,变成 ,这时候反向传播求导时候就不存在 这一项了,从而防止了梯度爆炸。
→这里最后再给出解决梯度爆炸的一些其他方法:
(1)减少学习率(个人理解梯度爆炸是模型训练发散的一种情况);
(2)使用ReLU函数,使得梯度稳定;
(3)使用正则化,即检查网络中权重的大小,对较大的权重进行惩罚,限制了梯度爆炸造成的权重变得很大的情况。